ニュース / News
ニュースリリース
約1720億パラメータ(GPT-3級)の大規模言語モデルのフルスクラッチ学習を行い、プレビュー版「LLM-jp-3 172B beta1」を公開
~学習データを含めすべてオープンにしたモデルとしては世界最大〜
大学共同利用機関法人 情報・システム研究機構 国立情報学研究所 (NII、所長:黒橋 禎夫、東京都千代田区) の大規模言語モデル研究開発センター(LLMC)は、主宰するLLM勉強会(LLM-jp)の成果として、これまでのデータ活用社会創成プラットフォームmdx(*1)での130億パラメータ・モデルの学習、国立研究開発法人産業技術総合研究所の第2回大規模言語モデル構築支援プログラムによるAI橋渡しクラウド(ABCI)での1750億パラメータ・モデルの学習トライアルの成果を踏まえ、パラメータ数(*2)約1720億(GPT-3級)の大規模言語モデル(LLM)のフルスクラッチ学習を行い、プレビュー版「LLM-jp-3 172B beta1」を公開しました。学習データを含めすべてオープンにしたモデルとしては世界最大のものです。
このプレビュー版は、用意した学習データ(約2.1兆トークン)の約1/3までの学習を行った段階のものです。今後も学習を継続し、約2.1兆トークンの学習を行ったモデルを2024年12月頃に公開する計画です。
LLMCでは、先に公開したものも含めこれらのモデルを活用してLLMの透明性・信頼性の確保に向けた研究開発を進めていきます。
1. 今回公開したLLMの概要
(1)利用計算資源
- 経済産業省・NEDOのGENIACプロジェクトの支援によるクラウド計算資源(グーグル・クラウド・ジャパン)を利用して、約0.4兆トークンまでの事前学習を実施
- その後、文部科学省の補助金により調達したクラウド計算資源(さくらインターネット)を利用して、約0.7兆トークンまでの事前学習及びチューニングを実施
(2)モデル学習用コーパス(*3)
- 以下に示すコーパス(約2.1兆トークン)を用意し、その約1/3まで事前学習を完了
- 日本語:約5,920億トークン
- WebアーカイブCommon Crawl(CC)全量から抽出・フィルタリングした日本語テキスト
- 国立国会図書館インターネット資料収集保存事業(WARP)で収集されたWebサイトのURL(当該URLリストは同館から提供)を基にクロールしたデータ
- 日本語Wikipedia
- KAKEN (科学研究費助成事業データベース) における各研究課題の概要テキスト
- 英語:約9,500億トークン(Dolma等)
- 他言語:約10億トークン(中国語・韓国語)
- プログラムコード:約1,140億トークン
- 以上の約1.7兆トークンに加え、日本語コーパスのうち約0.4兆トークンは2回学習することとし、合計約2.1兆トークン
- 日本語:約5,920億トークン
(3)モデル
- パラメータ数:約1,720億個(172B)
- モデルアーキテクチャ:LlaMA-2ベース
(4)チューニング
- 日本語インストラクションデータおよび英語インストラクションデータの和訳データ13種類を用いてチューニングを実施
(5)評価
- LLM-jpが開発している、既存の日本語言語資源に基づく22種類の評価データを用いて横断的な評価を行うフレームワーク「llm-jp-eval v1.3.1」を使用。今回公開する0.7兆トークン学習時点の事前学習モデルは0.548を達成。
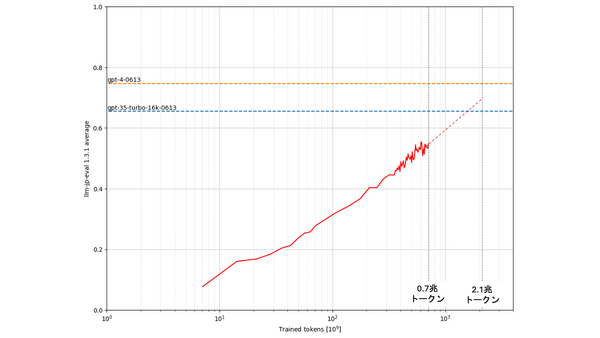
- GENIAC事業にて性能評価に用いられるフレームワーク「llm-leaderboard (g-leaderboardブランチ)」による評価を実施。今回公開する0.7兆トークン学習時点のチューニングモデルは0.529を達成。
(6)開発モデル・ツール・コーパスの公開URL
- https://llm-jp.nii.ac.jp/release
- 注:今回公開するモデルは、安全性の観点に基づくチューニングを行ったものではありますが、まだプレビュー段階のものであり、そのまま実用的なサービスに供することを想定しているものではありません。プレビュー版は利用申請者に限定的なライセンスのもと提供します。
2.今後の予定
- LLMを社会で利活用していく上ではLLMの透明性・信頼性の確保が必要であり、モデルの高度化に伴い、安全性の配慮もより重要となります。そのため、NIIは、文部科学省の補助事業「生成AIモデルの透明性・信頼性の確保に向けた研究開発拠点形成」(https://www.mext.go.jp/content/20240118-ope_dev03-000033586-11.pdfのp.7)の支援を受け2024年4月に大規模言語モデル研究開発センターを設置しました。
今回公開したモデルや、今後構築するモデルを活用してそれらの研究を進め、LLM研究開発の促進に貢献します。 - なお、今回のモデルでは最終チェックポイント(100kステップ)以外に、そこに至るまでの1kステップごとの全てのチェックポイントのデータも保存しています。今後、それらのデータも提供する予定です。
(参考1) LLM勉強会(LLM-jp)の概要
- NIIが主宰するLLM-jpでは、自然言語処理及び計算機システムの研究者を中心として、大学・企業等から1,700名以上(2024年9月17日現在)が集まり、ハイブリッド会議、オンライン会議、Slack等を活用してLLMの研究開発について情報共有を行うとともに、共同でLLM構築等の研究開発を行っています。具体的には、以下の目的で活動しています。
- オープンかつ日本語に強いLLMの構築とそれに関連する研究開発の推進
- 上記に関心のある自然言語処理および関連分野の研究者によるモデル構築の知見や最近の研究の発展についての定期的な情報交換
- データ・計算資源等の共有を前提とした組織横断的な研究者間の連携の促進
- モデル・ツール・技術資料等の成果物の公開
- 「コーパス構築WG」「モデル構築WG」「チューニング・評価WG」「安全性WG」「マルチモーダルWG」「実環境インタラクションWG」等を設置し、それぞれ、早稲田大学 河原大輔教授、東北大学 鈴木潤教授、東京大学 宮尾祐介教授、国立情報学研究所 関根聡特任教授、東京工業大学 岡崎直観教授、早稲田大学 尾形哲也教授を中心に研究開発活動に取り組んでいます。このほか、東京大学 田浦健次朗教授、空閑洋平准教授(計算資源の利用技術)、東京工業大学 横田理央教授(並列計算手法等)等、多数の方々の貢献により、活動を進めています。
- 詳細については、ホームページ https://llm-jp.nii.ac.jp/ をご参照ください。
(参考2)
この成果は、国立研究開発法人新エネルギー・産業技術総合開発機構(NEDO)の助成事業及び文部科学省の補助事業の結果得られたものです。
関連リンク
- 大規模言語モデル研究開発センター
- LLM-jpのご紹介 - YouTube
- GENIAC - 経済産業省
- データ活用社会創成プラットフォーム mdx
- 130億パラメータの大規模言語モデル「LLM-jp-13B」を構築~NII主宰LLM勉強会(LLM-jp)の初期の成果をアカデミアや産業界の研究開発に資するために公開~ - NIIニュースリリース(2023/10/20)
- 国立情報学研究所に「大規模言語モデル研究開発センター」新設 ~国産LLMを構築し、生成AIモデルの透明性・信頼性を確保する研究開発を加速〜 - NIIニュースリリース(2024/04/01)
- 大規模言語モデル「LLM-jp-13B v2.0」を構築 ~NII主宰LLM勉強会(LLM-jp)が「LLM-jp-13B」の 後続モデルとその構築に使用した全リソースを公開~(2024/04/30)
News Release: PDF
2025年度
2025/07/17
NII情報
2025/07/16
採用情報
2025/07/07
受賞
2025/07/04
NII情報
2025/07/02
NII情報
2025/06/27
研究
2025/06/24
NII情報
2025/06/17
NII情報
2025/06/12
受賞
2025/06/09
NII情報
2025/06/06
ニュースリリース
2025/06/05
受賞
2025/06/02
NII情報
2025/05/29
NII情報
2025/05/27
NII情報
2025/05/22
採用情報
2025/05/22
採用情報
2025/05/21
NII情報
2025/05/21
NII情報
2025/05/12
ニュースリリース
2025/04/25
事業
2025/04/24
ニュースリリース
2025/04/21
事業
2025/04/15
受賞
2025/04/08
受賞
2025/04/08
ニュースリリース
2025/04/08
ニュースリリース
2025/04/08
NII情報
2025/04/03
受賞
2025/04/01
ニュースリリース
2025/04/01
NII情報
2025/04/01
NII情報
2024年度
2025/03/25
募集
2025/03/24
NII情報
2025/03/24
NII情報
2025/03/18
NII情報
2025/03/17
採用情報
2025/03/14
NII情報
2025/03/11
ニュースリリース
2025/03/04
NII情報
2025/02/19
ニュースリリース
2025/02/07
NII情報
2025/01/23
NII情報
2025/01/23
NII情報
2025/01/22
受賞
2025/01/20
NII情報
2025/01/20
NII情報
2025/01/16
受賞
2025/01/15
NII情報
2025/01/14
受賞
2025/01/08
採用情報
2025/01/07
NII情報
2025/01/06
採用情報
2025/01/06
採用情報
2024/12/26
NII情報
2024/12/25
NII情報
2024/12/25
NII情報
2024/12/24
ニュースリリース
2024/12/18
受賞
2024/12/17
NII情報
2024/12/16
NII情報
2024/12/05
受賞
2024/12/05
NII情報
2024/12/04
受賞
2024/11/28
ニュースリリース
2024/11/28
NII情報
2024/11/28
NII情報
2024/11/25
NII情報
2024/11/15
研究
2024/11/15
NII情報
2024/11/13
NII情報
2024/11/06
NII情報
2024/11/03
受賞
2024/11/01
ニュースリリース
2024/11/01
NII情報
2024/10/24
NII情報
2024/10/23
NII情報
2024/10/22
NII情報
2024/10/22
NII情報
2024/10/21
ニュースリリース
2024/10/18
NII情報
2024/10/16
ニュースリリース
2024/10/08
NII情報
2024/10/07
採用情報
2024/10/02
受賞
2024/10/01
募集
2024/09/26
受賞
2024/09/17
ニュースリリース
2024/09/17
NII情報
2024/09/17
NII情報
2024/09/11
受賞
2024/09/11
NII情報
2024/09/05
受賞
2024/09/02
ニュースリリース
2024/08/30
NII情報
2024/08/29
NII情報
2024/08/23
NII情報
2024/08/23
NII情報
2024/08/23
NII情報
2024/08/20
NII情報
2024/08/20
NII情報
2024/08/16
NII情報
2024/08/15
受賞
2024/08/15
受賞
2024/08/06
受賞
2024/08/05
NII情報
2024/08/02
受賞
2024/08/01
NII情報
2024/07/25
NII情報
2024/07/18
ニュースリリース
2024/07/17
ニュースリリース
2024/07/03
事業
2024/07/03
受賞
2024/06/24
NII情報
2024/06/20
NII情報
2024/06/13
ニュースリリース
2024/06/12
NII情報
2024/06/11
NII情報
2024/06/10
受賞
2024/06/03
受賞
2024/05/30
ニュースリリース
2024/05/28
NII情報
2024/05/28
受賞
2024/05/27
NII情報
2024/05/24
NII情報
2024/05/23
ニュースリリース
2024/05/22
ニュースリリース
2024/04/30
ニュースリリース
2024/04/24
NII情報
2024/04/22
ニュースリリース
2024/04/18
ニュースリリース
2024/04/16
事業
2024/04/15
NII情報
2024/04/15
NII情報
2024/04/10
ニュースリリース
2024/04/09
ニュースリリース
2024/04/05
NII情報
2024/04/04
NII情報
2024/04/01
ニュースリリース
2024/04/01
ニュースリリース
2024/04/01
NII情報
2023年度
2024/03/28
ニュースリリース
2024/03/28
NII情報
2024/03/27
ニュースリリース
2024/03/22
NII情報
2024/03/18
ニュースリリース
2024/03/18
募集
2024/03/15
NII情報
2024/03/15
受賞
2024/03/15
採用情報
2024/03/05
受賞
2024/03/05
受賞
2024/03/04
ニュースリリース
2024/03/01
ニュースリリース
2024/02/29
ニュースリリース
2024/02/28
NII情報
2024/02/22
受賞
2024/02/14
NII情報
2024/02/07
事業
2024/02/06
受賞
2024/02/02
受賞
2024/02/02
NII情報
2024/01/30
ニュースリリース
2024/01/24
NII情報
2024/01/19
ニュースリリース
2024/01/19
NII情報
2024/01/17
NII情報
2024/01/17
NII情報
2024/01/09
NII情報
2023/12/26
NII情報
2023/12/18
ニュースリリース
2023/12/15
NII情報
2023/12/14
NII情報
2023/12/11
NII情報
2023/12/08
NII情報
2023/12/08
NII情報
2023/12/07
ニュースリリース
2023/12/07
受賞
2023/11/30
NII情報
2023/11/28
受賞
2023/11/27
ニュースリリース
2023/11/22
NII情報
2023/11/21
NII情報
2023/11/07
受賞
2023/11/07
NII情報
2023/10/31
NII情報
2023/10/30
ニュースリリース
2023/10/23
ニュースリリース
2023/10/20
ニュースリリース
2023/10/18
ニュースリリース
2023/10/18
事業
2023/10/17
NII情報
2023/10/13
NII情報
2023/10/03
NII情報
2023/10/02
募集
2023/09/27
受賞
2023/09/15
NII情報
2023/09/13
受賞
2023/09/11
NII情報
2023/09/01
NII情報
2023/08/24
NII情報
2023/08/21
NII情報
2023/07/31
受賞
2023/07/23
受賞
2023/07/21
受賞
2023/07/13
受賞
2023/07/01
受賞
2023/06/26
NII情報
2023/06/23
NII情報
2023/06/22
NII情報
2023/06/12
ニュースリリース
2023/06/12
重要なお知らせ
2023/06/08
受賞
2023/06/08
NII情報
2023/06/01
NII情報
2023/05/30
NII情報
2023/05/24
ニュースリリース
2023/05/23
ニュースリリース
2023/05/15
ニュースリリース
2023/05/15
NII情報
2023/05/14
受賞
2023/05/11
NII情報
2023/05/08
受賞
2023/05/02
ニュースリリース
2023/05/02
NII情報
2023/04/12
NII情報
2023/04/11
NII情報
2023/04/10
募集
2023/04/07
ニュースリリース
2023/04/03
NII情報
2023/04/01
NII情報
2022年度
2023/03/31
NII情報
2023/03/30
ニュースリリース
2023/03/29
ニュースリリース
2023/03/25
NII情報
2023/03/24
NII情報
2023/03/22
受賞
2023/03/20
NII情報
2023/03/17
ニュースリリース
2023/03/15
NII情報
2023/03/06
NII情報
2023/03/01
受賞
2023/02/14
NII情報
2023/01/30
受賞
2023/01/23
ニュースリリース
2023/01/13
ニュースリリース
2023/01/10
受賞
2023/01/10
ニュースリリース
2023/01/05
NII情報
2022/12/23
ニュースリリース
2022/12/20
受賞
2022/12/13
NII情報
2022/12/08
受賞
2022/12/02
NII情報
2022/11/25
受賞
2022/11/25
受賞
2022/11/24
ニュースリリース
2022/11/22
NII情報
2022/11/21
受賞
2022/11/12
受賞
2022/11/10
受賞
2022/11/08
受賞
2022/11/08
ニュースリリース
2022/11/01
ニュースリリース
2022/10/31
ニュースリリース
2022/10/26
受賞
2022/10/26
ニュースリリース
2022/10/13
NII情報
2022/10/13
NII情報
2022/10/13
NII情報
2022/10/13
NII情報
2022/10/13
NII情報
2022/10/03
募集
2022/09/27
NII情報
2022/09/22
NII情報
2022/09/15
ニュースリリース
2022/09/15
NII情報
2022/09/06
受賞
2022/09/06
NII情報
2022/09/02
受賞
2022/09/02
受賞
2022/08/31
ニュースリリース
2022/08/24
受賞
2022/08/18
お知らせ
2022/08/18
ニュースリリース
2022/08/12
ニュースリリース
2022/08/04
お知らせ
2022/07/29
NII情報
2022/07/28
NII情報
2022/07/27
ニュースリリース
2022/07/27
受賞
2022/07/26
NII情報
2022/07/07
NII情報
2022/07/07
ニュースリリース
2022/06/22
NII情報
2022/06/15
受賞
2022/06/09
NII情報
2022/06/01
NII情報
2022/05/24
ニュースリリース
2022/05/24
受賞
2022/05/17
NII情報
2022/05/17
ニュースリリース
2022/05/16
ニュースリリース
2022/05/15
受賞
2022/05/13
ニュースリリース
2022/05/06
NII情報
2022/04/26
受賞
2022/04/18
ニュースリリース
2022/04/15
NII情報
2022/04/12
NII情報
2022/04/12
募集
2022/04/08
受賞
2022/04/08
ニュースリリース
2022/04/01
ニュースリリース
2021年度
2022/03/29
NII情報
2022/03/17
NII情報
2022/03/15
ニュースリリース
2022/03/14
受賞
2022/03/10
NII情報
2022/03/02
受賞
2022/02/28
ニュースリリース
2022/02/21
NII情報
2022/02/21
受賞
2022/02/21
受賞
2022/02/21
受賞
2022/02/14
ニュースリリース
2022/02/10
お知らせ
2022/02/09
お知らせ
2022/02/08
お知らせ
2022/02/07
お知らせ
2022/02/02
お知らせ
2022/01/31
NII情報
2022/01/28
受賞
2022/01/28
NII情報
2022/01/20
NII情報
2022/01/14
お知らせ
2022/01/14
ニュースリリース
2021/12/24
受賞
2021/12/24
受賞
2021/12/22
お知らせ
2021/12/13
NII情報
2021/12/08
受賞
2021/12/06
NII情報
2021/11/29
募集
2021/11/25
受賞
2021/11/24
ニュースリリース
2021/11/17
ニュースリリース
2021/11/15
ニュースリリース
2021/11/15
NII情報
2021/11/13
受賞
2021/11/04
ニュースリリース
2021/11/03
受賞
2021/11/01
受賞
2021/11/01
受賞
2021/11/01
NII情報
2021/11/01
受賞
2021/10/27
受賞
2021/10/27
NII情報
2021/10/27
受賞
2021/10/21
NII情報
2021/10/20
NII情報
2021/10/20
ニュースリリース
2021/10/12
受賞
2021/10/10
NII情報
2021/10/06
NII情報
2021/10/01
募集
2021/09/27
NII情報
2021/09/22
ニュースリリース
2021/09/17
受賞
2021/09/09
受賞
2021/09/01
NII情報
2021/08/30
NII情報
2021/08/24
NII情報
2021/08/06
お知らせ
2021/08/04
お知らせ
2021/08/03
受賞
2021/07/28
NII情報
2021/07/22
受賞
2021/07/16
ニュースリリース
2021/07/13
ニュースリリース
2021/07/12
NII情報
2021/07/01
ニュースリリース
2021/06/21
受賞
2021/06/21
受賞
2021/06/17
ニュースリリース
2021/06/17
NII情報
2021/06/16
ニュースリリース
2021/06/15
受賞
2021/06/08
受賞
2021/06/01
NII情報
2021/05/31
ニュースリリース
2021/05/26
ニュースリリース
2021/05/25
ニュースリリース
2021/05/06
NII情報
2021/04/30
受賞
2021/04/27
ニュースリリース
2021/04/13
ニュースリリース
2021/04/12
ニュースリリース
2021/04/09
NII情報
2021/04/08
お知らせ
2021/04/07
NII情報
2020年度
2021/03/25
NII情報
2021/03/25
NII情報
2021/03/23
ニュースリリース
2021/03/22
NII情報
2021/03/22
NII情報
2021/03/18
NII情報
2021/03/15
NII情報
2021/03/12
NII情報
2021/03/09
ニュースリリース
2021/03/09
お知らせ
2021/03/06
受賞
2021/03/05
受賞
2021/02/22
NII情報
2021/02/19
ニュースリリース
2021/02/16
受賞
2021/02/15
受賞
2021/02/15
ニュースリリース
2021/02/10
NII情報
2021/02/03
NII情報
2021/01/29
ニュースリリース
2021/01/26
NII情報
2021/01/22
ニュースリリース
2021/01/15
NII情報
2021/01/14
NII情報
2021/01/13
NII情報
2021/01/13
NII情報
2021/01/12
受賞
2021/01/08
NII情報
2020/12/25
NII情報
2020/12/25
受賞
2020/12/23
NII情報
2020/12/18
受賞
2020/12/17
受賞
2020/12/15
ニュースリリース
2020/12/14
受賞
2020/12/11
ニュースリリース
2020/12/10
NII情報
2020/12/07
NII情報
2020/12/03
NII情報
2020/12/02
NII情報
2020/12/02
NII情報
2020/12/02
NII情報
2020/11/25
ニュースリリース
2020/11/25
受賞
2020/11/16
NII情報
2020/11/15
受賞
2020/11/12
ニュースリリース
2020/11/06
ニュースリリース
2020/11/05
NII情報
2020/11/04
NII情報
2020/11/01
受賞
2020/10/30
NII情報
2020/10/27
NII情報
2020/10/21
NII情報
2020/10/20
NII情報
2020/10/17
ニュースリリース
2020/10/13
NII情報
2020/10/13
NII情報
2020/10/08
受賞
2020/10/05
NII情報
2020/10/05
ニュースリリース
2020/10/01
NII情報
2020/09/28
ニュースリリース
2020/09/24
受賞
2020/09/17
NII情報
2020/09/12
受賞
2020/09/11
NII情報
2020/09/07
受賞
2020/08/27
NII情報
2020/08/26
NII情報
2020/08/18
NII情報
2020/08/07
NII情報
2020/08/06
受賞
2020/07/31
受賞
2020/07/23
受賞
2020/07/22
NII情報
2020/07/16
NII情報
2020/07/14
NII情報
2020/07/14
NII情報
2020/07/13
ニュースリリース
2020/07/10
NII情報
2020/07/08
NII情報
2020/07/01
NII情報
2020/06/29
NII情報
2020/06/25
受賞
2020/06/19
NII情報
2020/06/10
お知らせ
2020/06/10
ニュースリリース
2020/06/03
お知らせ
2020/05/28
ニュースリリース
2020/05/23
受賞
2020/05/21
NII情報
2020/05/20
お知らせ
2020/05/16
受賞
2020/05/11
お知らせ
2020/05/06
お知らせ
2020/04/30
ニュースリリース
2020/04/29
お知らせ
2020/04/24
ニュースリリース
2020/04/23
NII情報
2020/04/21
お知らせ
2020/04/21
お知らせ
2020/04/17
受賞
2020/04/15
お知らせ
2020/04/08
重要なお知らせ
2020/04/07
ニュースリリース
2020/04/07
ニュースリリース
2020/04/07
ニュースリリース
2020/04/07
お知らせ
2020/04/06
ニュースリリース
2020/04/03
お知らせ
2020/04/01
お知らせ
2020/04/01
ニュースリリース
2019年度
2020/03/30
お知らせ
2020/03/25
重要なお知らせ
2020/03/23
ニュースリリース
2020/03/17
受賞
2020/03/11
ニュースリリース
2020/03/10
NII情報
2020/03/06
受賞
2020/03/06
NII情報
2020/03/05
ニュースリリース
2020/03/05
受賞
2020/02/26
受賞
2020/02/25
ニュースリリース
2020/02/25
NII情報
2020/02/12
ニュースリリース
2020/02/06
NII情報
2020/01/28
NII情報
2020/01/28
ニュースリリース
2020/01/27
NII情報
2020/01/24
ニュースリリース
2020/01/14
募集
2020/01/08
NII情報
2019/12/27
受賞
2019/12/27
NII情報
2019/12/26
NII情報
2019/12/25
ニュースリリース
2019/12/13
NII情報
2019/12/06
ニュースリリース
2019/12/06
NII情報
2019/12/04
受賞
2019/11/29
ニュースリリース
2019/11/29
受賞
2019/11/26
ニュースリリース
2019/11/21
NII情報
2019/11/18
ニュースリリース
2019/11/12
受賞
2019/10/30
受賞
2019/10/30
受賞
2019/10/30
受賞
2019/10/29
ニュースリリース
2019/10/24
NII情報
2019/10/21
NII情報
2019/10/11
ニュースリリース
2019/10/09
NII情報
2019/10/02
受賞
2019/10/02
ニュースリリース
2019/10/01
受賞
2019/10/01
受賞
2019/10/01
NII情報
2019/09/27
NII情報
2019/09/25
受賞
2019/09/24
受賞
2019/09/24
受賞
2019/09/22
受賞
2019/09/22
受賞
2019/09/20
NII情報
2019/09/13
ニュースリリース
2019/09/02
NII情報
2019/09/02
NII情報
2019/09/02
NII情報
2019/08/28
受賞
2019/08/20
受賞
2019/08/20
NII情報
2019/08/09
NII情報
2019/08/08
NII情報
2019/08/07
受賞
2019/08/02
受賞
2019/07/12
NII情報
2019/07/11
受賞
2019/07/11
受賞
2019/07/10
ニュースリリース
2019/07/08
NII情報
2019/07/05
お知らせ
2019/07/04
受賞
2019/06/27
受賞
2019/06/24
ニュースリリース
2019/06/21
受賞
2019/06/20
受賞
2019/06/20
NII情報
2019/06/06
受賞
2019/06/06
NII情報
2019/06/06
ニュースリリース
2019/06/03
受賞
2019/05/27
NII情報
2019/05/25
ニュースリリース
2019/05/24
NII情報
2019/05/21
NII情報
2019/05/20
NII情報
2019/05/09
受賞
2019/05/09
NII情報
2019/05/08
NII情報
2019/05/06
受賞
2019/04/26
ニュースリリース
2019/04/25
NII情報
2019/04/22
ニュースリリース
2019/04/22
NII情報
2019/04/19
受賞
2019/04/18
NII情報
2019/04/17
NII情報
2019/04/17
NII情報
2019/04/16
NII情報
2019/04/16
ニュースリリース
2019/04/12
NII情報
2019/04/10
受賞
2019/04/09
NII情報
2019/04/09
ニュースリリース
2019/04/09
ニュースリリース
2019/04/08
ニュースリリース
2019/04/04
ニュースリリース
2018年度
2019/03/27
ニュースリリース
2019/03/20
受賞
2019/03/20
NII情報
2019/03/15
受賞
2019/03/15
受賞
2019/03/13
ニュースリリース
2019/03/09
受賞
2019/03/01
ニュースリリース
2019/02/16
受賞
2019/01/31
受賞
2019/01/28
受賞
2019/01/21
NII情報
2019/01/15
お知らせ
2018/12/28
NII情報
2018/12/27
NII情報
2018/12/25
ニュースリリース
2018/12/21
受賞
2018/12/20
ニュースリリース
2018/12/14
お知らせ
2018/12/14
お知らせ
2018/12/13
受賞
2018/12/13
受賞
2018/12/11
ニュースリリース
2018/12/10
NII情報
2018/12/05
NII情報
2018/12/04
ニュースリリース
2018/12/03
NII情報
2018/11/27
ニュースリリース
2018/11/27
NII情報
2018/11/26
NII情報
2018/11/14
受賞
2018/11/14
受賞
2018/11/14
受賞
2018/11/13
受賞
2018/11/09
受賞
2018/11/07
受賞
2018/11/06
ニュースリリース
2018/11/06
NII情報
2018/11/02
NII情報
2018/10/23
お知らせ
2018/10/22
NII情報
2018/10/15
NII情報
2018/10/12
ニュースリリース
2018/10/11
受賞
2018/10/05
NII情報
2018/10/04
ニュースリリース
2018/10/02
NII情報
2018/10/02
NII情報
2018/10/01
ニュースリリース
2018/09/20
NII情報
2018/09/20
ニュースリリース
2018/09/20
NII情報
2018/09/18
受賞
2018/09/15
受賞
2018/09/11
お知らせ
2018/09/07
ニュースリリース
2018/09/03
NII情報
2018/09/03
NII情報
2018/08/30
受賞
2018/08/27
NII情報
2018/08/27
NII情報
2018/08/27
受賞
2018/07/25
受賞
2018/07/24
受賞
2018/07/16
受賞
2018/07/12
NII情報
2018/07/03
受賞
2018/06/29
NII情報
2018/06/29
お知らせ
2018/06/28
ニュースリリース
2018/06/25
NII情報
2018/06/25
NII情報
2018/06/25
受賞
2018/06/25
受賞
2018/06/22
受賞
2018/06/18
ニュースリリース
2018/06/05
NII情報
2018/05/23
NII情報
2018/05/20
受賞
2018/05/16
ニュースリリース
2018/05/14
NII情報
2018/04/21
受賞
2018/04/20
NII情報
2018/04/17
NII情報
2018/04/16
NII情報
2018/04/16
NII情報
2018/04/13
NII情報
2018/04/13
ニュースリリース
2018/04/12
NII情報
2018/04/12
ニュースリリース
2018/04/10
ニュースリリース
2018/04/05
NII情報
2018/04/02
ニュースリリース
2017年度
2018/03/30
NII情報
2018/03/30
NII情報
2018/03/23
ニュースリリース
2018/03/23
受賞
2018/03/16
ニュースリリース
2018/03/15
NII情報
2018/03/13
受賞
2018/03/13
受賞
2018/03/06
受賞
2018/03/01
ニュースリリース
2018/02/17
受賞
2018/01/23
ニュースリリース
2018/01/18
ニュースリリース
2017/12/26
ニュースリリース
2017/12/25
ニュースリリース
2017/12/25
ニュースリリース
2017/12/23
受賞
2017/12/21
NII情報
2017/12/14
ニュースリリース
2017/12/12
NII情報
2017/12/06
NII情報
2017/12/06
受賞
2017/11/30
受賞
2017/11/28
お知らせ
2017/11/27
ニュースリリース
2017/11/22
ニュースリリース
2017/11/22
受賞
2017/11/22
お知らせ
2017/11/20
ニュースリリース
2017/11/16
NII情報
2017/11/15
NII情報
2017/11/14
受賞
2017/11/07
NII情報
2017/11/07
ニュースリリース
2017/11/06
ニュースリリース
2017/11/03
受賞
2017/10/27
ニュースリリース
2017/10/26
ニュースリリース
2017/10/26
受賞
2017/10/19
受賞
2017/10/17
NII情報
2017/10/17
受賞
2017/10/11
受賞
2017/10/02
NII情報
2017/10/02
NII情報
2017/09/28
NII情報
2017/09/28
NII情報
2017/09/28
ニュースリリース
2017/09/27
NII情報
2017/09/20
NII情報
2017/09/19
受賞
2017/09/18
受賞
2017/09/15
受賞
2017/09/12
ニュースリリース
2017/09/04
お知らせ
2017/08/31
NII情報
2017/08/31
NII情報
2017/08/29
お知らせ
2017/08/20
受賞
2017/08/18
ニュースリリース
2017/08/09
ニュースリリース
2017/08/09
受賞
2017/08/02
受賞
2017/08/01
ニュースリリース
2017/07/30
受賞
2017/07/30
受賞
2017/07/26
受賞
2017/07/26
NII情報
2017/07/19
NII情報
2017/07/11
受賞
2017/07/10
NII情報
2017/07/10
受賞
2017/07/08
受賞
2017/07/05
受賞
2017/07/03
ニュースリリース
2017/06/30
NII情報
2017/06/28
ニュースリリース
2017/06/22
ニュースリリース
2017/06/12
ニュースリリース
2017/06/08
ニュースリリース
2017/06/08
ニュースリリース
2017/06/08
受賞
2017/06/05
NII情報
2017/06/05
ニュースリリース
2017/06/05
ニュースリリース
2017/06/02
ニュースリリース
2017/06/02
ニュースリリース
2017/06/01
ニュースリリース
2017/05/29
お知らせ
2017/05/23
ニュースリリース
2017/05/16
受賞
2017/05/10
ニュースリリース
2017/04/26
受賞
2017/04/26
受賞
2017/04/26
受賞
2017/04/11
ニュースリリース
2017/04/11
ニュースリリース
2017/04/10
お知らせ
2017/04/07
お知らせ
2017/04/07
お知らせ
2017/04/06
ニュースリリース
2017/04/05
お知らせ
2017/04/05
お知らせ
2017/04/03
ニュースリリース
2016年度
2017/03/30
ニュースリリース
2017/03/24
受賞
2017/03/24
お知らせ
2017/03/24
受賞
2017/03/23
お知らせ
2017/03/17
ニュースリリース
2017/03/16
受賞
2017/03/16
受賞
2017/03/16
ニュースリリース
2017/03/14
ニュースリリース
2017/03/09
受賞
2017/03/07
お知らせ
2017/03/06
ニュースリリース
2017/02/27
ニュースリリース
2017/02/27
ニュースリリース
2017/02/24
受賞
2017/02/21
ニュースリリース
2017/02/16
お知らせ
2017/02/14
お知らせ
2017/02/08
ニュースリリース
2017/02/02
お知らせ
2017/02/02
お知らせ
2017/01/31
受賞
2017/01/26
お知らせ
2017/01/24
ニュースリリース
2017/01/19
お知らせ
2017/01/19
ニュースリリース
2016/12/27
ニュースリリース
2016/12/27
お知らせ
2016/12/19
お知らせ
2016/12/16
お知らせ
2016/12/16
お知らせ
2016/12/15
受賞
2016/12/15
受賞
2016/12/12
受賞
2016/12/12
受賞
2016/12/08
受賞
2016/12/06
ニュースリリース
2016/12/01
受賞
2016/12/01
受賞
2016/11/30
ニュースリリース
2016/11/29
受賞
2016/11/29
ニュースリリース
2016/11/24
お知らせ
2016/11/24
ニュースリリース
2016/11/23
受賞
2016/11/22
ニュースリリース
2016/11/21
ニュースリリース
2016/11/17
お知らせ
2016/11/17
ニュースリリース
2016/11/14
ニュースリリース
2016/11/14
ニュースリリース
2016/11/14
ニュースリリース
2016/11/11
ニュースリリース
2016/11/10
受賞
2016/11/10
ニュースリリース
2016/11/09
受賞
2016/11/08
お知らせ
2016/11/04
お知らせ
2016/11/04
受賞
2016/11/04
受賞
2016/11/02
ニュースリリース
2016/10/31
ニュースリリース
2016/10/30
受賞
2016/10/28
受賞
2016/10/21
ニュースリリース
2016/10/05
ニュースリリース
2016/10/03
ニュースリリース
2016/09/29
ニュースリリース
2016/09/27
ニュースリリース
2016/09/26
ニュースリリース
2016/09/21
受賞
2016/09/21
受賞
2016/09/21
ニュースリリース
2016/09/20
受賞
2016/09/20
ニュースリリース
2016/09/17
受賞
2016/09/15
お知らせ
2016/09/14
受賞
2016/09/12
受賞
2016/09/09
受賞
2016/09/07
ニュースリリース
2016/08/31
ニュースリリース
2016/08/18
受賞
2016/08/09
お知らせ
2016/07/27
ニュースリリース
2016/07/26
ニュースリリース
2016/07/21
お知らせ
2016/07/12
受賞
2016/07/12
受賞
2016/07/11
ニュースリリース
2016/07/05
お知らせ
2016/06/30
お知らせ
2016/06/24
受賞
2016/06/24
受賞
2016/06/24
受賞
2016/06/21
ニュースリリース
2016/06/09
ニュースリリース
2016/06/04
お知らせ
2016/06/03
受賞
2016/06/03
受賞
2016/06/03
受賞
2016/06/02
受賞
2016/06/01
受賞
2016/06/01
お知らせ
2016/06/01
ニュースリリース
2016/05/25
ニュースリリース
2016/05/25
ニュースリリース
2016/05/25
ニュースリリース
2016/05/24
ニュースリリース
2016/05/17
受賞
2016/05/17
受賞
2016/05/17
受賞
2016/05/17
ニュースリリース
2016/05/17
ニュースリリース
2016/05/09
ニュースリリース
2016/04/26
ニュースリリース
2016/04/21
お知らせ
2016/04/19
お知らせ
2016/04/06
お知らせ
2016/04/01
受賞
2016/04/01
お知らせ
2016/04/01
ニュースリリース
2015年度
2016/03/31
お知らせ
2016/03/29
お知らせ
2016/03/25
ニュースリリース
2016/03/24
受賞
2016/03/24
受賞
2016/03/24
受賞
2016/03/15
受賞
2016/03/08
お知らせ
2016/03/01
受賞
2016/02/29
ニュースリリース
2016/02/19
ニュースリリース
2016/02/16
ニュースリリース
2016/02/15
受賞
2016/02/15
ニュースリリース
2016/02/15
ニュースリリース
2016/02/09
ニュースリリース
2016/01/30
受賞
2016/01/22
受賞
2016/01/21
お知らせ
2016/01/21
お知らせ
2016/01/12
お知らせ
2016/01/05
お知らせ
2015/12/25
お知らせ
2015/12/10
ニュースリリース
2015/12/09
受賞
2015/12/02
お知らせ
2015/11/20
受賞
2015/11/20
受賞
2015/11/17
ニュースリリース
2015/11/14
ニュースリリース
2015/11/14
ニュースリリース
2015/11/14
ニュースリリース
2015/11/12
お知らせ
2015/11/11
お知らせ
2015/11/09
お知らせ
2015/11/06
お知らせ
2015/11/06
受賞
2015/11/04
ニュースリリース
2015/10/30
受賞
2015/10/30
ニュースリリース
2015/10/28
受賞
2015/10/27
受賞
2015/10/21
受賞
2015/10/16
受賞
2015/10/01
受賞
2015/09/30
お知らせ
2015/09/17
受賞
2015/09/09
お知らせ
2015/09/09
受賞
2015/09/09
お知らせ
2015/09/09
お知らせ
2015/09/02
ニュースリリース
2015/08/27
お知らせ
2015/08/11
お知らせ
2015/08/10
ニュースリリース
2015/08/06
ニュースリリース
2015/07/31
受賞
2015/07/31
受賞
2015/07/29
お知らせ
2015/07/28
受賞
2015/07/22
受賞
2015/07/21
受賞
2015/07/17
ニュースリリース
2015/07/12
受賞
2015/07/10
受賞
2015/07/10
受賞
2015/07/02
お知らせ
2015/06/24
ニュースリリース
2015/06/23
受賞
2015/06/19
受賞
2015/06/15
ニュースリリース
2015/06/12
受賞
2015/06/08
ニュースリリース
2015/06/05
お知らせ
2015/06/04
ニュースリリース
2015/06/04
ニュースリリース
2015/05/28
ニュースリリース
2015/05/20
受賞
2015/05/18
受賞
2015/05/13
ニュースリリース
2015/05/08
受賞
2015/04/27
お知らせ
2015/04/24
受賞
2015/04/22
ニュースリリース
2015/04/15
ニュースリリース
2015/04/13
受賞
2015/04/13
ニュースリリース
2015/04/13
ニュースリリース
2015/04/09
ニュースリリース
2015/04/07
ニュースリリース
2015/04/01
ニュースリリース
2014年度
2015/03/30
お知らせ
2015/03/27
お知らせ
2015/03/23
ニュースリリース
2015/03/20
受賞
2015/03/19
受賞
2015/03/12
お知らせ
2015/03/10
受賞
2015/03/03
受賞
2015/02/24
お知らせ
2015/02/24
お知らせ
2015/02/10
受賞
2015/02/06
お知らせ
2015/02/05
ニュースリリース
2015/02/04
受賞
2015/02/02
受賞
2015/01/23
お知らせ
2015/01/06
お知らせ
2014/12/28
受賞
2014/12/25
受賞
2014/12/24
受賞
2014/12/09
受賞
2014/11/26
受賞
2014/11/20
受賞
2014/11/13
受賞
2014/11/10
受賞
2014/10/31
受賞
2014/10/30
受賞
2014/10/30
受賞
2014/10/30
受賞
2014/10/30
ニュースリリース
2014/10/29
受賞
2014/10/28
受賞
2014/10/17
受賞
2014/10/14
ニュースリリース
2014/10/07
受賞
2014/10/07
受賞
2014/10/07
お知らせ
2014/10/07
受賞
2014/10/07
受賞
2014/10/06
受賞
2014/10/03
受賞
2014/10/03
受賞
2014/10/01
お知らせ
2014/09/11
お知らせ
2014/09/11
ニュースリリース
2014/09/01
お知らせ
2014/08/30
受賞
2014/08/28
受賞
2014/08/08
ニュースリリース
2014/08/04
受賞
2014/07/02
お知らせ
2014/07/02
受賞
2014/06/30
お知らせ
2014/06/30
ニュースリリース
2014/06/10
受賞
2014/06/05
受賞
2014/05/22
ニュースリリース
2014/05/15
受賞
2014/05/09
ニュースリリース
2014/05/08
ニュースリリース
2014/04/30
受賞
2014/04/17
受賞
2014/04/17
受賞
2014/04/10
お知らせ
2014/04/10
受賞
2014/04/08
ニュースリリース
2014/04/02
受賞
2014/04/01
お知らせ
2014/04/01
受賞
2013年度
2014/03/24
受賞
2014/03/20
お知らせ
2014/03/20
受賞
2014/03/17
お知らせ
2014/03/11
受賞
2014/03/10
受賞
2014/02/17
受賞
2014/01/30
受賞
2014/01/24
受賞
2014/01/20
お知らせ
2014/01/16
お知らせ
2013/12/18
受賞
2013/12/16
受賞
2013/12/16
受賞
2013/12/10
ニュースリリース
2013/12/04
お知らせ
2013/12/02
受賞
2013/11/25
ニュースリリース
2013/11/21
受賞
2013/11/18
受賞
2013/11/05
受賞
2013/10/29
受賞
2013/10/29
受賞
2013/10/29
受賞
2013/10/09
受賞
2013/10/08
ニュースリリース
2013/10/04
受賞
2013/10/04
受賞
2013/10/04
受賞
2013/10/03
受賞
2013/10/01
ニュースリリース
2013/09/25
受賞
2013/09/19
受賞
2013/09/09
受賞
2013/09/04
お知らせ
2013/08/30
受賞
2013/08/27
受賞
2013/08/26
受賞
2013/08/23
お知らせ
2013/08/23
お知らせ
2013/08/21
ニュースリリース
2013/07/17
受賞
2013/07/12
受賞
2013/07/02
受賞
2013/07/02
受賞
2013/07/02
ニュースリリース
2013/07/01
ニュースリリース
2013/06/28
受賞
2013/06/25
お知らせ
2013/06/15
お知らせ
2013/06/13
お知らせ
2013/06/12
お知らせ
2013/06/10
受賞
2013/06/10
お知らせ
2013/06/10
受賞
2013/06/10
受賞
2013/06/07
受賞
2013/06/06
お知らせ
2013/06/04
お知らせ
2013/06/03
受賞
2013/06/03
受賞
2013/05/28
ニュースリリース
2013/05/27
お知らせ
2013/05/24
お知らせ
2013/05/23
受賞
2013/05/15
受賞
2013/05/15
ニュースリリース
2013/05/14
ニュースリリース
2013/05/13
受賞
2013/05/10
受賞
2013/05/10
ニュースリリース
2013/04/22
ニュースリリース
2013/04/19
受賞
2013/04/18
お知らせ
2013/04/16
受賞
2013/04/05
受賞
2013/04/01
お知らせ
2012年度
2013/03/26
受賞
2013/03/18
受賞
2013/03/13
受賞
2013/03/11
受賞
2013/03/08
お知らせ
2013/03/07
受賞
2013/02/26
お知らせ
2013/01/24
受賞
2013/01/22
ニュースリリース
2013/01/18
お知らせ
2013/01/17
受賞
2013/01/15
受賞
2013/01/11
受賞
2012/12/25
受賞
2012/12/19
お知らせ
2012/12/18
お知らせ
2012/12/17
受賞
2012/12/17
受賞
2012/12/13
受賞
2012/12/12
ニュースリリース
2012/12/06
受賞
2012/11/16
ニュースリリース
2012/11/13
受賞
2012/11/09
受賞
2012/11/07
受賞
2012/11/06
お知らせ
2012/11/05
お知らせ
2012/11/02
受賞
2012/10/31
受賞
2012/10/30
お知らせ
2012/10/29
受賞
2012/10/29
受賞
2012/10/22
ニュースリリース
2012/10/19
受賞
2012/10/18
ニュースリリース
2012/10/15
お知らせ
2012/10/12
受賞
2012/10/05
お知らせ
2012/09/28
お知らせ
2012/09/27
受賞
2012/09/25
受賞
2012/09/20
受賞
2012/09/18
お知らせ
2012/09/10
ニュースリリース
2012/09/04
お知らせ
2012/08/30
受賞
2012/08/24
受賞
2012/08/20
受賞
2012/07/27
受賞
2012/07/25
受賞
2012/07/17
受賞
2012/07/17
ニュースリリース
2012/07/10
受賞
2012/06/28
ニュースリリース
2012/06/26
受賞
2012/06/22
受賞
2012/06/12
受賞
2012/06/06
ニュースリリース
2012/06/04
受賞
2012/06/01
受賞
2012/05/28
受賞
2012/05/28
ニュースリリース
2012/05/25
受賞
2012/05/24
受賞
2012/05/23
ニュースリリース
2012/05/16
ニュースリリース
2012/05/07
受賞
2012/04/20
ニュースリリース
2012/04/18
ニュースリリース
2012/04/13
受賞
2012/04/12
受賞
2012/04/12
受賞
2012/04/11
受賞
2012/04/10
受賞
2012/04/10
ニュースリリース
2012/04/05
ニュースリリース
2012/04/03
受賞
2012/04/03
受賞
2012/04/03
受賞
2011年度
2012/03/26
受賞
2012/03/26
受賞
2012/03/26
受賞
2012/03/26
受賞
2012/03/26
ニュースリリース
2012/03/13
受賞
2012/03/06
お知らせ
2012/03/05
ニュースリリース
2012/02/23
お知らせ
2012/02/13
ニュースリリース
2012/02/08
ニュースリリース
2012/02/01
受賞
2012/01/26
お知らせ
2012/01/20
受賞
2012/01/04
受賞
2012/01/04
受賞
2011/12/20
受賞
2011/12/19
受賞
2011/12/19
受賞
2011/12/15
お知らせ
2011/12/09
受賞
2011/12/05
受賞
2011/11/30
ニュースリリース
2011/11/24
受賞
2011/11/16
受賞
2011/11/09
ニュースリリース
2011/11/07
ニュースリリース
2011/10/26
お知らせ
2011/10/24
お知らせ
2011/10/21
お知らせ
2011/10/20
ニュースリリース
2011/10/20
ニュースリリース
2011/10/17
お知らせ
2011/10/13
ニュースリリース
2011/10/04
受賞
2011/09/30
ニュースリリース
2011/09/20
お知らせ
2011/09/20
お知らせ
2011/09/16
ニュースリリース
2011/09/09
受賞
2011/08/26
お知らせ
2011/08/23
受賞
2011/08/12
お知らせ
2011/08/08
お知らせ
2011/08/01
受賞
2011/07/28
受賞
2011/07/21
ニュースリリース
2011/07/20
ニュースリリース
2011/07/13
受賞
2011/07/04
ニュースリリース
2011/06/30
受賞
2011/06/20
ニュースリリース
2011/06/10
受賞
2011/06/09
受賞
2011/06/08
受賞
2011/06/06
受賞
2011/05/27
受賞
2011/05/18
受賞
2011/04/20
受賞
2011/04/19
受賞
2011/04/15
お知らせ
2011/04/11
受賞
2011/04/08
ニュースリリース
2010年度
2009年度
ニュースリリース
2025年度
受賞
2025/06/06 ニュースリリース
2025/05/12 ニュースリリース
2025/04/24 ニュースリリース
2025/04/08 ニュースリリース
2025/04/08 ニュースリリース
2025/04/01 ニュースリリース
2024年度
2025/03/11 ニュースリリース
2025/02/19 ニュースリリース
2024/12/24 ニュースリリース
2024/11/28 ニュースリリース
2024/11/01 ニュースリリース
2024/10/21 ニュースリリース
2024/10/16 ニュースリリース
2024/09/17 ニュースリリース
2024/09/02 ニュースリリース
2024/07/18 ニュースリリース
2024/07/17 ニュースリリース
2024/06/13 ニュースリリース
2024/05/30 ニュースリリース
2024/05/23 ニュースリリース
2024/05/22 ニュースリリース
2024/04/30 ニュースリリース
2024/04/22 ニュースリリース
2024/04/18 ニュースリリース
2024/04/10 ニュースリリース
2024/04/09 ニュースリリース
2024/04/01 ニュースリリース
2024/04/01 ニュースリリース
2023年度
2024/03/28 ニュースリリース
2024/03/27 ニュースリリース
2024/03/18 ニュースリリース
2024/03/04 ニュースリリース
2024/03/01 ニュースリリース
2024/02/29 ニュースリリース
2024/01/30 ニュースリリース
2024/01/19 ニュースリリース
2023/12/18 ニュースリリース
2023/12/07 ニュースリリース
2023/11/27 ニュースリリース
2023/10/30 ニュースリリース
2023/10/23 ニュースリリース
2023/10/20 ニュースリリース
2023/10/18 ニュースリリース
2023/06/12 ニュースリリース
2023/05/24 ニュースリリース
2023/05/23 ニュースリリース
2023/05/15 ニュースリリース
2023/05/02 ニュースリリース
2023/04/07 ニュースリリース
2022年度
2023/03/30 ニュースリリース
2023/03/29 ニュースリリース
2023/03/17 ニュースリリース
2023/01/23 ニュースリリース
2023/01/13 ニュースリリース
2023/01/10 ニュースリリース
2022/12/23 ニュースリリース
2022/11/24 ニュースリリース
2022/11/08 ニュースリリース
2022/11/01 ニュースリリース
2022/10/31 ニュースリリース
2022/10/26 ニュースリリース
2022/09/15 ニュースリリース
2022/08/31 ニュースリリース
2022/08/18 ニュースリリース
2022/08/12 ニュースリリース
2022/07/27 ニュースリリース
2022/07/07 ニュースリリース
2022/05/24 ニュースリリース
2022/05/17 ニュースリリース
2022/05/16 ニュースリリース
2022/05/13 ニュースリリース
2022/04/18 ニュースリリース
2022/04/08 ニュースリリース
2022/04/01 ニュースリリース
2021年度
2022/03/15 ニュースリリース
2022/02/28 ニュースリリース
2022/02/14 ニュースリリース
2022/01/14 ニュースリリース
2021/11/24 ニュースリリース
2021/11/17 ニュースリリース
2021/11/15 ニュースリリース
2021/11/04 ニュースリリース
2021/10/20 ニュースリリース
2021/09/22 ニュースリリース
2021/07/16 ニュースリリース
2021/07/13 ニュースリリース
2021/07/01 ニュースリリース
2021/06/17 ニュースリリース
2021/06/16 ニュースリリース
2021/05/31 ニュースリリース
2021/05/26 ニュースリリース
2021/05/25 ニュースリリース
2021/04/27 ニュースリリース
2021/04/13 ニュースリリース
2021/04/12 ニュースリリース
2020年度
2021/03/23 ニュースリリース
2021/03/09 ニュースリリース
2021/02/19 ニュースリリース
2021/02/15 ニュースリリース
2021/01/29 ニュースリリース
2021/01/22 ニュースリリース
2020/12/15 ニュースリリース
2020/12/11 ニュースリリース
2020/11/25 ニュースリリース
2020/11/12 ニュースリリース
2020/11/06 ニュースリリース
2020/10/17 ニュースリリース
2020/10/05 ニュースリリース
2020/09/28 ニュースリリース
2020/07/13 ニュースリリース
2020/06/10 ニュースリリース
2020/05/28 ニュースリリース
2020/04/30 ニュースリリース
2020/04/24 ニュースリリース
2020/04/07 ニュースリリース
2020/04/07 ニュースリリース
2020/04/07 ニュースリリース
2020/04/06 ニュースリリース
2020/04/01 ニュースリリース
2019年度
2020/03/23 ニュースリリース
2020/03/11 ニュースリリース
2020/03/05 ニュースリリース
2020/02/25 ニュースリリース
2020/02/12 ニュースリリース
2020/01/28 ニュースリリース
2020/01/24 ニュースリリース
2019/12/25 ニュースリリース
2019/12/06 ニュースリリース
2019/11/29 ニュースリリース
2019/11/26 ニュースリリース
2019/11/18 ニュースリリース
2019/10/29 ニュースリリース
2019/10/11 ニュースリリース
2019/10/02 ニュースリリース
2019/09/13 ニュースリリース
2019/07/10 ニュースリリース
2019/06/24 ニュースリリース
2019/06/06 ニュースリリース
2019/05/25 ニュースリリース
2019/04/26 ニュースリリース
2019/04/22 ニュースリリース
2019/04/16 ニュースリリース
2019/04/09 ニュースリリース
2019/04/09 ニュースリリース
2019/04/08 ニュースリリース
2019/04/04 ニュースリリース
2018年度
2019/03/27 ニュースリリース
2019/03/13 ニュースリリース
2019/03/01 ニュースリリース
2018/12/25 ニュースリリース
2018/12/20 ニュースリリース
2018/12/11 ニュースリリース
2018/12/04 ニュースリリース
2018/11/27 ニュースリリース
2018/11/06 ニュースリリース
2018/10/12 ニュースリリース
2018/10/04 ニュースリリース
2018/10/01 ニュースリリース
2018/09/20 ニュースリリース
2018/09/07 ニュースリリース
2018/06/28 ニュースリリース
2018/06/18 ニュースリリース
2018/05/16 ニュースリリース
2018/04/13 ニュースリリース
2018/04/12 ニュースリリース
2018/04/10 ニュースリリース
2018/04/02 ニュースリリース
2017年度
2018/03/23 ニュースリリース
2018/03/16 ニュースリリース
2018/03/01 ニュースリリース
2018/01/23 ニュースリリース
2018/01/18 ニュースリリース
2017/12/26 ニュースリリース
2017/12/25 ニュースリリース
2017/12/25 ニュースリリース
2017/12/14 ニュースリリース
2017/11/27 ニュースリリース
2017/11/22 ニュースリリース
2017/11/20 ニュースリリース
2017/11/07 ニュースリリース
2017/11/06 ニュースリリース
2017/10/27 ニュースリリース
2017/10/26 ニュースリリース
2017/09/28 ニュースリリース
2017/09/12 ニュースリリース
2017/08/18 ニュースリリース
2017/08/09 ニュースリリース
2017/08/01 ニュースリリース
2017/07/03 ニュースリリース
2017/06/28 ニュースリリース
2017/06/22 ニュースリリース
2017/06/12 ニュースリリース
2017/06/08 ニュースリリース
2017/06/08 ニュースリリース
2017/06/05 ニュースリリース
2017/06/05 ニュースリリース
2017/06/02 ニュースリリース
2017/06/02 ニュースリリース
2017/06/01 ニュースリリース
2017/05/23 ニュースリリース
2017/05/10 ニュースリリース
2017/04/11 ニュースリリース
2017/04/11 ニュースリリース
2017/04/06 ニュースリリース
2017/04/03 ニュースリリース
2016年度
2017/03/30 ニュースリリース
2017/03/17 ニュースリリース
2017/03/16 ニュースリリース
2017/03/14 ニュースリリース
2017/03/06 ニュースリリース
2017/02/27 ニュースリリース
2017/02/27 ニュースリリース
2017/02/21 ニュースリリース
2017/02/08 ニュースリリース
2017/01/24 ニュースリリース
2017/01/19 ニュースリリース
2016/12/27 ニュースリリース
2016/12/06 ニュースリリース
2016/11/30 ニュースリリース
2016/11/29 ニュースリリース
2016/11/24 ニュースリリース
2016/11/22 ニュースリリース
2016/11/21 ニュースリリース
2016/11/17 ニュースリリース
2016/11/14 ニュースリリース
2016/11/14 ニュースリリース
2016/11/14 ニュースリリース
2016/11/11 ニュースリリース
2016/11/10 ニュースリリース
2016/11/02 ニュースリリース
2016/10/31 ニュースリリース
2016/10/21 ニュースリリース
2016/10/05 ニュースリリース
2016/10/03 ニュースリリース
2016/09/29 ニュースリリース
2016/09/27 ニュースリリース
2016/09/26 ニュースリリース
2016/09/21 ニュースリリース
2016/09/20 ニュースリリース
2016/09/07 ニュースリリース
2016/08/31 ニュースリリース
2016/07/27 ニュースリリース
2016/07/26 ニュースリリース
2016/07/11 ニュースリリース
2016/06/21 ニュースリリース
2016/06/09 ニュースリリース
2016/06/01 ニュースリリース
2016/05/25 ニュースリリース
2016/05/25 ニュースリリース
2016/05/25 ニュースリリース
2016/05/24 ニュースリリース
2016/05/17 ニュースリリース
2016/05/17 ニュースリリース
2016/05/09 ニュースリリース
2016/04/26 ニュースリリース
2016/04/01 ニュースリリース
2015年度
2016/03/25 ニュースリリース
2016/02/29 ニュースリリース
2016/02/19 ニュースリリース
2016/02/16 ニュースリリース
2016/02/15 ニュースリリース
2016/02/15 ニュースリリース
2016/02/09 ニュースリリース
2015/12/10 ニュースリリース
2015/11/17 ニュースリリース
2015/11/14 ニュースリリース
2015/11/14 ニュースリリース
2015/11/14 ニュースリリース
2015/11/04 ニュースリリース
2015/10/30 ニュースリリース
2015/09/02 ニュースリリース
2015/08/10 ニュースリリース
2015/08/06 ニュースリリース
2015/07/17 ニュースリリース
2015/06/24 ニュースリリース
2015/06/15 ニュースリリース
2015/06/08 ニュースリリース
2015/06/04 ニュースリリース
2015/06/04 ニュースリリース
2015/05/28 ニュースリリース
2015/05/13 ニュースリリース
2015/04/22 ニュースリリース
2015/04/15 ニュースリリース
2015/04/13 ニュースリリース
2015/04/13 ニュースリリース
2015/04/09 ニュースリリース
2015/04/07 ニュースリリース
2015/04/01 ニュースリリース
2014年度
2015/03/23 ニュースリリース
2015/02/05 ニュースリリース
2014/10/30 ニュースリリース
2014/10/14 ニュースリリース
2014/09/11 ニュースリリース
2014/08/08 ニュースリリース
2014/06/30 ニュースリリース
2014/05/22 ニュースリリース
2014/05/09 ニュースリリース
2014/05/08 ニュースリリース
2014/04/08 ニュースリリース
2013年度
2013/12/10 ニュースリリース
2013/11/25 ニュースリリース
2013/10/08 ニュースリリース
2013/10/01 ニュースリリース
2013/08/21 ニュースリリース
2013/07/02 ニュースリリース
2013/07/01 ニュースリリース
2013/05/28 ニュースリリース
2013/05/15 ニュースリリース
2013/05/14 ニュースリリース
2013/05/10 ニュースリリース
2013/04/22 ニュースリリース
2012年度
2013/01/22 ニュースリリース
2012/12/12 ニュースリリース
2012/11/16 ニュースリリース
2012/10/22 ニュースリリース
2012/10/18 ニュースリリース
2012/09/10 ニュースリリース
2012/07/17 ニュースリリース
2012/06/28 ニュースリリース
2012/06/06 ニュースリリース
2012/05/28 ニュースリリース
2012/05/23 ニュースリリース
2012/05/16 ニュースリリース
2012/04/20 ニュースリリース
2012/04/18 ニュースリリース
2012/04/10 ニュースリリース
2012/04/05 ニュースリリース
2011年度
2012/03/26 ニュースリリース
2012/03/05 ニュースリリース
2012/02/13 ニュースリリース
2012/02/08 ニュースリリース
2011/11/30 ニュースリリース
2011/11/09 ニュースリリース
2011/11/07 ニュースリリース
2011/10/20 ニュースリリース
2011/10/20 ニュースリリース
2011/10/13 ニュースリリース
2011/09/30 ニュースリリース
2011/09/16 ニュースリリース
2011/07/21 ニュースリリース
2011/07/20 ニュースリリース
2011/07/04 ニュースリリース
2011/06/20 ニュースリリース
2011/04/08 ニュースリリース
2010年度
2009年度
2025年度
2025/07/07 受賞
2025/06/12 受賞
2025/06/05 受賞
2025/04/15 受賞
2025/04/08 受賞
2025/04/08 ニュースリリース
2025/04/08 ニュースリリース
2025/04/03 受賞
2024年度
2025/01/22 受賞
2025/01/16 受賞
2025/01/14 受賞
2024/12/18 受賞
2024/12/05 受賞
2024/12/04 受賞
2024/11/03 受賞
2024/10/02 受賞
2024/09/26 受賞
2024/09/11 受賞
2024/09/05 受賞
2024/08/15 受賞
2024/08/15 受賞
2024/08/06 受賞
2024/08/02 受賞
2024/07/03 受賞
2024/06/10 受賞
2024/06/03 受賞
2024/05/28 受賞
2024/04/22 ニュースリリース
2024/04/09 ニュースリリース
2023年度
2024/03/15 受賞
2024/03/05 受賞
2024/03/05 受賞
2024/02/22 受賞
2024/02/06 受賞
2024/02/02 受賞
2023/12/07 受賞
2023/11/28 受賞
2023/11/07 受賞
2023/09/27 受賞
2023/09/13 受賞
2023/07/31 受賞
2023/07/23 受賞
2023/07/21 受賞
2023/07/13 受賞
2023/07/01 受賞
2023/06/08 受賞
2023/05/14 受賞
2023/05/08 受賞
2022年度
2023/03/22 受賞
2023/03/01 受賞
2023/01/30 受賞
2023/01/10 受賞
2022/12/20 受賞
2022/12/08 受賞
2022/11/25 受賞
2022/11/25 受賞
2022/11/21 受賞
2022/11/12 受賞
2022/11/10 受賞
2022/11/08 受賞
2022/10/26 受賞
2022/09/06 受賞
2022/09/02 受賞
2022/09/02 受賞
2022/08/24 受賞
2022/07/27 受賞
2022/06/15 受賞
2022/05/24 受賞
2022/05/15 受賞
2022/04/26 受賞
2022/04/08 受賞
2022/04/08 ニュースリリース
2021年度
2022/03/14 受賞
2022/03/02 受賞
2022/02/21 受賞
2022/02/21 受賞
2022/02/21 受賞
2022/01/28 受賞
2021/12/24 受賞
2021/12/24 受賞
2021/12/08 受賞
2021/11/25 受賞
2021/11/13 受賞
2021/11/03 受賞
2021/11/01 受賞
2021/11/01 受賞
2021/11/01 受賞
2021/10/27 受賞
2021/10/27 受賞
2021/10/12 受賞
2021/09/17 受賞
2021/09/09 受賞
2021/08/03 受賞
2021/07/22 受賞
2021/06/21 受賞
2021/06/21 受賞
2021/06/15 受賞
2021/06/08 受賞
2021/04/30 受賞
2020年度
2021/03/06 受賞
2021/03/05 受賞
2021/02/16 受賞
2021/02/15 受賞
2021/01/12 受賞
2020/12/25 受賞
2020/12/18 受賞
2020/12/17 受賞
2020/12/14 受賞
2020/11/25 受賞
2020/11/15 受賞
2020/11/01 受賞
2020/10/08 受賞
2020/09/24 受賞
2020/09/12 受賞
2020/09/07 受賞
2020/08/06 受賞
2020/07/31 受賞
2020/07/23 受賞
2020/06/25 受賞
2020/05/23 受賞
2020/05/16 受賞
2020/04/17 受賞
2020/04/07 ニュースリリース
2020/04/07 ニュースリリース
2020/04/07 ニュースリリース
2020/04/06 ニュースリリース
2019年度
2020/03/17 受賞
2020/03/06 受賞
2020/03/05 受賞
2020/02/26 受賞
2019/12/27 受賞
2019/12/04 受賞
2019/11/29 受賞
2019/11/12 受賞
2019/10/30 受賞
2019/10/30 受賞
2019/10/30 受賞
2019/10/02 受賞
2019/10/01 受賞
2019/10/01 受賞
2019/09/25 受賞
2019/09/24 受賞
2019/09/24 受賞
2019/09/22 受賞
2019/09/22 受賞
2019/08/28 受賞
2019/08/20 受賞
2019/08/07 受賞
2019/08/02 受賞
2019/07/11 受賞
2019/07/11 受賞
2019/07/04 受賞
2019/06/27 受賞
2019/06/21 受賞
2019/06/20 受賞
2019/06/06 受賞
2019/06/03 受賞
2019/05/09 受賞
2019/05/06 受賞
2019/04/19 受賞
2019/04/10 受賞
2018年度
2019/03/20 受賞
2019/03/15 受賞
2019/03/15 受賞
2019/03/09 受賞
2019/02/16 受賞
2019/01/31 受賞
2019/01/28 受賞
2018/12/21 受賞
2018/12/13 受賞
2018/12/13 受賞
2018/11/14 受賞
2018/11/14 受賞
2018/11/14 受賞
2018/11/13 受賞
2018/11/09 受賞
2018/11/07 受賞
2018/11/06 ニュースリリース
2018/10/11 受賞
2018/09/18 受賞
2018/09/15 受賞
2018/08/30 受賞
2018/08/27 受賞
2018/07/25 受賞
2018/07/24 受賞
2018/07/16 受賞
2018/07/03 受賞
2018/06/25 受賞
2018/06/25 受賞
2018/06/22 受賞
2018/05/20 受賞
2018/04/21 受賞
2017年度
2018/03/23 受賞
2018/03/13 受賞
2018/03/13 受賞
2018/03/06 受賞
2018/02/17 受賞
2017/12/23 受賞
2017/12/06 受賞
2017/11/30 受賞
2017/11/22 受賞
2017/11/14 受賞
2017/11/03 受賞
2017/10/26 受賞
2017/10/19 受賞
2017/10/17 受賞
2017/10/11 受賞
2017/09/19 受賞
2017/09/18 受賞
2017/09/15 受賞
2017/08/20 受賞
2017/08/09 受賞
2017/08/02 受賞
2017/07/30 受賞
2017/07/30 受賞
2017/07/26 受賞
2017/07/11 受賞
2017/07/10 受賞
2017/07/08 受賞
2017/07/05 受賞
2017/06/08 受賞
2017/05/16 受賞
2017/04/26 受賞
2017/04/26 受賞
2017/04/26 受賞
2017/04/11 ニュースリリース
2017/04/11 ニュースリリース
2016年度
2017/03/24 受賞
2017/03/24 受賞
2017/03/16 受賞
2017/03/16 受賞
2017/03/09 受賞
2017/02/24 受賞
2017/01/31 受賞
2016/12/27 ニュースリリース
2016/12/15 受賞
2016/12/15 受賞
2016/12/12 受賞
2016/12/12 受賞
2016/12/08 受賞
2016/12/01 受賞
2016/12/01 受賞
2016/11/29 受賞
2016/11/23 受賞
2016/11/10 受賞
2016/11/09 受賞
2016/11/04 受賞
2016/11/04 受賞
2016/10/30 受賞
2016/10/28 受賞
2016/10/03 ニュースリリース
2016/09/21 受賞
2016/09/21 受賞
2016/09/20 受賞
2016/09/17 受賞
2016/09/14 受賞
2016/09/12 受賞
2016/09/09 受賞
2016/08/18 受賞
2016/07/12 受賞
2016/07/12 受賞
2016/06/24 受賞
2016/06/24 受賞
2016/06/24 受賞
2016/06/03 受賞
2016/06/03 受賞
2016/06/03 受賞
2016/06/02 受賞
2016/06/01 受賞
2016/05/17 受賞
2016/05/17 受賞
2016/05/17 受賞
2016/04/01 受賞
2015年度
2016/03/24 受賞
2016/03/24 受賞
2016/03/24 受賞
2016/03/15 受賞
2016/03/01 受賞
2016/02/15 受賞
2016/01/30 受賞
2016/01/22 受賞
2015/12/09 受賞
2015/11/20 受賞
2015/11/20 受賞
2015/11/06 受賞
2015/10/30 受賞
2015/10/28 受賞
2015/10/27 受賞
2015/10/21 受賞
2015/10/16 受賞
2015/10/01 受賞
2015/09/17 受賞
2015/09/09 受賞
2015/07/31 受賞
2015/07/31 受賞
2015/07/28 受賞
2015/07/22 受賞
2015/07/21 受賞
2015/07/12 受賞
2015/07/10 受賞
2015/07/10 受賞
2015/06/23 受賞
2015/06/19 受賞
2015/06/12 受賞
2015/06/04 ニュースリリース
2015/05/20 受賞
2015/05/18 受賞
2015/05/08 受賞
2015/04/24 受賞
2015/04/22 ニュースリリース
2015/04/13 受賞
2015/04/07 ニュースリリース
2014年度
2015/03/20 受賞
2015/03/19 受賞
2015/03/10 受賞
2015/03/03 受賞
2015/02/10 受賞
2015/02/04 受賞
2015/02/02 受賞
2014/12/28 受賞
2014/12/25 受賞
2014/12/24 受賞
2014/12/09 受賞
2014/11/26 受賞
2014/11/20 受賞
2014/11/13 受賞
2014/11/10 受賞
2014/10/31 受賞
2014/10/30 受賞
2014/10/30 受賞
2014/10/30 受賞
2014/10/29 受賞
2014/10/28 受賞
2014/10/17 受賞
2014/10/07 受賞
2014/10/07 受賞
2014/10/07 受賞
2014/10/07 受賞
2014/10/06 受賞
2014/10/03 受賞
2014/10/03 受賞
2014/08/30 受賞
2014/08/28 受賞
2014/08/04 受賞
2014/07/02 受賞
2014/06/10 受賞
2014/06/05 受賞
2014/05/15 受賞
2014/04/30 受賞
2014/04/17 受賞
2014/04/17 受賞
2014/04/10 受賞
2014/04/02 受賞
2014/04/01 受賞
2013年度
2014/03/24 受賞
2014/03/20 受賞
2014/03/11 受賞
2014/03/10 受賞
2014/02/17 受賞
2014/01/30 受賞
2014/01/24 受賞
2013/12/18 受賞
2013/12/16 受賞
2013/12/16 受賞
2013/12/02 受賞
2013/11/21 受賞
2013/11/18 受賞
2013/11/05 受賞
2013/10/29 受賞
2013/10/29 受賞
2013/10/29 受賞
2013/10/09 受賞
2013/10/04 受賞
2013/10/04 受賞
2013/10/04 受賞
2013/10/03 受賞
2013/09/25 受賞
2013/09/19 受賞
2013/09/09 受賞
2013/08/30 受賞
2013/08/27 受賞
2013/08/26 受賞
2013/07/17 受賞
2013/07/12 受賞
2013/07/02 受賞
2013/07/02 受賞
2013/06/28 受賞
2013/06/10 受賞
2013/06/10 受賞
2013/06/10 受賞
2013/06/07 受賞
2013/06/03 受賞
2013/06/03 受賞
2013/05/23 受賞
2013/05/15 受賞
2013/05/13 受賞
2013/05/10 受賞
2013/04/22 ニュースリリース
2013/04/19 受賞
2013/04/16 受賞
2013/04/05 受賞
2012年度
2013/03/26 受賞
2013/03/18 受賞
2013/03/13 受賞
2013/03/11 受賞
2013/03/07 受賞
2013/01/24 受賞
2013/01/17 受賞
2013/01/15 受賞
2013/01/11 受賞
2012/12/25 受賞
2012/12/17 受賞
2012/12/17 受賞
2012/12/13 受賞
2012/12/06 受賞
2012/11/13 受賞
2012/11/09 受賞
2012/11/07 受賞
2012/11/02 受賞
2012/10/31 受賞
2012/10/29 受賞
2012/10/29 受賞
2012/10/19 受賞
2012/10/12 受賞
2012/09/27 受賞
2012/09/25 受賞
2012/09/20 受賞
2012/08/30 受賞
2012/08/24 受賞
2012/08/20 受賞
2012/07/27 受賞
2012/07/25 受賞
2012/07/17 受賞
2012/07/10 受賞
2012/06/26 受賞
2012/06/22 受賞
2012/06/12 受賞
2012/06/04 受賞
2012/06/01 受賞
2012/05/28 受賞
2012/05/25 受賞
2012/05/24 受賞
2012/05/07 受賞
2012/04/13 受賞
2012/04/12 受賞
2012/04/12 受賞
2012/04/11 受賞
2012/04/10 受賞
2012/04/03 受賞
2012/04/03 受賞
2012/04/03 受賞
2011年度
2012/03/26 受賞
2012/03/26 受賞
2012/03/26 受賞
2012/03/26 受賞
2012/03/13 受賞
2012/02/01 受賞
2012/01/20 受賞
2012/01/04 受賞
2012/01/04 受賞
2011/12/20 受賞
2011/12/19 受賞
2011/12/19 受賞
2011/12/09 受賞
2011/12/05 受賞
2011/11/24 受賞
2011/11/16 受賞
2011/10/04 受賞
2011/09/09 受賞
2011/08/23 受賞
2011/08/01 受賞
2011/07/28 受賞
2011/07/13 受賞
2011/06/30 受賞
2011/06/10 受賞
2011/06/09 受賞
2011/06/08 受賞
2011/06/06 受賞
2011/05/27 受賞
2011/05/18 受賞
2011/04/20 受賞
2011/04/19 受賞
2011/04/11 受賞
2010年度
注目コンテンツ / SPECIAL
 NIIサービスニュース
NIIサービスニュース
 国立情報学研究所
国立情報学研究所2025年度 要覧
 国立情報学研究所 2025年度 概要
国立情報学研究所 2025年度 概要
 NII Today No.104
NII Today No.104
 SINETStream 事例紹介:トレーラー型動物施設 [徳島大学 バイオイノベーション研究所]
SINETStream 事例紹介:トレーラー型動物施設 [徳島大学 バイオイノベーション研究所]
 ウェブサイト「軽井沢土曜懇話会アーカイブス」を公開
ウェブサイト「軽井沢土曜懇話会アーカイブス」を公開
 情報研シリーズ これからの「ソフトウェアづくり」との向き合い方
情報研シリーズ これからの「ソフトウェアづくり」との向き合い方
 学術研究プラットフォーム紹介動画
学術研究プラットフォーム紹介動画
 教育機関DXシンポ
教育機関DXシンポ
 高等教育機関におけるセキュリティポリシー
高等教育機関におけるセキュリティポリシー
 情報・システム研究機構におけるLGBTQを尊重する基本理念
情報・システム研究機構におけるLGBTQを尊重する基本理念
 オープンサイエンスのためのデータ管理基盤ハンドブック
オープンサイエンスのためのデータ管理基盤ハンドブック
 教育機関DXシンポ
教育機関DXシンポアーカイブス
 コンピュータサイエンスパーク
コンピュータサイエンスパーク
Copyright© National Institute of Informatics