ニュース / News
ニュースリリース
国立情報学研究所に「大規模言語モデル研究開発センター」新設
~国産LLMを構築し、生成AIモデルの透明性・信頼性を確保する研究開発を加速〜
大学共同利用機関法人 情報・システム研究機構 国立情報学研究所 (NII、所長:黒橋 禎夫、東京都千代田区) は、2024年(令和6年)4月1日、新たに大規模言語モデル(Large Language Models、以下「LLM」)の研究開発を行う「大規模言語モデル研究開発センター(センター長:黒橋 禎夫NII所長、以下「LLM研究開発センター」)」(英語名:Research and Development Center for Large Language Models、略称:LLMC)を開設しました。
NIIでは2023年5月、国内の研究機関のみならず民間企業などの幅広い人材が参加するLLM勉強会(LLM-jp)を立ち上げ、オープンな生成AIの研究開発を推進してきましたが、今般、文部科学省の「生成AIモデルの透明性・信頼性の確保に向けた研究開発拠点形成」事業を実施する拠点として、研究所内に新たに専門のセンターを設立し、新進気鋭のAI研究者がLLMの研究開発に邁進できる体制を構築しました。
LLM研究開発センターでは、まずは今年夏ごろの完成を目指して1750億パラメータ(GPT-3級)のLLMを構築するとともに、LLMの透明性・信頼性の確保に向けた先端的な研究開発など、オープンかつ日本語に強い大規模モデルの構築に関連する研究開発を推進します。そして、このような活動を通じ、一連の知識と経験を蓄積し、AIの進化、ひいては将来に渡る革新的なイノベーションの創出に貢献します。
大規模言語モデル(LLM)は全産業に波及しつつあり、基盤モデルとしてこれまでの産業基盤を抜本的に変革する可能性を秘めているとともに、幅広い科学技術研究に必須の知識基盤になると期待されています。しかし、現状では強いモデルの学習コーパス・データは非公開で、モデルの振舞いを含めて全体がブラックボックスとなっており、ハルシネーションやバイアス等の課題が山積しています。また、有力な基盤モデルにおいて学習に用いられるデータの言語は英語が中心であり、日本語の理解・生成能力は相対的に劣っています。現状、国内では、1000億パラメータ規模の学習が長期間行われた例が限られており、LLM開発における知見の獲得が遅れています。
国立情報学研究所(NII)が主宰するLLM勉強会(LLM-jp)では、2023年10月に130億パラメータのLLMを構築、公開し、国内のLLM開発に貢献してきました。今般、文部科学省の「生成AIモデルの透明性・信頼性の確保に向けた研究開発拠点形成」事業を実施する拠点として、NII内に「大規模言語モデル研究開発センター」(LLM研究開発センター)を設置し、生成AIモデルの透明性・信頼性の確保に向けた研究開発を推進する体制を整えました(図1)。LLM-jpにおけるLLM開発の知見を踏まえ、研究者と技術者が一体的に研究開発を行う知の拠点を構築し、生成AIモデルに関する研究力・開発力醸成のための環境を整備します。
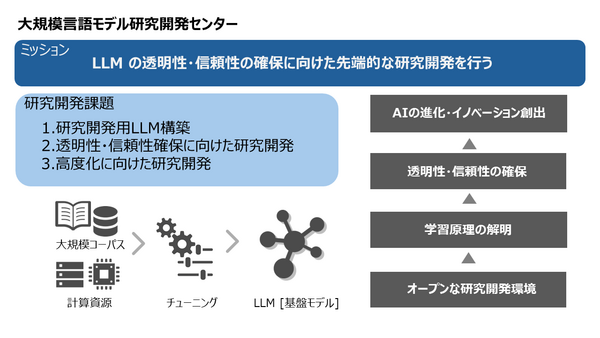
LLM研究開発センターでは以下の研究開発を実施します。
- 研究開発用LLM構築
コーパス整備、計算環境整備、評価用ベンチマーク作成などを行うとともに研究開発用のLLMを構築する - 透明性・信頼性確保に向けた研究開発
生成AIの挙動原理を解明すること、またデータ改変やデータバイアス等の影響を抑制する技術を開発することなどにより、生成AIの透明性・信頼性を確保する - LLMの高度化に向けた研究開発
ドメイン適応、モデル自体の軽量化など、生成AIモデルの高度化に資する研究開発を行う
LLM-jpにおける研究開発をさらに発展させ、まずは今年夏ごろの完成を目指して1750億パラメータ規模(GPT-3級)のLLMを構築します。研究成果のモデルへの適用や試行錯誤を通じて、透明性・信頼性を確保した生成 AIモデル構築手法の確立を目指すとともに、一連の知識と経験を蓄積し、AIの進化、ひいては将来に渡る革新的なイノベーションの創出に貢献します。
【センターの概要】
センター名
大規模言語モデル研究開発センター
センター長
副センター長
相澤 彰子(NII副所長/コンテンツ科学研究系 教授)
武田 浩一(NII特任教授)
本センターの研究開発には所属研究員の他、LLM-jpとの連携等を通じて、大学、企業などから研究者が多数参加します。また、今後も研究体制の増強を図る予定です。関連リンクをご参照下さい。
【黒橋 禎夫 センター長コメント】
「国立情報学研究所では、2023年5月から、趣旨に賛同した人なら誰でも参加できるLLM-jpを立ち上げ、モデル・データ・ツール・技術資料等を議論の過程・失敗を含めすべて公開する取り組みを行ってきました。大学、企業から多くの参加を得て、現時点で1000名を超える規模まで成長しています。このような取り組みが認められ、LLM研究開発センターを設置することになりました。必要な計算資源を整備し、組織横断で生成AIの原理解明と構築手法の確立に挑戦したいと考えています。優秀な若い方に集まって頂き、日本のLLM 研究開発のハブとなり、また国際的な連携も進めていきます。」
関連リンク
- 大規模言語モデル研究開発センター
- 130億パラメータの大規模言語モデル「LLM-jp-13B」を構築~NII主宰LLM勉強会(LLM-jp)の初期の成果をアカデミアや産業界の研究開発に資するために公開~ - NIIニュースリリース(2023/10/20)
News Release: PDF
国立情報学研究所に「大規模言語モデル研究開発センター」新設
~国産LLMを構築し、生成AIモデルの透明性・信頼性を確保する研究開発を加速〜
注目コンテンツ / SPECIAL
 NIIサービスニュース
NIIサービスニュース
 国立情報学研究所
国立情報学研究所2025年度 要覧
 国立情報学研究所 2025年度 概要
国立情報学研究所 2025年度 概要
 NII Today No.104
NII Today No.104
 SINETStream 事例紹介:トレーラー型動物施設 [徳島大学 バイオイノベーション研究所]
SINETStream 事例紹介:トレーラー型動物施設 [徳島大学 バイオイノベーション研究所]
 ウェブサイト「軽井沢土曜懇話会アーカイブス」を公開
ウェブサイト「軽井沢土曜懇話会アーカイブス」を公開
 情報研シリーズ これからの「ソフトウェアづくり」との向き合い方
情報研シリーズ これからの「ソフトウェアづくり」との向き合い方
 学術研究プラットフォーム紹介動画
学術研究プラットフォーム紹介動画
 教育機関DXシンポ
教育機関DXシンポ
 高等教育機関におけるセキュリティポリシー
高等教育機関におけるセキュリティポリシー
 情報・システム研究機構におけるLGBTQを尊重する基本理念
情報・システム研究機構におけるLGBTQを尊重する基本理念
 オープンサイエンスのためのデータ管理基盤ハンドブック
オープンサイエンスのためのデータ管理基盤ハンドブック
 教育機関DXシンポ
教育機関DXシンポアーカイブス
 コンピュータサイエンスパーク
コンピュータサイエンスパーク