研究 / Research
JST CREST
国が定める戦略目標の達成に向けて、独創的で国際的に高い水準の基礎研究を推進し、今後の科学技術イノベーションに大きく貢献する卓越した研究成果を創出することを目的としたチーム型研究。
基礎理論とシステム基盤技術の融合によるSociety 5.0のための基盤ソフトウェアの創出
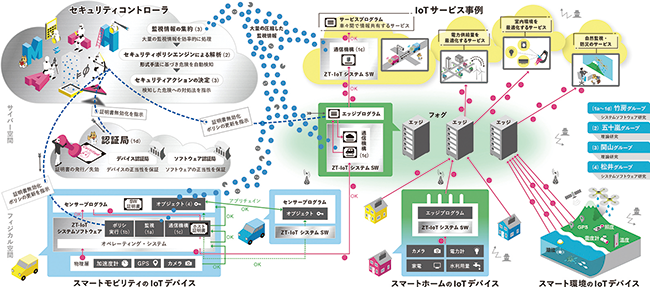
形式検証とシステムソフトウェアの協働によるゼロトラストIoT
研究代表者:アーキテクチャ科学研究系教授 竹房 あつ子
Society 5.0では、防犯カメラや室内外の環境センサ、産業用ロボットといった多種大量のIoT (Internet of Things)デバイスから収集されるセンサデータをクラウドに収集してAI処理を行い、生活の質の向上、自然監視や防災減災、都市環境の効率化といった新たな価値の創造が期待されています。
しかしながら、このようなIoTシステムは様々なサイバーセキュリティ上の脅威にさらされていて、社会インフラに莫大な被害を及ぼすような事例も発生しています。
この研究では、理論研究とシステムソフトウェア研究の融合によって、ゼロトラストの概念を踏襲した安全なIoTシステム(ZT-IoT)の実現を目指しています。
ゼロトラストは、VPNやファイアウォールなどの安全対策を無条件に信頼するのではなく、保護したい計算機やデータに対して継続的に監視、評価し、セキュリティ対策を改善していくという、サイバーセキュリティ計画の方法論です。私たちの研究では、ゼロトラストの考え方に基づき、形式検証とシステムソフトウェア技術を融合させる独創的なアプローチによって、安全なIoTシステムを実現します。
理論研究では、IoTシステムのトラストチェーンの正当性に数学的証明を与えるとともに、動的検証技術も併用して未知の脅威にも対応する新たな形式検証手法を確立します。
システムソフト研究では、理論的成果と連係して上記トラストチェーンを支える実行隔離・自動検知・自動対処技術を開発し、ZT-IoTを実証します。
さらに、ZT-IoTの安全性を説明可能な形(アカウンタビリティ)で保証して、I o Tシステムの社会受容を促進し、Society 5.0の実現に貢献します。
信頼されるAIシステムを支える基盤技術
実社会での応用・実用化が急速に広がる人工知能(AI)技術は、新たな科学的・社会的・経済的価値を創出していく上で不可欠です。一方で、深層学習をはじめとする機械学習技術はブラックボックス問題やバイアス問題等の信頼性や安全性に関わる様々な課題を抱えており、その対策が喫緊の課題となっています。
そこで本研究領域は、人間が社会の中で幅広く安心して利用できる「信頼される高品質なAI」の実現につながる基盤技術の創出やそれらを活用したAIシステムの構築を行います。研究にあたっては、人間中心のAIシステムに関する信頼性や安全性等の定義や評価法の検討に取り組み、AIシステム全体としてその要求や要件を満たす技術の確立を目指します。 具体的には、以下の研究開発に取り組みます。
(1)「信頼されるAI」の実現に向けた発展的・革新的なAI新技術
(2)AIシステムに社会が期待する信頼性・安全性を確保する技術
(3)人間中心のAI社会に向けたデータの信頼性確保及び人間の主体的な意思決定支援技術
上記により、社会的課題の解決や新たなサイエンス、価値の創造につなげるとともに、信頼されるAIに関連した新たな研究コミュニティの創成やAI研究における日本のプレゼンスの向上を目指します。
なお、本研究領域は文部科学省の人工知能/ビッグデータ/IoT/サイバーセキュリティ統合プロジェクト(AIPプロジェクト)の一環として運営します。
本研究領域は、文部科学省の選定した戦略目標「信頼されるAI」のもとに、2020年度に発足しました。
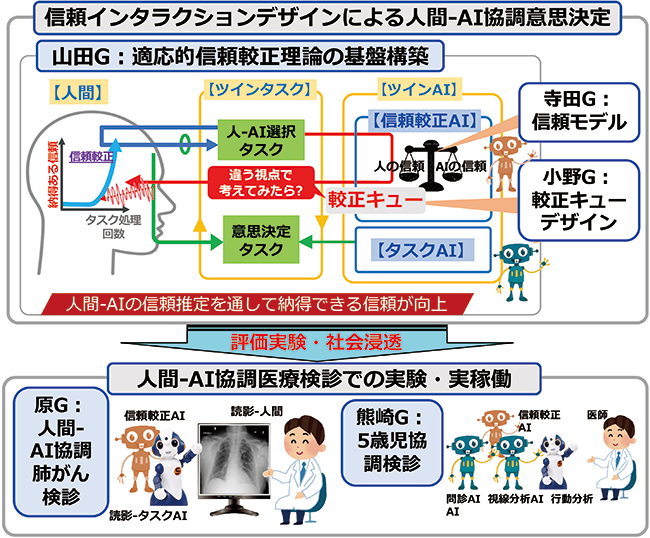
納得感のある人間-AI協調意思決定を目指す信頼インタラクションデザインの基盤構築と社会浸透
研究代表者:コンテンツ科学研究系教授 山田 誠二
利用するアルゴリズム、データや知識の質、量、バイアスなどにより、AI もよく間違いを犯す。しかし、ほとんどのエンドユーザは、思い込みや偏見からAI の性能を適正に評価できず、AI の出す解を闇雲に信じたり、あるいは拒否したりする傾向が強い。認知科学でアルゴリズム忌避(algorithm aversion)と呼ばれるこの現象は、人間-AI 協調思決定における本質的問題であり、その解決は信頼されるAI 実現にとってのグランドチャレンジである。この問題を解決し、人間-AI 協調意思決定がベストパフォーマンスを出すには、従来のようなAI 自体の性能向上を目指すだけでは難しく、人間とAI がインタラクションを通して、AI 性能を正確に評価可能になる信頼の最適化が必要である。
以上の背景から本プロジェクトでは、AI が人の認知バイアス、価値観を基に信頼関係の崩れ(過信/不信)を検出し、適応的に較正キューを出して信頼較正を促すことで、信頼関係を最適化し納得感を向上させる信頼インタラクションデザインの理論構築と医療検診による社会浸透を目指す。
人間-AI 協調意思決定では、自分で意思決定を遂行するか/ AI に任せるかを人間が決定、実行を繰り返す。そして、信頼較正AI が信頼モデルを基に人間とAI の信頼を計算し、その大小関係から決定する合理的選択と実際の人間の選択を比較、過信・不信を検知する。検知されれば、信頼較正を促す較正キューを表出する。人間は較正キューに反応して自らの意思で信頼較正を行うため、人は納得感を持って最適信頼を構築できる。
 NIIサービスキャラバン2026
NIIサービスキャラバン2026 NII Today No.107
NII Today No.107 国立情報学研究所 2026年度 概要
国立情報学研究所 2026年度 概要 情報研シリーズ 「ディープフェイク 生成AIとの共棲に向けて」
情報研シリーズ 「ディープフェイク 生成AIとの共棲に向けて」 NIIサービスニュース
NIIサービスニュース SINET広報サイト
SINET広報サイト ウェブサイト「軽井沢土曜懇話会アーカイブス」を公開
ウェブサイト「軽井沢土曜懇話会アーカイブス」を公開 SINETStream 事例紹介:トレーラー型動物施設 [徳島大学 バイオイノベーション研究所]
SINETStream 事例紹介:トレーラー型動物施設 [徳島大学 バイオイノベーション研究所] 学術研究プラットフォーム紹介動画
学術研究プラットフォーム紹介動画 教育機関DXシンポ
教育機関DXシンポ