ニュース / News
ニュースリリース
「くずし字」の認識に世界のAI研究者・技術者が挑戦
―全世界的コンペティションをKaggleで7月から開催―
日本は、古典籍、古文書、古記録などの過去の資料(史料)を千年以上も大切に受け継いでおり、数億点規模という世界でも稀なほど大量の資料が現存しています。日本の歴史・文化の研究や、過去の災害などの自然現象の解明を進めるには、これらの資料をデジタル化・オープン化するとともに、その内容を読み解く必要があります。ところが、現代のほとんどの日本人は「くずし字」で書かれた過去の資料を読めなくなっており、大量のくずし字をどう読み解くかが重要な課題となっています。
そこでこの社会課題の解決にAI(人工知能)を活用する方法を探るため、この7月から10月にかけて、世界最大規模の機械学習コンペプラットフォームである「Kaggle(カグル)」で、「くずし字認識:千年に及ぶ日本の文字文化への扉を開く」と題する全世界的なコンペを開催します。コンペを通して画期的なくずし字認識手法の開発が進むだけでなく、くずし字データセットを通して日本文化への関心が世界的に高まる効果も期待できます。
本コンペは、情報・システム研究機構 データサイエンス共同利用基盤施設 人文学オープンデータ共同利用センター(センター長:北本朝展、以下、CODH)ならびに同機構 国立情報学研究所(所長:喜連川優、以下、NII)、人間文化研究機構 国文学研究資料館(館長:ロバート・キャンベル、以下、国文研)が主催します。
日本は、古典籍、古文書、古記録などの過去の資料(史料)を千年以上も大切に受け継いでおり、数億点規模という世界でも稀なほど大量の資料が現存しています。日本の歴史・文化の研究や、過去の災害などの自然現象の解明を進めるには、これらの資料をデジタル化・オープン化するとともに、その内容を読み解く必要があります。ところが、現代のほとんどの日本人は「くずし字」で書かれた過去の資料を読めなくなっており、大量のくずし字をどう読み解くかが重要な課題となっています。
現在、くずし字をきちんと読める人は全国で数千人程度と推定されており(*1)、これらの人々だけで膨大な資料を翻刻(*2)するには限界があります。この課題を解決するために、2つの方向で研究が進められてきました。第一が市民参加型翻刻システム(*3)の開発です。専門家と市民が共に参加する翻刻システムを使い、市民がくずし字を翻刻しながらスキルを向上させることで、くずし字を読める人々の数をもっと増やすことを目指します。第二がコンピュータ(機械)の活用です。機械が文字を読み取る光学的文字認識(OCR)の活用による翻刻の自動化には、これまでいくつもの研究グループが取り組んできました。しかしくずし字は文字の種類が多く、連続した手書き文字の分割が難しく、レイアウトが多様で、本ごとにスタイルが異なるため、実用レベルのくずし字OCRの研究開発は難航しています。
一方、画像解析の分野における深層学習(機械学習)の活用を中心とした、近年のAIの飛躍的な発展を取り入れることで、新方式のくずし字OCRに向けた研究開発が進む可能性も高まっています。そこでくずし字OCRの性能向上に向けたアイデアをオープンに募集するため、CODH、NII、国文研は、この7月から10月にかけて、世界最大規模の機械学習コンペプラットフォームである「Kaggle(カグル)」(*4)で、「くずし字認識:千年に及ぶ日本の文字文化への扉を開く(Kuzushiji Character Recognition: Opening the Door to A Thousand Years of Japanese Literate Culture)」(*5)と題するコンペを開催します(図1)。
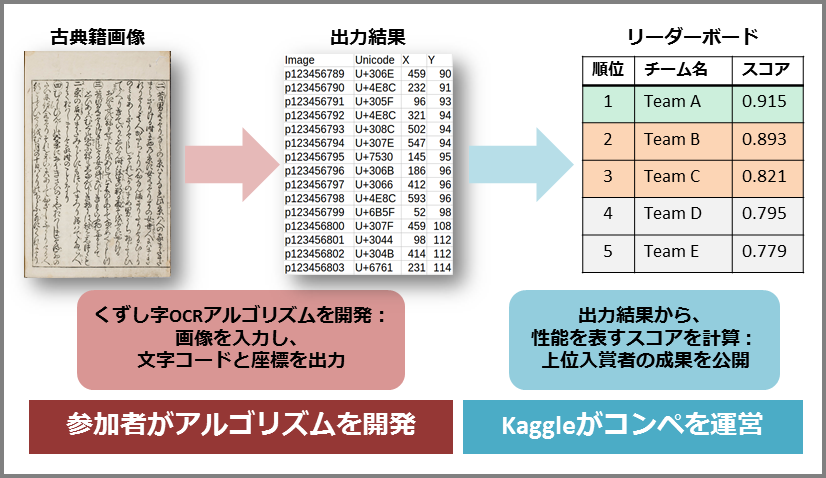
〈図1〉Kaggleコンペティションの流れ
このコンペでは、国文研がCODHと協力して整備し公開中の「くずし字データセット」をコンペ用に改良して提供します。参加者は、3ヵ月というコンペ期間内に、与えられた画像内に書かれたくずし字をすべて認識して出力する「くずし字OCRアルゴリズム」を開発します。そして上位に入賞したアルゴリズムは世界中で自由に使えるよう、コンペ後に公開する予定です。
くずし字認識に関するコンペとして、国内学会などが小規模に開催した例(*6)はありますが、今回は世界的な規模のコンペを開催するため、情報学の分野で世界的に知名度が高く、全世界300万人以上のAI研究者・技術者が参加するKaggleのプラットフォームを活用します。日本の組織によるKaggleコンペの開催はリクルート、メルカリに次ぐ3例目ですが、研究目的での開催は今回が初めてです。またKaggleの歴史の中でも、人文系データを対象とするコンペは今回が初めての開催となります。Kaggle社の関係者も「これまで開催された337件のコンペと比べても、本コンペは新しい領域を開拓するものであり、急速に進化するコンピュータビジョン技術の人気を踏まえれば、Kaggleコミュニティが興奮するようなコンペとなるだろう」とコメントしています。
コンペを通して画期的なくずし字認識アルゴリズムが見出せれば、AIによる翻刻支援や、AI文字認識を活用した全文検索など、過去の日本文化を読み解く新技術の研究開発が活発化することが期待できます。そして専門家の作業の一部をAIが支援できれば、専門家は資料の高度な読み解きに集中しやすくなります。このような新技術は、過去の資料を大規模にデジタル化・オープン化し、それを機械や市民が大規模に翻刻し、文理の研究者が過去の世界に関するデータを分析し、その成果を社会に還元するという、データ駆動型(*7)の日本文化研究を進めていく上で不可欠になると考えられます。
コンペに関する詳細な情報は、Kaggleウェブサイト上でコンペ開始日(7月中旬予定)から公開されます。参加者は、3か月後の10月に設定される締め切りまでにアルゴリズムを提出します。その後、主催者はKaggleと協力して入賞者(5位まで)を決定し、11月11日に東京で開催するシンポジウム「日本文化とAI」で表彰式を行う予定です。
参考資料
関連リンク
- Kaggle:「くずし字認識:千年に及ぶ日本の文字文化への扉を開く」
- 情報・システム研究機構 データサイエンス共同利用基盤施設 人文学オープンデータ共同利用センター(CODH)
- 人間文化研究機構 国文学研究資料館
ニュースリリース(PDF版)
「くずし字」の認識に世界のAI研究者・技術者が挑戦
―全世界的コンペティションをKaggleで7月から開催―
(*2) くずし字の翻刻とは、くずし字を人間が読み、くずし字に対応する現代日本語の文字を入力する作業のこと。
(*3) 「みんなで翻刻」(https://honkoku.org/)は、国立歴史民俗博物館の橋本雄太助教を中心に、京都大学古地震研究会や東京大学地震研究所などが協力して構築を進める、市民参加型翻刻システムのこと。CODHも各種の共同研究で協力体制にある。
(*4) Kaggle(https://www.kaggle.com/)は、米国に本拠地を置くKaggle社(Google傘下)が運営する、世界最大規模の機械学習コンペティションプラットフォーム。Kaggleのコンペティションでは、(1)企業や研究者が解決したい課題を出題し関連データを提供、(2)世界中のAI研究者・技術者がその課題を解決するアルゴリズム(計算手法)を提出、(3) 提出されたアルゴリズムの性能をランキングして上位入賞者を決定、(4) 上位入賞者はコンペの成果を出題者に提供し賞金を獲得、という流れで研究開発をオープンに進める。
(*5) Kaggleコンペに関する詳細情報については、下記のサイトで提供する。
本コンペのページ(https://www.kaggle.com/c/kuzushiji-recognition)※コンペ開始日に公開予定
CODHのウェブサイト(http://codh.rois.ac.jp/competition/kaggle/)
(*6) 第23回 PRMUアルゴリズムコンテスト くずし字認識チャレンジ2019 (https://sites.google.com/view/alcon2019)は、2019年5月31日から8月31日まで、電子情報通信学会パターン認識・メディア理解研究会が開催(CODH後援)。Kaggleコンペティションと同様のデータセットを用いるが、問題の難易度が異なる。
(*7) データ駆動型研究とは、機械学習(AI)による大規模処理なども活用しながら、(ビッグ)データの収集と分析から得られる証拠に基づき、新しい知見や知識を獲得することを目指す研究方法である。
※本発表は、情報・システム研究機構 データサイエンス共同利用基盤施設および国文学研究資料館との共同発表です。
 国立情報学研究所
国立情報学研究所 国立情報学研究所 2025年度 概要
国立情報学研究所 2025年度 概要 NII Today No.104
NII Today No.104 SINETStream 事例紹介:トレーラー型動物施設 [徳島大学 バイオイノベーション研究所]
SINETStream 事例紹介:トレーラー型動物施設 [徳島大学 バイオイノベーション研究所] ウェブサイト「軽井沢土曜懇話会アーカイブス」を公開
ウェブサイト「軽井沢土曜懇話会アーカイブス」を公開 情報研シリーズ これからの「ソフトウェアづくり」との向き合い方
情報研シリーズ これからの「ソフトウェアづくり」との向き合い方 学術研究プラットフォーム紹介動画
学術研究プラットフォーム紹介動画 教育機関DXシンポ
教育機関DXシンポ 高等教育機関におけるセキュリティポリシー
高等教育機関におけるセキュリティポリシー 情報・システム研究機構におけるLGBTQを尊重する基本理念
情報・システム研究機構におけるLGBTQを尊重する基本理念 オープンサイエンスのためのデータ管理基盤ハンドブック
オープンサイエンスのためのデータ管理基盤ハンドブック 教育機関DXシンポ
教育機関DXシンポ コンピュータサイエンスパーク
コンピュータサイエンスパーク