イベント / EVENT
平成23年度 第7回 Q&A
第7回 2012年1月18日(水)
言葉の意味を処理するとは?
コンピュータで言葉を理解する
宮尾 祐介(国立情報学研究所 コンテンツ科学研究系 准教授)
講演当日に頂いたご質問への回答(全53件)
※回答が可能な質問のみ掲載しています。
シソーラスとオントロジーはどう違うのでしょうか?
厳密な線引きは無いですが、シソーラスは同義関係や上位下位関係などの関係をグラフ構造でデータ化したもので、オントロジーはもっと複雑な関係や、関係の関係も含めてデータ化したものです。例えば、「食べる」の主語は人や動物で、目的語は食べ物である、という関係など。
a.「犬に風邪薬を飲ませると貧血状態になります。」と b.「ビーグルが風邪薬を食べたら病気になる。」は主体がヒトか犬で動詞も変える必要があるということでしょうか? もしaの文を「犬が主語の文に直しなさい」という問題が出た場合、bのように「飲ませる」→「飲む」ではなく、「飲ませる」→「食べる」に変換するということでしょうか?
そこまで深く考えていませんでした。単純に類義語の例として「食べる」と「飲む」を挙げましたが、「飲む」という動詞は主体が人である方が自然であるというのは確かです。このような「自然さ」をどうやって計算したらよいのかというのも意味処理の難しさの一つです。
「水を飲む」 「息を飲む」 同じ動詞でも全く意味が異なります。 これらもシソーラス・オントロジーで解決できるのでしょうか?
通常は、同じ単語でも異なる意味がある場合は、シソーラスの中で別の点として表されます(有名な例は英語の bank です)。ただし、「息を飲む」の場合は慣用句なので、「飲む」の意味の違いというよりは、「息を飲む」という句に特別な意味がある、というふうに扱って、別のシソーラスを使います。
コンピュータが意味を理解する時に、例えば「飲む」という言葉で、「人が口から体に何かを入れる」ということを理解していると言えるのでしょうか?
現状ではそこまでできているとは言えませんが、そこまで理解できるように現在研究を進めています。
p12「自然言語処理における「意味」とは何か?」のスライドの下図の説明をお願いします。 何の例えの図なのでしょうか? 何か理解しやすくする為の図だと思いますが、意味が分かりません。
「異なる文字列が同じ意味を表す」「同じ文字列が異なる意味を表す」を図で表したものです。一つの点が一つの文字列や意味を表しています。複数の点が一つの点に対応したり、一つの点が複数の点に対応する、ということで、数学的にはこの関係のことを「多対多の関係」といいます。
p20「構文解析の研究」のスライドについて
(1)日本語ではEnjuにあたるような解析機はありますか?
(2)90%の精度というのは統計的な処理だけでは出せない精度ですか?
(1)日本語の解析器は現在開発中です。(2)学習データを作れば統計的処理だけでも出せる可能性はありますが、学習データを作るためにはどういう正解データを作るべきかという理論が必要なので、どちらにせよ文法に相当するものが必要です。
宮尾先生のEnjuはチョムスキーの変形文法を使っていらっしゃるのですか?
主辞駆動句構造文法(HPSG)という文法理論を使っています。これは、チョムスキーの生成文法の流れをくんでいますが、変形文法ではありません。変形操作をしなくてもいろいろな文法構造を説明できるように工夫されたものです。
天気予報の文章のみを対象とした場合のEnjuのcover率(正解度)は100%に近いと思いますが、いかがですか?
現在公開している Enju は新聞の文を学習データとしているので、天気予報の文章がちゃんと解析できるかどうかは分かりません。そのような限られた文章を正しく解析できるようにチューニングすることは可能で、正解率を100%に近くできると思います。
例えば 「a.宮尾先生の犬は哺乳類である」「b.柴犬は哺乳類である」 aでは排他的になっても、bでは排他的でないような場合があるように、個別的な存在や状況を指す場合と、一般的な存在や状況を指す場合があると思いますが、その区別や関連に着目している研究やシステムは既にありますか?
言語学では昔から研究されていますが、自然言語処理では最近までほぼ無視されていました。文の意味を論理式に翻訳しようとすると避けて通れない問題なので、数年前からそのような区別を自動的に判別する研究が行われています。
ソーシャルIME経由でコーパスのデータを集めるといったことはNIIでも行われていますか? 小中学校の国語でe-learningが普及したら、その過程を記録することでコーパスに役立てることはできますか?
NIIでは行われていませんが、そのような研究は各所で行われています。教育は自然言語処理の重要な応用の一つなので、そのようなコーパスを利用した研究も行われています。
対応言語は日本語のみですか?
含意関係認識の研究の件でしょうか?自然言語処理の研究は英語を中心にたくさんの言語で行われています。今回ご紹介したセンター試験の問題を解くというチャレンジは今のところ日本語だけです。
レジュメ42p「大学入試にチャレンジ」 、45p「評価結果(試験の正答率)」のチーム・システムについて。結果の違いはアルゴリズムの差ですか?学習させてコーパスの量等の条件は同一にしているのですか?講義の内容、ご説明ともとても面白く、分かりやすかったです。ありがとうございました。
学習データは共通です。アルゴリズムの差と、学習データ以外のデータの差があります。例えば、日本語語彙体系のような既存のシソーラスを使っているシステムもあれば、Wikipedia から自動獲得したシソーラスを使っているシステムもあります。
日本語は英語に比べて色々な組み合わせで文を構成させることができますが、日本語の構文解析技術はどのくらいまで進んでいますか?
英語:Enju → 90%の精度で解析できている。
日本語:? → ?%
日本語もだいたい90%くらいです。英語と日本語は構文的な手がかり(助詞や活用などの文法構造を決める単語や特徴)が多いので、他の言語に比べると構文解析の精度は高い方です。
日本語特有の自然言語処理の課題を教えて下さい。
構文解析関係では、省略解析があります。日本語では主語やトピックが省略されることが多く、どこが省略されていて何が省略されているのかを認識するのは難しい課題です。
英文と日本文での構文解析の最も大きな違いは?
歴史的な経緯で、英語では句構造(名詞句や文などの句のかたまり)を解析する研究が多く、日本語では係り受け構造(文節と文節の係り受け関係)を研究することが多いです。ただし、最近は英語でも係り受けを対象とした研究が増えていて、メジャーになりつつあります。
日本語のほうが英語より難しいですか?(逆に漢字とかがあるので語彙的意味は捉えやすいですか?構文的にも助詞があったほうが捉えやすいですか?)
英語と日本語は、構文を計算する手がかりがあるので、他の言語に比べると構文解析が簡単な方です。英語と日本語で手がかりの形は違いますが、両方ともだいたい90%くらいの精度で解析できます。
言語をコンピュータで認識するために、
(1)最初に音声信号を単音として認識する方法は?
(2)単音の組み合わせで単語を判別する方法は?
(3)単語の組み合わせで句を判別する方法は?
(4)句の組み合わせで完結した文を判別する方法は?
(5)扱う語が何語かはマニュアルで指定するのか、その文章の中に他の語句が引用されている場合の判別方法は?
(1) (2) は専門外ですが、隠れマルコフモデルなどの統計的手法を使って認識するようです。単語列とそれを発音したデータがあれば、現在の技術では高い精度で認識できます。(3) (4) は構文解析の問題で、文法と確率モデルによる曖昧性解消を組み合わせて解析します。(5) は自動判別する研究が進んでいて、機械翻訳サービスなどで利用されています。
含意判定は日英どちらが進んでいますか?
今までは主に英語で研究が進められていたので、今のところ英語の方が進んでいます。日本語で今回のような評価が行われたのは初めてのことですが、シソーラスなどのデータはたくさん揃っているので、これから研究が進むと期待されます。
文章の中にある「これ」「それ」「あれ」などの言葉が何を指しているかはどうやって計算するのですか?
これは省略解析と並んで難しい問題で、今も研究中です。いろいろな手がかり(例えば、「これを食べる」と言ったら「これ」は食べ物らしいとか)と、機械学習を使います。機械学習の使い方は、構文解析の曖昧性解消とだいたい同じです。
言葉は文字の他に音声による表現もありますが、疑問文が音声による場合はどのように判断するのですか?
専門外なので詳しいことは分かりませんが、音声のピッチやイントネーションを計算する方法がいろいろあるようです。
ボイスシステム(音声認識)において、不特定話者と特定話者がありますか? 不特定話者の精度、レベルはどれくらいですか?
専門外なので詳しいことは分かりませんが、不特定話者の場合はまだまだ難しいようです。単純に音として解析するのは限界があり、人間は音声の意味内容を含めて認識しているようなので、これからそういう研究が必要になると思われます。
計算された意味が妥当であるかは人間が判断すると思いますが、その基準は明確に決まっていますか?
いろいろな基準がありますが、人間がその基準に沿って判断しても100%一致するとは限りません。これは難しい問題ですが、「ある程度一致する」ような基準を作ることで妥協しています。
(1)言葉の意味をコンピュータで処理する際に他言語に比べて日本語に特徴的な難しさ、易しさ、性質などはありますか?
(2)コンピュータで処理しやすい、またはしにくい言語はありますか? その原因は何ですか?
(1)構文解析は、日本語は助詞や助動詞のおかげで比較的簡単です。しかし、省略が多いので、構成的意味の計算は少し難しいです。語彙的意味については日本語は研究が進んでいる方ですが、それでもまだ十分な意味処理ができていないのが現状です。(2)私が今まで対象にした言語では、中国語は単語区切り、品詞、構文解析のいずれも難しいです。助詞や活用がなく、同じ漢字が名詞や動詞や形容詞などいろいろな品詞で使われるからと思われます。私は直接研究したことが無いので詳しくは分かりませんが、他にもノルウェー語やドイツ語のように活用や語構成が複雑な言語は解析が難しいようです。
現在、自動翻訳で最も障壁となっている点をご教授下さい。 完璧な自動翻訳は何年後くらいに実現するのでしょうか?
英語とフランスとか、日本語や韓国語のように語順がある程度似ていて文法や単語の使い方も似ている言語ではかなり精度の高い翻訳ができます。これはある程度逐語訳でもよいからと思われます。日本語と英語のように語順や文法、単語や言い回しが全く違う言語では、まだまだ難しい問題がたくさんあります。今の機械翻訳技術は意味解析までやっていないので、単語や言い回しの意味に曖昧性がある時に、翻訳がうまくいかないことがよくあります。このような言語における完璧な自動翻訳は、別の言語で文章を作りなおす作業にほぼ等しいので、自動翻訳が完成するのは自然言語処理が完成するのと同じ時で、はるか先のことと思われます。
シソーラス・オントロジーを大量のテキストから自動獲得でき、同一内容の英文と日本文が大量にあるならば、機械翻訳はできるのではないでしょうか?特許公報において、同一内容の日本出願とアメリカ出願があります。
機械翻訳では、単に単語を逐語訳するだけではない難しさがあります。極端な例ですが、電車で「電車とホームの間が広く開いておりますのでご注意ください」というアナウンスを英語に翻訳すると、"Mind the gap" となります。これはそれぞれの言語・文化で同じことをどのように表すかが違うということで、講演で紹介したような意味処理だけでは解決できない問題です。特許の翻訳はさかんに研究されていて精度も上がってきていますが、まだ完全には遠いです。
(1)主観的な言葉の意味(例えば「かわいい」)はどう扱うのですか?(2)機械学習で精度を上げる手法は「理解」をブラックボックス化(=論理を再現・検証できない)しつつあるのではないでしょうか?
(1) 現在の意味解析技術では主観・客観の区別は特にしていません。「かわいい」という文字列をどういう時にどういう単語と置き換えることができるか、というこをと考えます。この方法だと当然限界があるので、別のアプローチを採っている研究もあります。(2) 現在の自然言語処理がそうなっているのは否めません。以前は「理解」をまじめに再現しようとしてうまくいかなかったので、今はいかに「理解」の問題を回避して実用的なシステムを作るかが焦点となっています。しかしそれでだんだん行き詰ってきていると多くの人が感じているので、また「理解」の問題をまじめに考えようとしている人たちもいます。
言葉の理解は機械知の精度を上げる(ロジカルツリーを増やす)事が分かりました。無限定情況における創造的な知についての研究はどこまで進んでいるのでしょうか? 機械学習にはある程度反映されているのでしょうか?
言語理論的研究はありますが、自然言語処理への応用はまだされていません。意味理解の仕組みがある程度明らかにならないと創造性にアプローチすることすら難しいと思います。機械学習は過去の事例のどれに似ているかで未来を予測する技術ですから、過去に起きなかったことは全く予測できません。
(1)今、検索語などで利用できるグーグルなどのサービス(英和)はどのような方法を利用しているのでしょうか?
(2)現在、確度の高い翻訳ソフトの例(英和)を挙げて下さい。
(1) Google, Yahoo, Microsoft などで機械翻訳サービスが提供されていますが、主に機械学習に基づく方法(統計的機械翻訳)と、詳細な規則を駆使している方法(ルールベース・用例ベース)があります。どれがどういう手法を使っているかは明らかになっていない部分もありますし、複合的に使っている場合もありますので、一概には言えません。(2) 商用のものは精度が高いものが多いですが、まず Google, Yahoo, Microsoft あたりを使ってみて比較してみると面白いと思います。特徴がかなり違うので、10文くらい試してみると、どのシステムが良さそうか分かると思います。
無料で自由に使えるシソーラス、オントロジー電子辞書は日本にないのでしょうか?
言葉は生き物であって、例えば「やばい」という表現は使う人や状況、時代、地理的要因によってもそれぞれ意味が異なります。 そういう言葉をどのような形式で記録しておけばよいのでしょうか?
日本語ワードネットは無料で公開されています。
http://nlpwww.nict.go.jp/wn-ja/
言葉の意味の変化や個人差については難しくてまだほとんど何もできていませんが、インターネットでブログやツイッターなどが広まり、いろいろな世代、地域、状況の人の生の発言が処理できるようになってきたので、これから研究が広まる可能性があります。
単語の「意味辞書」の開発状況は現時点でどうなっているのでしょうか? 開発状況は公開されていますか?
日本では ALAGIN Forum というグループが大規模な意味辞書を開発して公開しています。
http://www.alagin.jp/
(1)機械翻訳は意味を理解せずに構文解析とシソーラスだけで成り立っているのですか? 機械翻訳ソフトに意味理解機能が入れば翻訳精度は向上しますか?
(2)構文解析の「精度」(パワーポイントではP20の90%)の定義は何ですか?
(1) 「意味を理解する」というのがどういうことなのかをまず考える必要があります。講演で紹介した構文解析とシソーラスを使う方法も、意味を理解することの一つのアプローチです。それ以上の意味処理(というのが何を指すかによりますが)がまだできていないというのはそのとおりです。また、上でも述べたとおり意味を理解しただけでは解決できない問題もあります。(2) 講演で紹介した数字は、述語と項の関係(グラフ表現における一つの辺)がどれだけ正解と合っているかの割合です。
自然言語処理において外国語の翻訳でどこまで道義性を表現できるのでしょうか?異言語の構造の差はどこまで埋まるのでしょうか?
表面的な意味だけではなく感情や立場などを解析する研究はされていますが、意味処理や機械翻訳などにはまだ応用されていません。異言語の構造の差は最近10年程度で飛躍的に技術が進歩し、例えば英語と日本語の翻訳では構文的な差はあまり問題にならなくなりつつあります。しかし、それ以外の差(単語や言い回しの使い方、考え方の差など)はまだ残っています。
"大学入試問題を解く"について。 あえて歴史、政経、現社をターゲットにしたのは英語や国語は(コーパスや構成解析を用いれば)楽勝だからですか?
逆です。おそらく一番難しいのは英語と思われます。これはコンピュータは英語が苦手だからではなく、英語の問題はたくさんの常識を前提としているからです。国語も同様の問題で難しいと思われます。英語、国語については現在分析を進めています。
大学入試は日本人にとって分かりやすい題材だと思いますが、海外向けにアピールする際にも通用するものでしょうか? 米SATやGREなど他国の同様の試験システムでも置き換えできるでしょうか?(今回の講座内容と直接には関係しませんが、IBMのWatsonプロジェクトも米国特有のクイズ番組に挑戦したものでした)
アメリカ、ヨーロッパ、中国の研究者はとても面白がっていたそうです。日本の大学入試で出る問題とSAT, GREは違う部分も多いですし、社会的なとらえられ方も違いますが、自然言語処理の研究題材としてはいずれも興味深いものです。
IBMのコンピュータ、ワトソンはどうしてクイズ王に勝つことができたのでしょうか。
クイズに勝つためには、知識をたくさん持っていることと、知識をうまく引き出すことが必要です。前者は、コンピュータの方がはるかに勝っています。ポイントは後者で、検索のような単純な引き出し方では明らかにコンピュータの方が勝っていますが、もっと自然な質問に対してどうやって適切な答えを探すのかが問題です。これは質問応答システムといって昔から自然言語処理で研究されてきたテーマですが、ワトソンはいろいろな技術を駆使してうまく情報を検索することができたのでクイズ王に勝つことができたと言えます。例えば、一般の人でもインターネットにアクセスできて検索する時間を十分もらえれば、どんなクイズ王にも勝てるはずです。
センター試験の入試を解く時間はどの位かかっていますか? 実用にたえる時間ですか?
手法によりますが、今回紹介したシステムの多くはそんなに時間はかかっていないと思います。一問数秒くらいです。
自然言語処理、論理について。 解析的アプローチとは別にもっと「学習的」なアプローチはないのでしょうか? ヒトは生まれた後、学習で言語を獲得するのではないでしょうか。
学習するためにはルールが必要です。例えば、猫がネズミを追いかけているのを見た時、何を学習するでしょうか?猫の毛の数とかネズミの指の数とかを学習することはないと思います。猫がネズミを追いかける場面を見た時に得られる情報は無限にありますが、その中で何を取捨選択して「学習」するのか、人間にとっては自明ですがコンピュータにとってはそうではありません。人間が何を取捨選択してどのように記憶しているのか、そのルールが分からないと、コンピュータが人間のように「学習」することはできません。そのルールの一部が文法や論理です。解析的なアプローチと学習的なアプローチは表裏一体で、解析的なアプローチがもっと進めば必然的に学習的なアプローチも可能になってくると思います。
(1)今回は標準語を例に挙げられましたが、方言など特殊な言語の場合はどのように分析できますか?
(2)赤ちゃんが発する言葉などを分析して意味を持つことができますか?
(3)コンピュータが言葉を理解できるとしたらコンピュータ自身が独自の思想を持って発言が可能でしょうか?障壁になるものにはどういうものがあるのでしょうか?
(1) コンピュータの立場に立ってみると方言と標準語に違いはありません。日本語と英語も大して違いません。同じような手法が適用できると思います。(2) 赤ちゃんが発する言葉に何か意味があるのであれば、将来的にはできると思います。専門外なので詳しくは知らないですが、そのような研究もされているようです。(3) 言葉を理解することと自分で発言することの間には隔たりがあります。発言をするということは何か目的を持っているということですが、目的は言葉が伝える意味とは別のものです。例えば大学入試に限れば目的は明らか(問題に答えること)なのでそれに向かってコンピュータが考えて答えを出すことは可能ですが、一般的な場面でそれができるかどうかはまた別の問題です。
意味は言葉以外に表情や態度が含まれますが、どうやってコンピュータに理解させるのでしょうか?
専門外なので詳しいことは分かりませんが、表情や態度をある程度類型化・数値化して、それをコンピュータに当てさせるという手法だと思います。構文・意味解析の曖昧性解消と同じようなアプローチですが、表情・態度の場合はまずどのように類型化・数値化すればよいのかが自明でないので、いろいろな研究者が研究を進めているところです。
言語処理の技術で感情をコンピュータに理解させることはできますか?
例えば、自然言語テキストから感情を読み取る研究はあります。しかし、何をもって「感情を理解した」と言えるのかは難しい問題で、何をもって「意味を理解した」と言えるのかというのと同様の問題です。
構文解析では、文学的あるいは詩的、情緒的な表現はどんな風に扱うのでしょうか?
構文解析というレベルでは、新聞や論文の解析とそんなに違いはありません。構文解析は文の構造を解析するのが目的で、文学や詩の深い意味まで解析するものではないからです。文学などに特有の表現はありますが、それはルールが少し違うだけなので、基本的には同じような手法が適用できます。
俳句、短歌などの文学作品の理解をどのように構築するのでしょうか?
文学的なテキストを対象とした研究はありますが、まだそれほど研究は進んでいません。まず表面的な意味が理解できないと始まらないという面があります。表面的な意味が理解できたら、その意味を理解した時に自分の経験や知識と組み合わせて、自分の中に新たに意味や状況を作り出すのではないかと思っています。つまり、表面的な意味がきっかけとなって、読んだ(聞いた)人の中に何かを作り出すということです。この仕組みは興味深いですし、大学入試のプロジェクトでも将来的に必要になりそうなので、これから考えていきたいと思っています。
短歌や俳句はそれ自体はわずかな字数で構成されますが、その解説文は大変な字数になっています。コンピュータにもそういう解説文が書けるのでしょうか?
上の回答をご覧ください。人の中に作られる意味・状況を再現できるようになったら、解説文も書けるようになると思います。
知財関係の仕事をしています。 特許調査の概念検索クエリベクトルは今回の講義の意味計算を利用したものでしょうか?
だいたい同じですが、構成的意味はあまり使っていないと思います。
文脈から「うそ」は見抜けるのでしょうか?
テキストを見ただけで「うそ」を見抜けるかどうかというのがまず問題です。矛盾があるかどうかや不自然かどうかは検出することができると思いますが、完璧なうそは(人間でも)見抜けないと思います。
(1)一文でなく、文章になれば複雑さは格段に大きくなりますが、基本的なアプローチは同じでしょうか?
(1) 文の構文・意味解析を行った後に、文脈解析・談話解析という処理をします。アプローチは似ていますが、文法のようなはっきりした規則性が無い場合が多いので、もっと難しいです。
自然言語の理解から世界の違った言語の互いの理解(瞬間的翻訳)が可能にならないでしょうか。
将来的には可能になると思いますし、自然言語処理研究者はそれを目指しています。違った言語に限らず、同じ日本語でも世代や仕事によって使う言葉がだいぶ違いますので、そういう人たちの間でもよりよいコミュニケーションが実現できるようにしたいと思っています。
頭の中で考えたことを(脳波などの情報を使って)そのままコンピュータに文章にしてくれることができないでしょうか。文章をタイプなどで入力することをやめたいので...
詳しいことは分かりませんが、そのような研究をしている人がいます。考えたことがすぐに文章になってしまうと、本当に便利かどうかは分かりませんが...
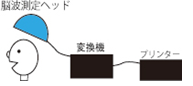
このようなシステムは現在どこまで進んでいますか? 実用化はいつ頃ですか? ヘッドは筋萎縮症等で信号をキャッチできるまでに。これを個々の人間にあてはめて考えられる。脳信号を変換してプリンターを動かす。問題は変換で。将来留置人の自白、ウソを脳でとらえることができる。(警察官は失業してしまいますが。)物書きがペンでなく、頭で考え、思いをプリンターから出せる。コードレスにすれば動いている中でもできるのでは。
考えたことをそのまま文章にしたらおそらくとても意味不明な文章になると思いますが、そのような研究は徐々に進んでいるようです。しかし脳波と言う物理的な世界と、言葉の意味の世界の隔たりは大きく、両側から少しずつ研究が進められていますが、実現するのはもう少し先のことになりそうです。
先生のビーグル犬メイちゃん(メス)にどのぐらいの量の風邪薬を飲ませると貧血状態になるのでしょうか? 全くメイちゃんには風邪薬は飲まさないのですか?(講義の内容とはあまり関係がないので、カットしてもらってもかまいません。)
そもそも犬は風邪をひかないそうで、人間用の風邪薬のある成分が犬にとっては毒なんだそうです。おそらくタマネギのようなものなのだと思います。
構成的意味と語彙的意味の相互作用で意味(意図?)を判断しているということが印象に残った。いずれは意味を理解した結果、何かしらの意思を持つコンピュータもできるのでしょうか?
意味と意思は別のものと思います。言葉の意味は目的が無くても理解できますが、目的のない意思はありません。例えば、対話は意味が分かっても意思が無いと成り立ちません。将来的には、自然言語処理システムには意思を持たせないといけないと思います。
「友達とケーキを食べた」「せんべいとケーキを食べた」 この違いを「学習データ」蓄積で分かりますか?
友達、先生、のび太、などは近くて、せんべい、ケーキ、お好み焼き、が近い、というのはデータを蓄積することで分かります。これが分かると、「友達とケーキを食べた」と「せんべいとケーキを食べた」の違いが分かるようになります。
 NIIサービスキャラバン2026
NIIサービスキャラバン2026 NII Today No.107
NII Today No.107 国立情報学研究所 2026年度 概要
国立情報学研究所 2026年度 概要 情報研シリーズ 「ディープフェイク 生成AIとの共棲に向けて」
情報研シリーズ 「ディープフェイク 生成AIとの共棲に向けて」 NIIサービスニュース
NIIサービスニュース SINET広報サイト
SINET広報サイト ウェブサイト「軽井沢土曜懇話会アーカイブス」を公開
ウェブサイト「軽井沢土曜懇話会アーカイブス」を公開 SINETStream 事例紹介:トレーラー型動物施設 [徳島大学 バイオイノベーション研究所]
SINETStream 事例紹介:トレーラー型動物施設 [徳島大学 バイオイノベーション研究所] 学術研究プラットフォーム紹介動画
学術研究プラットフォーム紹介動画 教育機関DXシンポ
教育機関DXシンポ