News
News Release
Full-Scratch Learning of a Large Language Model with Approximately 172 billion Parameters (GPT-3 Level) and Preview Release
- The World's Largest Fully Open Model, Including Training Data -
The Research and Development Center for Large Language Models (LLMC) at the National Institute of Informatics (NII) (Director-General: KUROHASHI Sadao, Chiyoda-ku, Tokyo, Japan), part of the Research Organization of Information and Systems, has successfully conducted a full-scratch learning of a large language model (LLM) with approximately 172 billion parameters (*1) (GPT-3 level). This is an achievement of the NII-led LLM Research Group (LLM-jp), building upon previous achievements such as the training of a 13 billion parameter model on the mdx(*2) Platform for Building Data-Empowered Society, and the trial learning of a 175 billion parameter model using the AI Bridging Cloud Infrastructure (ABCI) with support from the 2nd Large-scale Language Model Building Support Program of the National Institute of Advanced Industrial Science and Technology.
The preview version of the model has been released, and it is the world's largest fully open model, including its training data.The preview version has completed learning on approximately one-third of the prepared training data, which consists of around 2.1 trillion tokens. The plan is to continue learning and release the fully trained model around December 2024.
LLMC aims to promote research and development to ensure the transparency and reliability of LLMs, leveraging this and previously released models.
1.Overview of the Released LLM
(1) Computing Resources
- Approximately 0.4 trillion tokens of pre-training were conducted using cloud resources provided by Google Cloud Japan under the support of the Ministry of Economy, Trade and Industry's GENIAC project.
- Subsequently, up to about 0.7 trillion tokens of pre-training and tuning were carried out using cloud resources from SAKURA Internet, procured with a grant from the Ministry of Education, Culture, Sports, Science and Technology (MEXT).
(2) Model Training Corpus(*3)
- The corpus consists of approximately 2.1 trillion tokens, with pre-training completed for about one-third.
- Japanese : About 592 billion tokens
- Text extracted from the full Common Crawl (CC) archive in Japanese
- Data crawled from websites based on URLs collected by the National Diet Library's Web Archiving Project (WARP), with URL lists provided by the Library
- Japanese Wikipedia
- The summary text of each research project in the KAKEN (Database of Grants-in-Aid for Scientific Research).
- English : About 950 billion tokens (Dolma, etc.)
- Other languages: About 1 billion tokens (Chinese and Korean)
- Program code: About 114 billion tokens
- These add up to around 1.7 trillion tokens, and approximately 0.4 trillion Japanese tokens are to be used twice, resulting in about 2.1 trillion tokens
- Japanese : About 592 billion tokens
(3) Model
- Number of parameters: Approximately 172 billion (172B)
- Model architecture: LlaMA-2 based
(4) Tuning
- Tuning experiments were conducted using 13 types of Japanese instruction data and translations of English instruction data.
(5) Evaluation
- The model was evaluated using "llm-jp-eval v1.3.1," a cross-evaluation framework developed by LLM-jp, based on 22 types of existing Japanese language resources. The pre-training model, trained on 0.7 trillion tokens, achieved a score of 0.548.
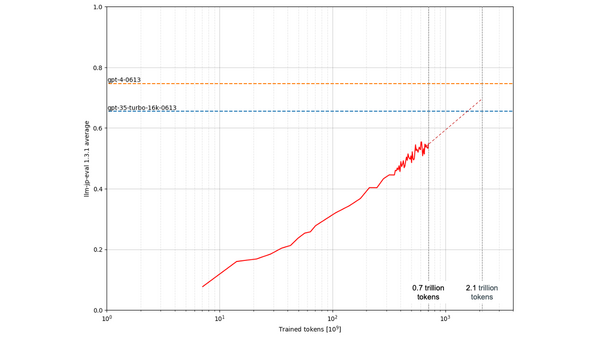
- It was also evaluated using the "llm-leaderboard (g-leaderboard branch)," a framework used for performance assessment in the GENIAC project. The tuning model trained on 0.7 trillion tokens achieved a score of 0.529.
(6) URL for the Released Model, Tools, and Corpus
- https://llm-jp.nii.ac.jp/en/release
- Note : Although the released model has undergone tuning for safety, it is still in the preview stage and not intended for direct use in practical services. The preview version will be provided under a limited license to approved applicants.
2. Future Plans
- To effectively utilize LLMs in society, ensuring transparency and reliability is essential. Additionally, as models become more advanced, safety considerations will become increasingly important. In response, NII established the Research and Development Center for Large Language Models in April 2024 with support from MEXT's project "R&D Hub Aimed at Ensuring Transparency and Reliability of Generative AI Models" (P7,https://www.mext.go.jp/content/20240118-ope_dev03-000033586-11.pdfのp.7, In Japanese). NII will continue to promote research and development using the released models and those yet to be built, contributing to the advancement of LLM research.
- With regard to the model released this time, all checkpoints up to the final checkpoint (100k steps), including every 1k step along the way, are saved and will be made available.
(Reference 1) Overview of LLM-jp
- LLM-jp, organized by NII, consists of over 1,700 participants (as of September 17, 2024) from universities, companies, and research institutions, mainly focusing on researchers in natural language processing and computer systems. LLM-jp shares information on LLM research and development through hybrid meetings, online sessions, and Slack, while also conducting joint research on building LLMs. Specific activities include:
- Promoting the development of open LLMs proficient in Japanese and related research.
- Regular information exchange on model building expertise and the latest research developments.
- Fostering collaboration across institutions by sharing data and computing resources.
- Publishing outcomes such as models, tools, and technical documentation.
- LLM-jp has established working groups such as "Corpus Construction WG," "Model Construction WG," "Fine-tuning & Evaluation WG," "Safety WG," "Multi-modal WG" and "Real Environment Interaction WG." Each group, led respectively by Professor Daisuke Kawahara of Waseda University, Professor Jun Suzuki of Tohoku University, Professor Yusuke Miyao of the University of Tokyo, Project Professor Satoshi Sekine of NII, Professor Naoaki Okazaki of Tokyo Tech, and Professor Tetsuya Ogata of Waseda University, is engaged in research and development activities. Additionally, the initiative is propelled by the contributions of many others, including Professor Kenjiro Taura of the University of Tokyo, Associate Professor Yohei Kuga of the University of Tokyo (for utilization technologies of computational resource), and Professor Rio Yokota of Tokyo Tech (parallel computation methods).
- For more details, visit the website: https://llm-jp.nii.ac.jp/
(Reference 2) Support for This Achievement
This achievement was made possible through a grant from the New Energy and Industrial Technology Development Organization (NEDO) and MEXT's subsidy.
Links
- Research and Development Center for Large Language Models
- Introduction of the "LLM-jp"(In Japanese) - YouTube
- GENIAC - Ministry of Economy, Trade and Industry
- mdx: a platform for building data-empowered society
- Development of the Large Language Model "LLM-jp-13B" with 13 Billion Parameters ~The NII-hosted LLM Study Group (LLM-jp) releases initial results to contribute to academic and industrial research and development ~ - NII News Release(2023/10/20)
- Research and Development Center for Large Language Models Established at National Institute of Informatics - Accelerating R&D to Develop Domestic LLMs and Ensure Transparency and Reliability of Generative AI Models - NII News Release(2024/04/01)
- Development of the Large Language Model "LLM-jp-13B v2.0"
- The NII-hosted LLM Research Group (LLM-jp) releases the successor model of "LLM-jp-13B," and makes all resources used for development open for the public - NII News Release(2024/04/30)
News Release: PDF
(※2) mdx (a platform for building a data-empowered society):A high-performance virtual environment focused on data utilization, jointly operated by a consortium of 9 universities and 2 research institutes. It is a platform for data collection, accumulation, and analysis that allows users to build, expand, and integrate research environments on-demand in a short amount of time, tailored to specific needs.
(※3) Corpus:A database that stores large amounts of natural language texts in a structural manner.
SPECIAL
 Summary of NII 2024
Summary of NII 2024
 NII Today No.104(EN)
NII Today No.104(EN)
 NII Today No.103(EN)
NII Today No.103(EN)
 Overview of NII 2024
Overview of NII 2024
 Guidance of Informatics Program, SOKENDAI 24-25
Guidance of Informatics Program, SOKENDAI 24-25
 NII Today No.102(EN)
NII Today No.102(EN)
 SINETStream Use Case: Mobile Animal Laboratory [Bio-Innovation Research Center, Tokushima Univ.]
SINETStream Use Case: Mobile Animal Laboratory [Bio-Innovation Research Center, Tokushima Univ.]
 The National Institute of Information Basic Principles of Respect for LGBTQ
The National Institute of Information Basic Principles of Respect for LGBTQ
 DAAD
DAAD