Sep. 2024No.103

Interview
人工知能法学とLLM
データサイエンス共同基盤施設人工知能法学研究支援センターは「人工知能(AI)による法学研究支援」と「法によるAI制御」の研究を進めている。本稿では、LLMの活用と、技術開発の上に規制はどのようあるべきなのか、という点を中心に佐藤健教授、西貝吉晃准教授に話を聞いた。

佐藤 健SATOH, Ken
データサイエンス共同基盤施設
人工知能法学研究支援センター長
国立情報学研究所 名誉教授

西貝 吉晃NISHIGAI, Yoshiaki
千葉大学 大学院社会科学研究院 准教授
データサイエンス共同基盤施設 人工知能法学研究支援センター 客員准教授
(敬称略)
――人工知能法学の概要とLLMとの関係について
佐藤 人工知能法学は、1.AIの技術を使って、法学研究を支援するLaw (supported) by AI、2. 法によるAIの制御、Law (control) of AI、この2つを柱とする研究です。人工知能法学研究支援センターは、人工知能法学を支援するために2023年11月、データサイエンス共同利用基盤施設(ROIS-DS)に設置され、私がセンター長を務めています。私は法科大学院を修了したり司法試験に合格していますが、基本的にはAIの研究者なので、主にAIで法学を支援するLaw by AIの研究をしています。AIの制御に関する研究については、西貝先生はじめ、法学について深い知識を持たれてる先生方等に加わっていただき、研究を進めています。
生成AI登場後も研究テーマ自体が変わっているわけでなく、さまざまな問題をLLMを活用することでより良く解決するためにはどうしたらよいかという観点からも研究しています。つまり、LLMを前提として法学支援をするということではなく、LLMを適材適所で使っていくという方針です。
――AIによる法学研究支援について
佐藤 AIによる法学研究支援=Law by AIでは、主に民事裁判における、法律専門家の判断支援するツールとして、判決推論システム「PROLEG(プロレグ)」の研究開発を中心に行っています。
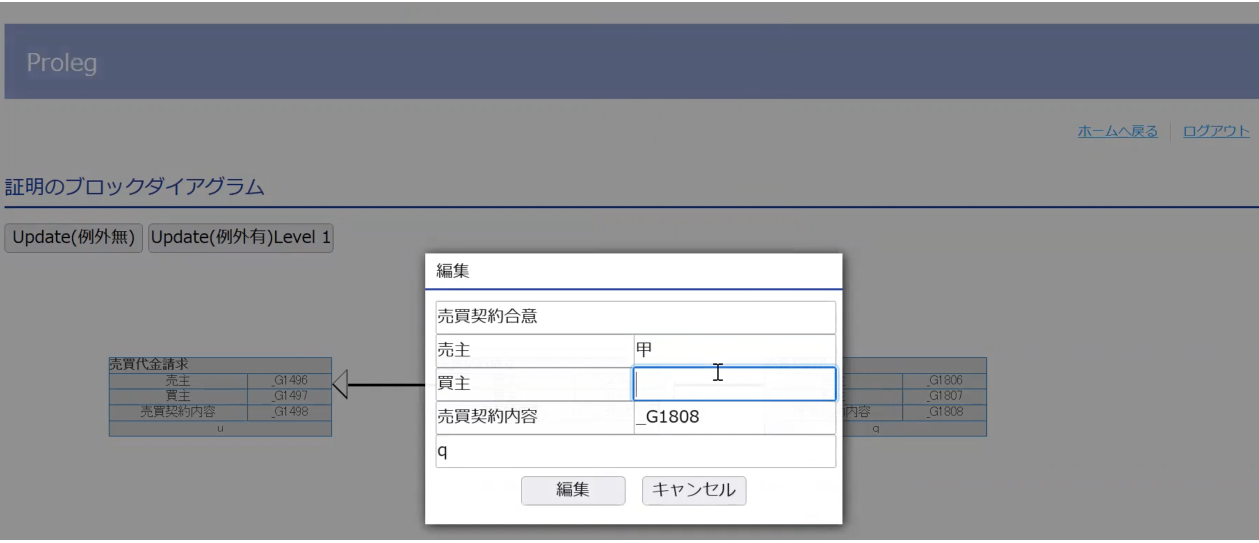
PROLEGは裁判官が法的事実を確定した時に、民法のルールで判決をシミュレーションするシステムです。図1は、そのようなシミュレーションの結果を図形式であらわしたものです。PROLEGの応用としては、例えば訴状に必要十分な内容が記載されているかどうかチェックすることができます。また民法の「要件事実論」は各要件のデフォルト値をあらかじめ決めておく理論で、原則と抗弁、抗弁と再抗弁など、論理的には複雑ですが、PROLEGで書くと分かり易いという利点があります。ただ、弁護士が原告と被告に分かれてやり取りする仕様ではなかったので、改訂し、表形式で段階的に議論を作っていくことができるようにしました。図2は、ある法的事実を入れる場所をシステムが示して、弁護士が適切な値を入れていくことにより議論が構築されます。しかし、実際に使ってもらった弁護士の方から、表の各要素に値を入れるというところについて、どこに何を入れたらいいか分かりにくい―ということ指摘を受けたため、言語モデル登場後、文章から、どの要素がどの部分の値になるかを自動的に生成することにより弁護士が表に値を入れずにすむ改良を行なっているところです。
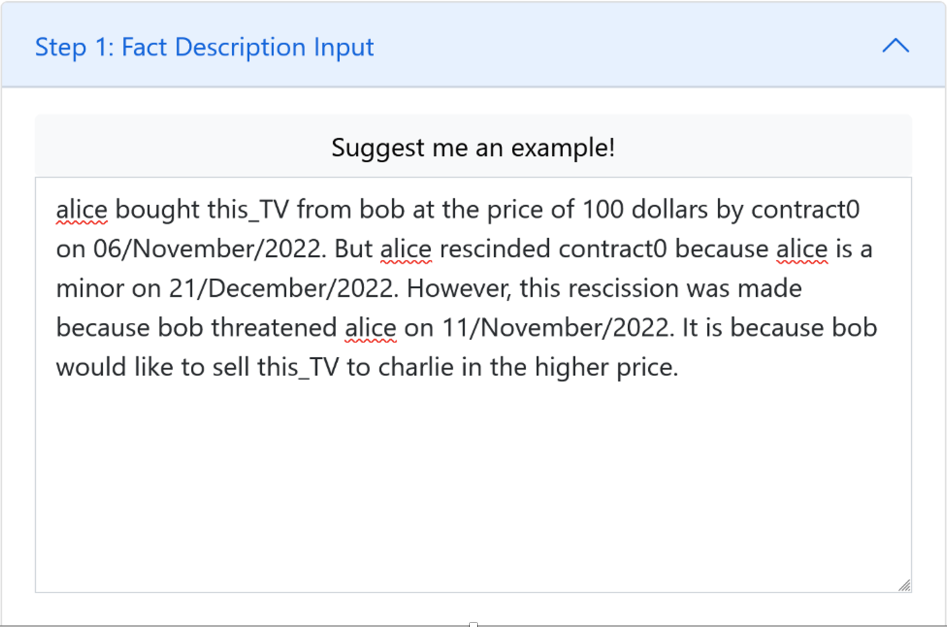
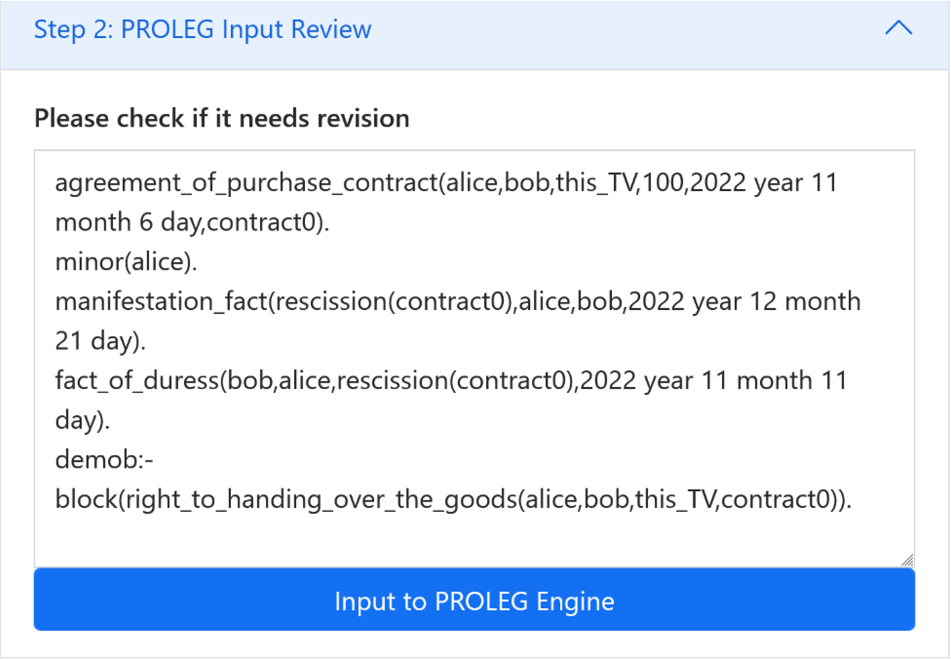
自然言語(ただし英語)で文章をPROLEGに入力すると(図3)、生成AIが法律的な意味のある事実だけを取り出し、各要素に分類表示(図4)します。また、生成AIでの出力は、図4のように論理式で出てきますが、間違いがあれば(例えば売主と買主が入れ替わったり)すぐに分かります。詳細に見なくても直感的に間違いがわかるので、そういうところに言語モデルを活用できるのではないかと思っています。そして、ブロックダイヤグラム(図5)も自動的に出てくるようになっていますが、まだ単純な売買契約の例しかできていないので、さらにいろいろな契約類型で、学習させていこうとしている状況です。そうした点が、2022年発行の Today No.97で紹介したPROLEGから、大きく変わったところです。この日本語インターフェイスは、私たちのところで作っていて、使用した言語モデルとしてはBERT、ChatGPTです。LLMCで公開したLLMについては、まだ使用していません。
――LLMに対する法規制について
西貝 AIに関する規制のあり方というと、生成AI、LLMだけでなく、様々なAIが含まれますが、それらに対する規制をまず一つの軸で捉えるのは、難しいと思っています。法制度も、民事法、刑事法、行政法など種類の違うものが複数あり、それぞれ議論の方法も違います。
まず、自動運転車にAIが搭載されている場合のそうしたAIに対する規制としばしば言及されるLLMを用いた事例に対する規制を比較して考えてみます。自動運転車の社会実装に際して起き得る法的な問題は、例えば、AIが搭載されている自動運転車が事故を起こした場合に「誰が責任を持つのか」とか「事故を防ぐためにどんな規制が必要か」ということになるか、と思います。人命に関わる事故の可能性があることを多くの人が認識できるから、規制の必要性自体は理解されやすいでしょう。そして、一般の方々の間でその問題意識が共有されて、事前に策定される丁寧なガイドライン、きめ細やかな過失の理論など、念入りに議論されていくのだ、と思います。
一方、LLMで問題とされ得るのは、表現に対する規制や著作権法です。他人の著作権を侵害すると重い刑罰が科せられ得ますが、かといって、自動運転と異なり、それが、即、人命に関わるということではないし、別の見方をすれば、日常的行為の延長線上に侵害行為があるということも可能かもしれません。こうした、いわば、万人が利害関係者になるような領域において、規制の透明性を確保するために、どのように厳密な議論を行っていくべきか、ということが課題になると思います。
そういう意味で、両者の規制のあり方は少し距離があり、別の次元で考えなくてはいけないと思います。
次に、規制がLLMの進化を阻害するのではないか、という危惧や懸念の観点から考えてみます。既存の規制は生成AIを前提としていなかったものが多く、生成AIがポンと出てきて、こんなことも、あんなこともできます、と、試しに色々やっていたら、本人も気づかない間に実はある種の規制に触れていて、触れている以上、その規制を適用しましょう、となってしまうと、今度は、法的にリスクが大きいから、そんなものは作らない、ないし使わない方がいい、という議論になりかねません。ですので、既存の規制をどのように生成AIに対して使っていくべきか、という議論があり得ます
その点で非常に悩ましいのが、既存の罰則というのは、新しい技術が出てきた場合にもそのまま包摂できるような条文になっていることがある点です。例えば、わいせつの概念が昔と変わっていたとしても、わいせつ物を禁止する規制自体は残っているので、生成AIを使ったら、わいせつな画像ができてしまったけれど、生成AIが出力したのだから大丈夫だろう、と思って、みんなに配っていたら、わいせつなデータの送信頒布罪(わいせつ電磁的記録送信頒布罪(刑法175条1項後段)に該当してしまっていた、ということはあり得る話でしょう。しかも、違法な画像を作成し、これを頒布した生成AIの利用者が捕まるにとどまらず、わいせつなデータを作るためだけのソフトウェアではないとしても、そういうことが可能なプログラム(生成AI)を作った人まで、犯罪の遂行を容易にさせるものを作ったとして、先のわいせつ電磁的記録送信頒布罪の幇助犯として処罰されるのか、という問題まで出てくるかもしれません。これはWinny事件(最決平成23年12月19日刑集65巻9号1380頁)を想起させる事態です。そこまで規制するのはやり過ぎだ、となっても、こうした問題、つまり、いろんな既存の規制が網の目のように広がっている現状をみますと、潜在的には規制され得る場合が結構あるのではないか、という懸念が残ります。それらの全てに引っかからないようにするのは重要ですが、場合によっては法的な検証コストからして結構大変なことになるかもしれません。そういう既存の規制が、LLMの進化を阻害してしてしまわないような法律学的なアプローチを模索する必要がある、と思います。
佐藤 「AIを制御する」と言っても、ガチガチに締めてやめさせるということじゃなくて、産業育成もありますから。極端なこと言えば、生成AI全部禁止!とすれば生成AIからの問題は出てこないわけです。が、それでは、新しい技術も社会も産業も発展していかないので、規制のバランスは非常に重要だと思います。
――表現と規制について
佐藤 LLMで議論される問題の一つが著作権です。著作権法では、芸術作品等の「表現」を保護しており、類似表現を基の表現に依拠して作ってはだめだとしています。逆に言うと、「表現」を保護していますが、「作風」のようなものは保護はしていません。作家の重要な特徴とは、書いた表現そのものというより、「作風」だと私は考えています。LLMは、その「作風」を学習できてしまうので、そういう作家の人格的なものが、LLMで、言葉は悪いですが、いわば「盗まれてしまう」というところが問題ではないかと考えています。もちろん、「作風」のようなあいまいなものをどうやって認定するかなど現実的には不可能とは言えますが。
また、LLMにおける表現という点については、ヘイトスピーチの問題もあります。LLMではヘイトスピーチを出力しないようにするという研究がありますが、表現の自由という観点から言うと、過度な気もしています。ただ、これは非常に難しい問題なので、現時点で明確には答えられません。
西貝 ヘイトスピーチよりもう少し手前の段階の、誰かを批判するような言論については、それが、その人の社会的評価を低下させるようなものである場合には、名誉を毀損する表現だとされ得ます。
議論の軸を分けて考えてみます。まずは、表現内容をAIがチェックできるのか、ということです。これがもし可能なら、名誉を毀損しないような表現を生成できることにはなるでしょう。しかし、これが難しい。名誉毀損的な、つまり他人の社会的評価を低下させるような事実の摘示であっても(刑法230条1項参照)、表現内容たる事実が公共の利害に関する事実に関係し、表現行為が主に公益目的に基づいており、さらに当該事実の重要な部分が真実であると証明された場合や(真実性の法理、刑法230条の2第1項参照)、当該事実の重要な部分を真実と信じるについて相当の理由がある場合には(相当性の法理)、名誉侵害に関連する民事刑事の責任を負いません。そして、一定の事実に基づいた意見論評についても、それが他人の社会的評価を低下させるものであっても、意見論評の基礎となった事実について、前記の真実性や相当性の法理に相当する状況があれば、人身攻撃に及ぶなど意見ないし論評としての域を逸脱したものでない限り、名誉侵害の責任を負わない(公正な論評の法理)、と考えられています。こうした法理は表現の自由の保障を実効的にするために導入されたものと理解されています。要するに、その表現だけとってみたら、かなり強い表現にみえ、それが、言及された人の社会的評価を低下させるようなものであったとしても、表現の自由の行使として許される場合があるわけです。そうすると、特定の人の社会的評価を低下させるような表現を出力しないようにするとしてしまうと、表現の自由の行使として許される表現行為の範囲より狭く、自己抑制的な出力しかされないことになります。それはやり過ぎだとして、上記の真実性、相当性及び公正な論評の法理が充たされる場合も出力できるようにしよう、というのはよいのですが、その判断までAIにさせるのは難しいでしょう。しかも、表現の自由として許される場合は、上記の法理が適用される場合だけではない可能性もあるわけで、そうすると、上記の法理の場合は大丈夫ということにしよう、としてAIを設計するだけでも、表現の自由で保護される表現よりも自己規制的なAIができあがる可能性があり、その点も大きな問題になり得ます。それゆえに、「こういう出力をさせるAIは作るべきではない」などという議論は慎重に行う必要がある、と思います。
次に、仮に、一定程度自己規制的なAIができあがり、それが広く使われるようになった場合のその後の推移の観点です。1つのストーリーとして、無数の言語表現を作ってくれるような生成AIが登場したことを契機として、法的観点から一定の表現を出力しないようにした方がよい、とした場合に、規制に積極的な議論が促進されて、この表現もまずい、あの表現もまずい、などとして、そこを起点として段階的に出力してはいけない表現が拡がる傾向が出てくるということもあるかもしれません。もっとも、そうはならないかもしれません。いくつかのストーリーを想定しつつ、よりよい将来の世界についての学際的な考察をすべきように思います。「LLM時代における表現の自由」という考え方が求められているということかもしれません。
――人工知能法学におけるLLMの活用と今後について
佐藤 LLMを使ってLaw by AIをどうするかという話は、日本の場合、司法がまだDX化されていないため学習データがないというのが一番の問題です。2024年7月時点で、法務省の検討会で民事裁判判決データベース化への報告書がまとまり2026年度からの運用を目指すという報道がありましたが、そういった初歩的な段階なので、もう少し先になりそうです。
取材:倉澤 治雄/構成:岸本 治恵/写真:杉崎 恭一