Sep. 2024No.103

Interview
LLM構築における透明性・信頼性・ 安全性
世界で急速に発展する大規模言語モデル(LLM)に向けられた人々の期待とともにある安全性への懸念。大規模言語モデル研究開発センター(LLMC)での大規模言語モデル(LLM)構築において「透明性」「信頼性」そして「安全性」はどのように果たされるのか。LLMCでそれらのワーキンググループ(WG)をリードする、関根聡 科学主幹と宮尾祐介科学主幹に聞いた。

関根 聡SEKINE, Satoshi
理化学研究所 革新知能統合研究センター 言語情報アクセス技術 チームリーダー
国立情報学研究所 特任教授
同 大規模言語モデル研究開発センター 科学主幹

宮尾 祐介MIYAO, Yusuke
東京大学 大学院 情報理工学系研究科 教授
国立情報学研究所 客員教授
同 大規模言語モデル研究開発センター 科学主幹
(敬称略)
──LLMCでのご担当と活動内容を教えてください
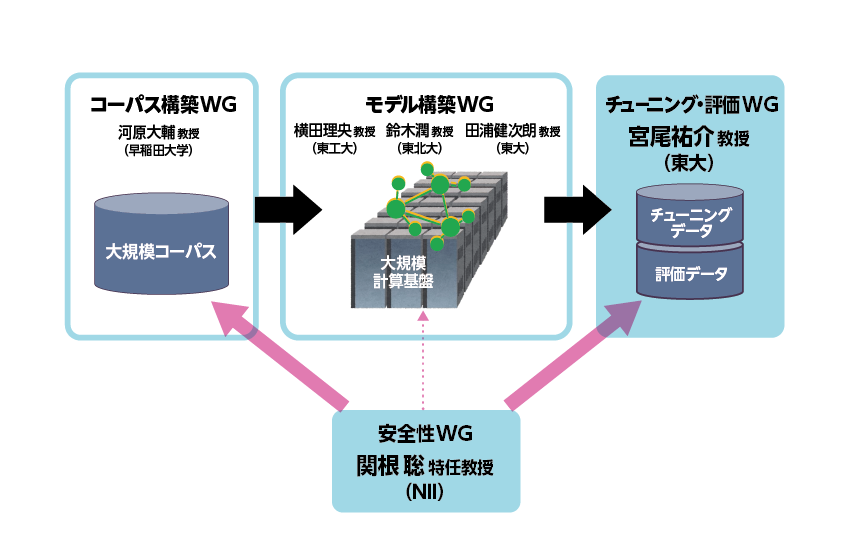
宮尾 まず、NIIのLLMがどのように構築されるのかを簡単に説明します。はじめにLLMが学習するデータが必要で、そのデータを準備するのが「コーパス構築WG」です。そのデータでLLMに事前学習をさせるのが「モデル構築WG」、その後「チューニング・評価 WG」、「安全性WG」が、さらに追加学習をさせます。
私が担当しているのは、「チューニング・評価」で、事前に学習された LLMを追加学習によって調整することをチューニングといいます。
ユーザがLLM(またはチャットシステム)に何かを入力する時、それはシステムから、なんらかの答えを期待しているわけです。例えば「今日の天気は何?」という言葉には、天気の情報が欲しいという意図が含まれていますが、この言葉を「質問」と理解して次に続くべき文章を出力するのと、単に単語列として見て次に続くべき単語列を出力するのでは、回答が異なります。そこで、システムへの問いかけだということを理解し、期待に応える自然な文章を生成するために行う技術が「チューニング」です。
そして、チューニングされたシステムからの出力が、正確性も含め、人間の期待や意図に沿ったものであるかを客観的に判断するプロセスが「評価」です。
では、どのようにチューニングし、評価をするか、です。生成 AIの前に、よく使われていた自然言語処理の方法が、機械学習を使ったものです。教師付き機械学習と呼ばれる、入力と出力のペアを学習データとして作り、それを機械学習のアルゴリズムに入力すると、機械学習のモデルが、こういう入力にはこういう出力、というのを学習します。LLMのチューニングでも基本的にはそれと同じことをしますが、使われるデータは、インストラクションデータといいます。インストラクションデータはアノテータと呼ばれる方々が、こういう入力(Instruction:命令)を与えたときに、こういう出力(Output:結果)を提供すべきだ、というペアを手作業で作っています。実は今我々が使ってるインストラクションデータの一部は関根先生たちが作られたものです。
「モデル構築WG」により事前学習されたLLMモデルに対して、ある程度の数のインストラクションデータでチューニングをしてあげると、「こういう入力には、こういう出力をすべき」もしくは、「こういう入力にはこういう内容を表示して、回答しないようにする」というようなことをだんだん学習していきます。
評価は、「入力と出力」が、どのぐらい出来ているかを計測するのですが、大きく分けて2つの方法があります。1つは、評価のためにあらかじめ入力と出力のデータのペアを作り、例えば「今日の天気はなんですか」と言われたらこう答えますとか、基本はインストラクションデータと同じですが、それを学習されたLLMに入力を与えて、出力された内容と、あらかじめ人間が作ったデータを比べ、どのくらい合っているかを測定するというものです。もう1つは、あらかじめ答えを作っておくのではなく、LLMにいろいろなプロンプト、質問を入力した結果の出力に対して、これは何点、良い、悪い、というのを人間が判断して評価します。特に安全性に関することは、あらかじめ準備することが結構難しいので、LLMの出力の安全性を自動評価するという研究も進めています。
関根 私はLLMCで「安全性WG」を担当しています。率直に言って、安全性を定義することはすごく難しくて、公的な安全基準があり、それはもちろん、守らなければいけないものですが、究極的には世の中の人たちが「これは心配ない、使っていいぞ」と思ってくれることが、多分言葉にできる形でのLLMに対する安全の定義だとは思っています。しかし人々に「大丈夫だ」と思ってもらうことは、さらに難しい問題で、そこを模索し実現していくことが、今の私たち「安全性WG」の研究テーマです。
具体的には、AIが作る最初から最後まで、安全性について検討します。まずは大量のコーパスを元にベースモデルが学習されるわけですが、その中で消しておいた方がいい内容を検討します。例えば殺人の方法が載っていて、それを全部消したら、もしかしたら殺人の方法を伝えることはなくなり安全かもしれない、という考えもあります。また、何か危険な毒物があり、それを全部消したら、その毒物については出力されなくなり、危険なことが伝わらないので、それは多分よくない、ということが考えられます。そうした検討に加えて、有害なテキストにラベルをつける、コーパスフィルタリングなどにも関わる研究活動が1つ目です。
2つ目は、今作っているLLMが毒性のある発言をしないようにすることで、宮尾さんのチームと協力して取り組んでいるSFT (Supervised Fine-Tuning)=教師ありファインチューニングです。これは、質問と答えのペアによるLLMのチューニングですが、例えば、○○という有害な質問には「それは危険なことですので答えられません」とか「法律違反で答えられません」といった回答をするように、インストラクションデータを作成しています。包括的有害カテゴリを、5つのリスクタイプ、12 の主要カテゴリ、61のサブカテゴリに分類した、英語のオープンソース「Do-Not-Answer」の分類をベースに、日本語による独自の高品質の質問と回答のデータセットが「Answer Carefully Dataset」で、2024年8月時点で2,000件を公開済み、さらにデータを作成しています。
インストラクションデータによる SFTは学習効果として非常に有効で、継続してデータを作成、学習、評価し、安全性のレベルをさらに上げることを目標にしてます。
──LLMCでの「透明性・信頼性に関する研究開発」について
宮尾 LLMCで、「透明性・信頼性に関する研究開発」がテーマに掲げられていますが、私自身が透明性・信頼性そのものを専門に研究している、というわけではないことを前置きして、まず信頼性というのは、人間がそのAIをツールとして使うときに信頼できる、ということです。それには、人間の意図や期待に沿った答えを出せるか、正確な回答であるか、あるいは出力した回答の理由根拠をAIが自身で説明できるか、ということが、LLMの信頼性の要素なのだと思います。また、LLMが差別やアダルト的なものなど、倫理からはずれた出力をしないようチューニングされているという安全性も信頼につながります。
透明性の方は、巨大なブラックボックスであるLLMが、どういう仕組みで回答を出力するのか、その仕組みを明らかにすることが最終ゴールです。ただ、それはある意味人間の脳を解明するのに近い難しさがあると思います。それ以外にも例えば、 LLMではどういう学習データを使っているか、どういうチューニングがされているか、自分が入力したデータがどうやって使われるのか、そういうことも含めて、そのAIのシステム全体としてちゃんとユーザーから見える、というのが透明性ということになると思います。また、何かトラブルが起きたとき、それにきちんとと対処するというのも、ある種の透明性といえます。
関根 信頼というのは、安全であればいいというわけではなくて、極端なことを言えば、安全性を実現するには全ての質問に答えなければ、危険なことは言わないので安全です。でも、それでは信頼されるわけはないので、そこには正確性だとか、ちゃんと質問に沿った関連性のある答えであるかとか、様々な要素が入ってきて、それらを総合して、安全性の上の概念として、信頼性というのはあると思います。私たちはそこまで、安全性を持っていかないといけないと考えています。
2022年3月にオープンAIが公開した技術論文に、彼らがチューニングした言語モデル(InstructGPT)に関することが書かれているのですが、半分くらいは安全性に関連し、「人間のフィードバックによるファインチューニングは言語モデルの真実性を向上させ、有害な出力生成を減らし、人間の意図に合わせるための有効な手段だ」とありました[1]。これを日本語でやるべきだと思い、所属先の理化学研究所でインストラクションデータを作り始めたのが去年(2023年)の夏ぐらいです。「安全性」だけに限ったわけではありませんが、1万件以上のインストラクションデータを作成しました。そこで、分かったことはデータの「質」がとても重要だという点です。自動生成で作られたものや英語を翻訳したインストラクションデータでは効果はあまり上がりませんでしたが、日本語の国語の先生やライターさんに質問と回答を作ってもらい、言語モデルに学習させたところ、一気に出力結果の品質が上がりました。質の高いインストラクションデータがきれいな文章を生成するということも分かってきており、品質の向上や「信頼性」につなげられればと思っています。
──LLMの課題と今後
関根 前述の「AnswerCarefully Dataset」を200件程学習したモデルで実験したのですが、それまで普通に答えられていた、安全な質問に対しても、「それにはお答えできません」と言い始めたことがありました。ですので、安全のためのデータも入れすぎると、副作用があるということがわかっています。宮尾さんのチームがそれを抑えるためのチューニングの工夫をして、有害ではない質問への影響をやや軽減できました。ただ、いまだにどうすれば答えるべきでないときに答えず、答えるべきときに答えさせるかというのは、研究課題です。
宮尾 我々が現在やっていることは、あくまで、「普通はこういうことは言っちゃ駄目ですよね」というのを一般的な用途を想定した上でのことですが、それではかなり不十分なところがあります。実際には、使う場面によって、例えば記事に使う場合には、こういうことは言ってはいけないとか、逆にこういうことは言ってもいい、というのもあるかもしれません。研究者が、ある専門の分野の研究に使うのなら、一般的に言ってはいけないと言われる言葉も、言う必要があるかもしれないわけです。そういうふうに、実は応用が決まった時点で、新たに「安全」、「有用性」、「信頼性」の基準が変わる可能性があるので、多分将来的には、LLMを開発してる人たちだけではなく、それをさらに使ってシステムに組み込む人たちが、その時点でのいろいろな安全性とか、信頼性とか、透明性の評価をしなければいけないということになると思っています。
[1]"Training language models to follow instructions with human feedback" https://cdn.openai.com/papers/Training_language_models_ to_follow_instructions_with_human_feedback.pdf
ハルシネーション
ハルシネーションとは、生成AIが事実と異なる出力をすることを指します。まず、LLMを学習するということは、チャットシステムに入力したことから新しい単語列を生成させたいというのが本質的なところとしてあります。それとハルシネーションは、実は表裏一体で、例えば、なにか小説を書きたいというときには、新しい単語列を生成しなくてはいけないわけですが、そのときの、創造性とか、新しい文章を生成する部分と、ハルシネーションは、本質が同じなわけです。ではどこからハルシネーションなのかといえば、それは我々が知っている事実とか情報と違うことが出力された時に初めてそう呼ばれるのです。ただ、LLM側からすれば、その学習データにはないテキストを生成しているという意味では同じです。社会の何か真理とか真実という、社会側にある情報と照らし合わせて初めて、これはハルシネーションかどうかということが判断されるわけで、LLM単体で見たときには、創造性とハルシネーションというのは同じなのです。つまりハルシネーションを止めることは、創造性を止めるのと同じことといえます。ですので、LLMのコアの部分でハルシネーションを防ぐことは難しいのですが、低減させることについては、いろいろ技術が研究されています。たとえば、LLMにあらかじめ関連する文書を検索しその文書に基づいて答えを生成するRAG (RetrievableAugmented Generation)や、生成された文章を別の方法で検証して、誤りがあればブロックして生成し直す技術もあり、LLMの外側で人間社会の真実に合致させる試みがなされています。(宮尾)
取材:倉澤治雄/構成:岸本治恵/写真:杉崎恭一