Sep. 2024No.103

Interview
日本メイドのLLMを構築する
文部科学省の「生成AIモデルの透明性・信頼性の確保に向けた研究開発拠点形成」事業を実施する拠点として、2024年4月、国立情報学研究所(NII)内に「大規模言語モデル研究開発センター」(LLMC)が設置された。大規模言語モデル(LLM)の透明性、信頼性の確保に向けた先端的な研究開発を行うことをミッションとする、センターの体制、今後について、同センター長の黒橋禎夫NII所長に聞く。

黒橋 禎夫KUROHASHI, Sadao
国立情報学研究所 所長 同 大規模言語モデル研究開発センター長

聞き手吉川 和輝YOSHIKAWA, Kazuki
日本経済新聞社 編集委員
1982年日本経済新聞社入社。産業部、ソウル支局、科学技術部長、日経サイエンス社長などを経て2015年から編集委員として科学技術分野を取材。1997~98年米マサチューセッツ工科大学・科学ジャーナリズムフェロー。
(敬称略)
LLMCの新設
──新設した大規模言語モデル研究開発センター(LLMC)にどのような思いを込めていますか。
言語や画像などを生成する生成人工知能(AI)が社会にもたらすインパクトは極めて大きいものがあります。私は大規模言語モデル(LLM)こそが今の生成AIの本質であると考えています。LLMによって人間とAIの言葉によるコミュニケーションが可能になったためです。LLMをベースにしたOpenAIのChatGPTは、人の言葉を理解してその意図を推測する能力が相当程度あります。人間にとって参考になることを言葉で示してくれるなど、生成AIとの対話を通じてコミュニケーションを深めていくことができるようになりました。
人間と同じように話をしたり、立ち振る舞いができたりするAIエージェントやロボットはSFの世界のもので、それが実際に登場するのはかなり先になると思われていたのが、LLMを軸にした生成AIによってこうした世界が実現しつつあります。
この分野の技術進展のスピードにも目覚ましいものがあります。変化が急速過ぎると感じるほどです。生成AIの世界で何が起きているのか、どんな将来見通しが立てられそうなのか、またどんなリスクを想定しなければならないのか。これらについて正確な認識を持つことが不可欠です。LLMCはLLMの研究開発を通じてこうした社会の要請に答えていきます。
── ChatGPT が登場したのが2022年11月末でした。その数カ月後にNIIが研究者を集めて組織した「LLM勉強会」がLLMCの前身になったと聞いています。
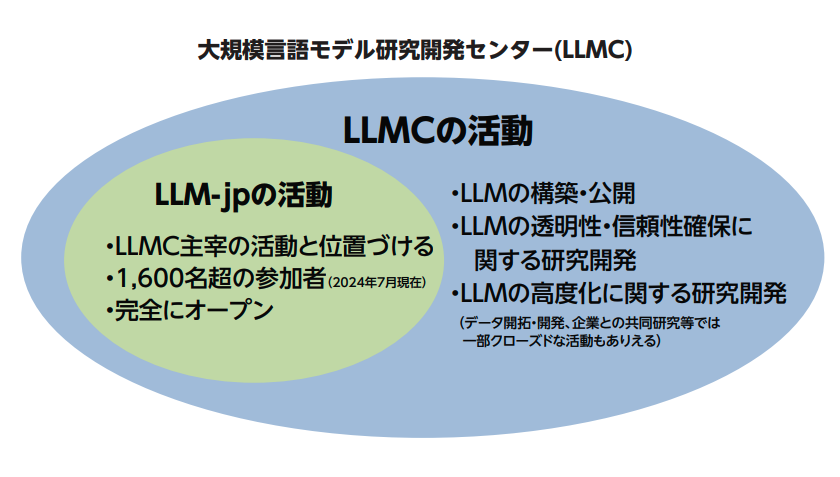
ChatGPTの登場を受けて、まずはLLMの勉強をしないことには始まらないという話になりました。自然言語処理やコンピュータ科学の研究者に声をかけて、2023年5月にLLM勉強会を立ち上げました。当初30人くらいの規模で始まり、1年あまりたった今では参加者は1,600人を超える規模になりました(2024年7月現在)。「LLM-jp(エルエルエム-ジェイピー)」という名前で活動を続けています。
LLM-jpでは2023年10月に最初のLLMである「LLM-jp13B」を、2024年4月には改良版の「LLM-jp13B v2」を公開しました。モデルの規模を表すパラメータ数は130億で、ChatGPT無料版で当初から使われていたLLMである「GPT-3.5」(推定1,750億パラメータ)の10分の1くらいです。
今年(2024年)4月にLLMCが発足し、LLM-jpの活動と連携しながら、パラメータ数1,720億、つまりGPT-3.5にほぼ匹敵する規模の「LLM-jp172B」の開発を始めました。学習に一部不具合がありましたが、その後は順調に進んでおり、2024年中に完成・公開の予定です。
その後は予算が認められれば、さらにその10倍、1兆を超えるパラメータのLLMの開発に取り組みたいと考えています。トップクラスのLLM である OpenAI の「GPT-4」のパラメータ数は1兆を超えると推定されており、これに匹敵する規模のLLM 開発への挑戦になります。2025年度の完成を目指したいと思います。政府主導のプロジェクトでこれだけの規模のLLMを開発する試みは世界でもそう多くないはずです。
AIの健全な進化に向けて
──LLMCはどのような方針・体制で進めていますか。
研究成果をすべて公開するというのが基本ポリシーです。LLMを開発するためにどんな学習データを使ったか、モデル構築に技術的にどのような工夫をしたか、その結果生まれたモデルの性能の詳細など、研究開発の過程や結果について失敗例を含めてすべて公開します。研究成果へのアクセスを保証し、あらゆるユーザが研究成果を広く利用できるオープンサイエンスの場を作ります。これを通じてAIの健全な進化に貢献できると考えています。

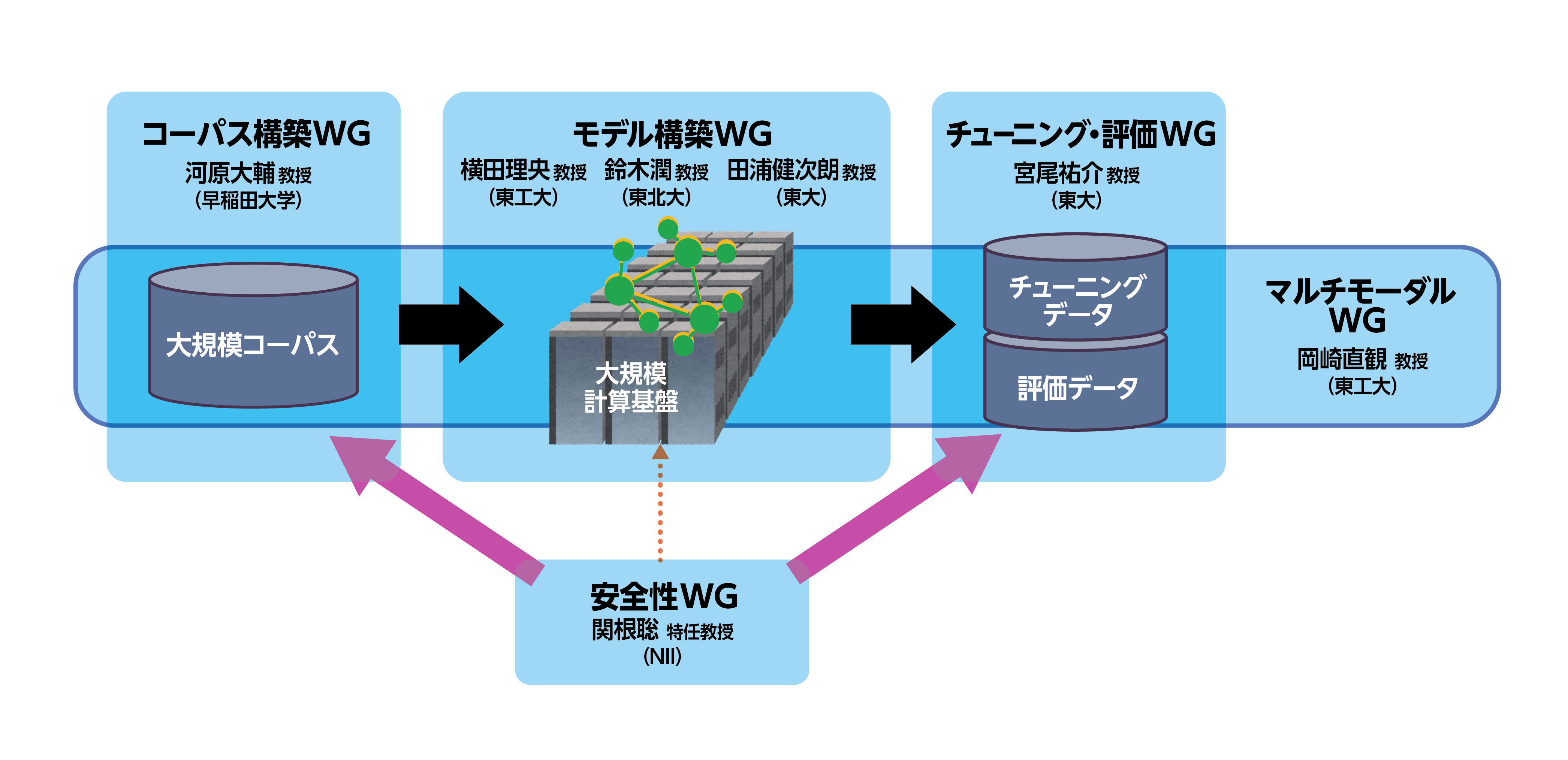
LLMCの研究課題は3つあります。1つ目が「研究開発用 LLM 構築」。LLMの学習用の新規コーパス(自然言語のテキストを大量に集め構造化した学習用データベース)の開発や、GPU(画像処理装置)を使った並列計算機の環境整備、モデ ル構築の各個別課題を設定しています。2つ目が「透明性・信頼性に関する研究開発」。チューニングと呼ばれるモデルの調整作業の効果分析、2023年5月のG7広島サミットで始まった「広島AIプロセス」に基づいた安全性対策、法制度・倫理基準を踏まえたLLMの評価手法の開発など、7つの個別課題があります。3つ目は「高度化に関する研究開発」で、モデルの軽量化や新たなアーキテクチャについて研究します。
日本のLLM研究の総力を結集
研究に携わるスタッフは8人の科学主幹をはじめ全体で約30人。複数の研究課題にまたがって取り組む研究者もいます。外部連携機関として東北大学、東京大学、東京工業大学、早稲田大学、京都大学の各大学のほか、理化学研究所や産業技術総合研究所などの研究機関が参加しています。契約はこれからですが民間企業の参加も仰ぎます。日本のLLM研究の総力を結集した体制を作ることができました。
──LLMの構築にはコンピュータなど計算資源の確保がカギを握るといわれています。順調に手当てができていますか。
LLM-jpで最初に開発した「LLMjp13B」は東京大学に置かれている「データ活用社会創成プラットフォーム(mdx)」という計算資源を使いました。開発中の「LLM-jp172B」は経済産業省のAI支援プロジェクト「GENIAC」の計算資源を使っています。また2024年5月~9月の5カ月間は東京工業大学のスーパーコンピュータ「TSUBAME4.0」も利用します。8月からはさくらインターネットのGPUサーバを使うことになっています。
LLMCは2024年度から5年間のプロジェクトで、計算資源の経費を別にした年間予算は7億円です。計算資源向けには昨年度補正予算で40億円を手当てしていただきました。初年度から計算資源のための十分な予算をつけてもらっており責任を感じています。今後も、研究の実績を積み重ねて、計算資源の予算を確保しながらプロジェクトを進めていきます。
──研究開発ではどのような分野に注力しますか。このセンターでしかできない研究をやりたいといった構想はありますか。
いくつかのアイデアがあります。まずLLMの透明性や信頼性に関係することです。LLMの学習はコーパスを使って何万ステップにわたって行います。ある時点でこのデータ、次の時点ではこのデータ・・・という形で順番に学習していきます。
その過程でニューラルネットワークのモデルが少しずつ修正されて変化して最後にモデルが完成するわけですが、そのプロセスをスナップショットを撮るようにして追跡していきます。これによってニューラルネットワークの中で、例えば意味の表現がどのように変化しているかを調べることができます。
もう一つは、LLMがある回答をしたときに、それが学習したテキストのどの部分に基づいて回答してきたのかを検索によって特定するという方法です。ニューラルネットの情報処理の過程を観察するのは不可能に近いわけですが、このような方法によってLLMの回答の根拠部分を知ることができます。LLMが間違った回答を出すハルシネーション(幻覚)という現象の原因を特定することにもつながります。
こうしたアプローチは学習データの著作権問題にも関係します。例えば新聞社などメディアの記事データが勝手にAIの学習用データに使われてしまうという問題が現実に起きています。LLMの出力結果が参照している部分を明示できれば、出力結果に関心を持ったユーザーが元の記事データなどの著作物にアクセスしてより詳しい情報を得るといったことができるようになります。生成AIの事業者と著作権者の双方にメリットをもたらす関係を築くことができるでしょう。

安全性向上への研究開発
──生成AIの安全性への関心が高まっていますが、LLMCが貢献できる部分はありますか。
生成AIの安全性は非常に重要なテーマで、LLMCで取り組むLLMの透明性・信頼性研究の柱です。日本でも2024年2月にAIの安全性に関する評価手法や基準を検討する「AIセーフティ・インスティテュート(AISI)」が発足しました。AISIの活動は広範囲にわたると思いますが、技術面はLLMCの研究成果を通じてしっかりと協力していきます。
一例ですが、LLMが「爆弾の作り方を教えてください」といった有害な質問には答えないように訓練するデータセットを開発して公開し、その内容をアップデートしていくといった取り組みが考えられます。ただそうしたLLMを作っても今度はそれを何とか突破してやろうと巧妙なプロンプト(生成AIの回答を得るための命令文)が考案されるといった一種のイタチごっこになってしまう面があります。
このため、より一般的な方法でLLMの不適切な振舞いを抑制することも検討します。例えばモデル自体に有害性を抑える能力を持たせるといったアプローチです。モデルによる理解力を高めることで、モデルが自分自身の学習したコーパスを調べて、それが有害な内容を含んでいると分かったら、次からはそのデータを学習から外すといった試みです。これらを含め様々な研究を試していこうと考えており、こうしたことでLLMをうまくコントロールできる可能性が開けてくると思います。
LLMCが協創の場になる
──LLMをはじめ生成AIをめぐる世界の開発競争は熾烈なものがあります。研究開発にはスピード感も重要ですね。
今後のLLMの研究がどのような方向に進むのか、予測が難しい面があります。学習データの量を従来以上に増やしていくのか、データの質を高めていくのか、あるいは学習の方法やアルゴリズムを工夫していくのか――色々な可能性をにらみながらLLMの研究開発の方向性を機敏に判断しなければなりません。
現在、最先端の生成AIモデルの開発の中心になっているのは米国や中国の企業で、その多くがクローズドな研究環境で開発を進めています。人々の目が容易に届かない中で秘密裏に研究が進み、ある日突然、人間がコントロールできないAIが登場するといったことになるのは望ましいとは言えません。
こうした動静を含め、生成AIの世界では1~2年後に何が起きているのかを想像するのも難しい状況になりつつあります。そうだからこそ、LLMの研究をあちこちでバラバラに行うだけでなく、みんなが集まってLLMを開発しながら技術を深く 理解し、将来の見通しを立て、新しい技術を提案できる体制を作ることが重要です。LLMC がそのような場になれるよう育てていきたいと思います。

聞き手からのひとこと
生成AIが社会やビジネスの姿を大きく変えつつある。黒橋所長が強調するように、AIが「言葉」を理解し始めたことの意味は大きい。生成AIはやがてロボット技術と融合しヒューマノイドが多くの労働を代替するだろう。 またAIが人間に代わって科学研究を担い新たな文明を切り開く道筋も見えてきた。その過程ではAIと人間に軋轢も生じる。先端AIが投げかける功罪半ばする課題を解くには、何より生成AIを知り、その進化のシナリオについて見通しを立てる必要がある。AIを人類の望ましい形にコントロールする術を探るためにも、生成AI発展のドライバーである大規模言語モデル(LLM)を研究するLLMCへの社会の期待が高まる。(吉川 和輝)