Sep. 2024No.103

Article
研究開発用LLMが果たす役割
大規模言語モデル研究開発センター(LLMC)は、研究開発用大規模言語モデル(LLM)の構築に取り組んでいる。LLM勉強会(LLM-jp)が構築、公開した130億パラメータ※1のLLMの実績をもとに、2024年度中には、GPT-3レベルとなる1,720億パラメータのLLMを新たに公開する予定だ。この狙いはどこにあるのか。構築に取り組むLLMC鈴木潤 科学主幹、横田理央 科学主幹に聞いた。

鈴木 潤SUZUKI, Jun
東北大学 言語AI研究センター センター長・教授
国立情報学研究所 客員教授
同 大規模言語モデル研究開発センター 科学主幹

横田 理央YOKOTA, Rio
東京工業大学 学術国際情報センター 教授
国立情報学研究所 客員教授
同 大規模言語モデル研究開発 センター 科学主幹
(敬称略)
人間と生成AIが共存する世界。生成AIが、これからの私たちの生活や仕事、社会を大きく変えつつあることは、多くの人が抱く共通の予感といえるかもしれない。
しかし、生成AIの中核技術である大規模言語モデル(LLM)の構築において、学術界や、日本の産業界には懸念される事項があり、それを横田教授(以下「横田」)は、次のように指摘している。「これまでの言語モデルの構築においては、学術界でオープンな研究開発が行われ、透明性や安全性、公正性、再現性が確保されてきました。しかし、現状を見ると、大規模開発投資を行う一部の巨大IT企業が LLMを独占し、詳細な技術情報は公開されていません。これは不健全な状態といえます」
また、ビッグサイエンス領域における寡占化の懸念だけでなく、学術界と産業界の研究開発におけるバランスの維持、国家間の経済安全保障の観点など、LLMの研究開発は、様々な課題に直面した状況にある。鈴木教授(以下「鈴木」)は「寡占化状況は、巨大IT企業に所属している一部の研究者だけにチャンスが与えられるということになりかねません。オープンサイエンスによって、様々な人の意見や考えを盛り込み、技術が発展していくことが重要と思いますが、それが阻害されていることは、大きな損失になります。これも解決すべき課題のひとつです」と、語っている。
LLMCが開発した研究開発用LLMは、こうした懸念や課題を背景に、学術界や産業界におけるLLMの研究開発に貢献することを目的に構築、公開され、オープンかつ日本語に強い大規模モデルを構築し、LLMの原理解明に取り組むことを目指している。
「LLMを社会で利活用していく上では、LLMの透明性や信頼性の確保が必要であり、モデルの高度化に伴い、安全性の配慮がより重要となります。今回のモデルや今後構築するモデルを活用することで、研究をさらに進めることができ、LLM研究開発の促進に貢献できると思っています」(鈴木)
NIIが主宰し、2023年5月にスタートしたLLM勉強会では、国内初の研究開発用 LLMとなる「LLM-jp13B v1.0」を、2023年10月に構築・公開するとともに、2024年4月には、その後継となる「LLM-jp-13B v2.0」を構築・公開した。
LLM-jp-13B v1.0は、130億パラメータのLLM で、モデルアーキテクチャにはGPT-2を採用している。9大学2研究機関が共同運営するデータ活用社会創成プラットフォーム「mdx」の12ノード(NVIDIA A100GPU を96 基搭載)を活用し、約3,000億トークン[2]の学習データによって構築されたLLMだ。学習データの内訳は、日本語では、日本語mC4(インターネット上から収集された言語のデータセット)および日本語Wikipediaによる約1,450億トークン、英語では、英語The Pile(オープンソース多言語モデル)および英語 Wikipediaによる約1,450億トークン、プログラムコードでは、TheStack(使用が許諾されたソースコードのデータセット)の約100億トークンを用いている。
「当時は、日本において、130億パラメータのLLMを開発した人は誰もいませんでした。学習するには何が必要なのか、先行研究の成果だけでうまくいくのかどうか、まさに手探りのなかで、最適と思われる技術を活用して、LLMの構築に挑戦したのです」(横田) 2023年5月にプロジェクトがスタートし、同年10月には公開するというスピードについても横田教授は強調する。
一方、LLM-jp-13B v2.0では、同v1.0の実績をもとに、LLaMA(Meta-旧Facebook-社が公開しているオープンソース言語モデル)をベースに構築を行い、データ品質を改善した「日本語 Common Crawl」を活用して、約2.600億トークンを学習している。日本語では、約1,300億トークン、英語は約1,200億トークン、プログラムコードが約100億トークンの構成だ。さらに、8種類の日本語インストラクションデータ[3]および英語インストラクションデータの和訳データを用いてチューニングした。計算資源には、mdxの16ノード(NVIDIAA100 GPUを 128基搭載)を活用している。
「LLMにおいて重要なのは学習データです。これを品質の高いものにするとともに、様々な検証実験を行い、トークナイザー[4]をはじめとした各種部品を進化させ、より高い性能を実現しました」(横田)
すべての情報を公開するLLM
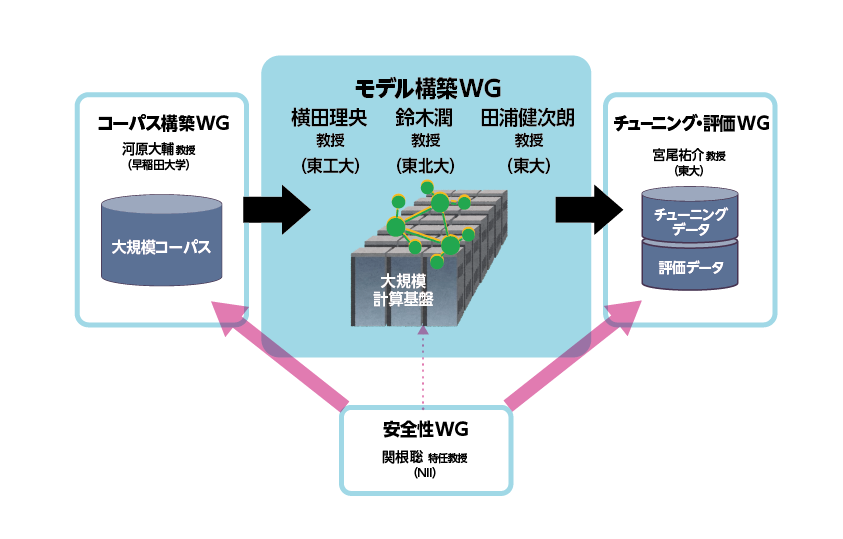
研究開発用LLMの構築にあたっては、LLMC内に、モデル構築ワーキンググループ(WG)のほか、コーパス構築 WG、チューニング・評価WG、安全性WG、マルチモーダルWGなどを設置し、それぞれにトップレベルの研究者が参加し、活動を行っている。
「LLMCには、国内の自然言語処理および高性能計算分野を牽引するトップレベルの研究者が集まっています。LLMを構築する上では、これ以上考えられない最高の人材によって構築した研究開発用LLMです」(横田)
コーパス整備では、学習に必要なテキストデータを収集および精製し、モデルが学習しやすい形式に変換した。モデル構築では、ニューラルネットのアーキテクチャとそれを実装するためのフレームワークを選定し、次の単語を予測するタスクにおいて、膨大なデータ学習を行うことで、ベースとなるモデルを構築した。また、指示チューニングではベースモデルの指示応答性を高めるため、良質な回答例を使って追加学習を行い、安全性チューニングでは、人が好ましいと思う応答が得られるようになるまで追加学習を行った。さらに、評価用ベンチマークの作成では、構築したモデルの性能を評価すための様々なベンチマークを作成し、これを利用できる環境も整備している。
「それぞれの構成要素には技術的な課題が山積しているが、巨大IT企業は、そのノウハウを外に出さないため、問題が起きた際に、利用者は対策のほどこしようがありません。研究開発用LLMの最大の利点は、これらの構成要素の中身を分析し、公開することでLLMの利用者に対して透明性、安全性、公平性、再現性を担保できる点にあります」(横田)
「データやチェックポイント、あるいは、どの順番で学習したかといった情報などを揃え、これらを公開しているLLMは、世界的に見てもほとんどありません。LLMCが開発した研究開発用 LLMは、今後、LLMの中身を解析したいという世界中の研究者が使用する標準モデルになる可能性があります」(鈴木)
たとえば、パラメータ数が大規模化すると、モデルの学習中に、学習の進行度合いの評価値となる「loss(損失)」の値が急激に跳ね上がる現象、いわゆるロススパイクが発生する頻度が高くなる。この現象によって学習が継続できず、最初からやり直した方が良いというケースが発生するなど、学習にかかるコストや時間に大きな影響を与える場合がある。
「現時点では、ロススパイクがなぜ発生するのかは完全に解明されておらず、そうした事象が起きないように、十分に注意を払って実験の設定を決める必要があります。小さなモデルでは発生しなかった事象が、大規模モデルの構築では課題となって発生することがあるのです。ですが、大規模モデルで学習するという経験が少ないため、正しい知見を見極めることが難しいのが実態です」(鈴木)
「研究開発用LLMでは、モデルそのものだけでなく、学習に用いたデータセットなども公開しているため、利用者から、その透明性や再現性に対して、高く評価されています」(横田)
また、LLMCでは、GPU並列計算環境の整備も進めており、この内容も公開している。
「LLMの事前学習では、効率的に学習するために何百ものGPUを同時に使用して、データ並列やテンソル並列、パイプライン並列などの並列化手法を併用する必要があります。深層学習で一般的によく使われるPyTorch(Pythonのオープンソースの機械学習ライブラリ)だけではこういった効率的な分散並列化のフレームワーク(機械学習を行うためのソフトウェア)を提供していないため、効率的な分散並列学習ができるMegatron-LM(NVIDIA の分散学習用のフレームワーク)などを利用する必要があります。Megatron-LMのような複雑なフレームワークが正常に動作するための環境を、それぞれのシステム上で構築することは容易ではありません。LLMCでは構築した際の手順を一般公開しているため、多くのLLM開発者が同じ苦労をしなくて済むのです」(横田)
公開している研究開発LLMは、安全性の観点に基づくチューニングを行ったものではあるが、研究開発の初期段階のものと位置づけ、そのまま実用的なサービスに利用することは想定していない。しかし、2024年7月時点で、同v1.0は2万7,866件、同v2.0は3,911件のダウンロードがあり、学術界や産業界での研究用途において、すでに広く利用されていることがわかる。
日本のLLM技術の底上げに貢献
LLMCでは、2024年度中にも、国内最大のLLM となる、1,720億パラメータのLLM-jp 172Bを構築、公 開する計画を明らかにしている。
経済産業省の「GENIAC」の支援のもとに構築を進めており、現在、2兆1,000億トークンのデータを学習しているところであり、「学習は順調に進んでいる」と横田教授は進捗状況を示した。
LLM勉強会では、2023年度に、GPTをベースにした1,750億パラメータのLLMに、試験的に事前学習をさせた経緯があるが、GPTの場合には、開発元であるOpenAIが、事前学習データの内容を公開しておらず、LLMを活用する際に分析などに制限が生まれる可能性があった。しかし、LLM-jp 172Bでは、独自に事前学習を行い、透明性や信頼性が高く、日本語に強い国内最大規模のLLMが誕生することになり、LLMの研究開発の促進に大いに貢献することができる。
「日本におけるLLM開発を牽引する技術が、ここから生まれると思います。国際競争力を持ったモデルが社会実装されることで、今後のイノベーションと経済成長を支える社会インフラの重要な一部となる可能性を秘めています」(横田)
今後は、Mixture of Experts(MoE)形式[5]のモデルを開発することで、性能を維持しながらも、学習や推論に関わるコストを抑える取り組みを行なっていく予定であるほか、さらにその先には、GPT-4に匹敵する1兆パラメータ規模のLLMの開発も視野に入れている。
「LLMCが目指しているのは、世界一のLLMを作り出すことではありません。日本におけるLLMに関わる多くの技術の底上げをする、いわば公共事業的な意味が強いのです。LLMCが構築したモデルやコーパス、評価データなどを、すべて公開するだけに留まらず、そこで得た経験やノウハウなども文書化して公表します。秘匿する情報がないため、聞かれればすべて教えることができます。つまり、研究開発用LLMで積み上げてきたことを、日本の学術界、産業界がすべて利用できる状態を作っているのです。成果をもとに、LLMの研究や事業を開始できるため、ここが、日本のLLM技術レベルの最低ラインと位置づけ、水準を押し上げることができます。これは、公的な研究機関であるNIIだからこそ実現できることです」(鈴木)
LLMCでの研究開発用 LLMは、日本のLLM技術全体の底上げに大きく貢献するものになることは間違いないだろう。(取材:2024年7月)
※1 パラメータ:実態は大量の実数値。通常行列やベクトルで表される。モデルの大きさを表す際にパラメータ数を用いる。
※2 トークン:「単語」の代替として用いられる。単語は基本的に文章中の意味をなす最小構成の文字列となるが、トークンはそういった文法的な意味合いはなく、特定の規則に基づいて区切られた文章中の文字列を表す。
[2]トークン:「単語」の代替として用いられる。単語は基本的に文章中の意味をなす最小構成の文字列となるが、トークンはそういった文法的な意味合いはなく、特定の規則に基づいて区切られた文章中の文字列を表す。
[3]インストラクションデータ:人間の指示とその指示に対する理想的な回答の組みになっているデータ。
[4]トークナイザー:文章を上記[2]で説明しているトークンに分割する役割を担うプログラム。
[5]MoE形式:Mixture of Experts の略記。パラメータの一部がExpertと呼ばれる単位に分割されており、 Expertの一部のみを用いて学習や処理をする方式。
取材・執筆:大河原克行/写真:杉崎恭一