Dec. 2022No.97

Interview
人工知能法学の全貌
人工知能が社会のあらゆる分野に進出しつつある。 人工知能は暮らしを便利にする一方で、これまでなかった新しい問題も生み出している。 デジタル技術は日進月歩で進んでおり、法律がそれに追いつくのは容易でない。 こうした時代に求められるのが、人工知能研究と法学を融合させた「人工知能法学」だ。 この学際分野の生みの親とも言える佐藤健教授に、成り立ちから現状、今後の展望を聞いた。

佐藤 健SATOH, Ken
国立情報学研究所
情報学プリンシプル研究系 教授

聞き手山田 哲朗 氏YAMADA, Tetsuro
読売新聞 論説委員
東京大学卒、読売新聞社入社。2006年、マサチューセッツ工科大学(MIT)ナイト科学ジャーナリズム・フェロー。経済部、科学部、ワシントン支局特派員などを経て、2018年、科学部長。2019年から論説委員(科学技術担当)。
――人工知能法学の研究は、 どのように始まったのですか。
車の自動運転やインターネット上の自動翻訳など、人工知能(AI)が色々な場面で使われるようになっています。AIの利用が広がるにつれ、それに関連した事故や、プライバシー侵害などの問題
が起きることが懸念されます。
社会がAIをコントロールするには、まずは法律を作ってAIを制御するのが妥当でしょう。しかし、法曹の人たちにとって、AIの技術的な部分を理解するのはなかなか難しい。そこで、法曹がAIをコントロールするのを、AI自体を使ってサポートできないかと考えました。困っている人たちを助けるツールを作ろうという発想です。それが最初の動機でした。
その後、ディープラーニング(深層学習)が広まり、さらには、今後ロボットが社会で問題を引き起こす場合などに備えて、何らかの法的な議論をしておくべきではないかという指摘が出てきました。工学だけでなく法学からも、人工知能の統御という問題意識が示されたわけで、それを融合した総合的な研究分野を作ろうと考えました。
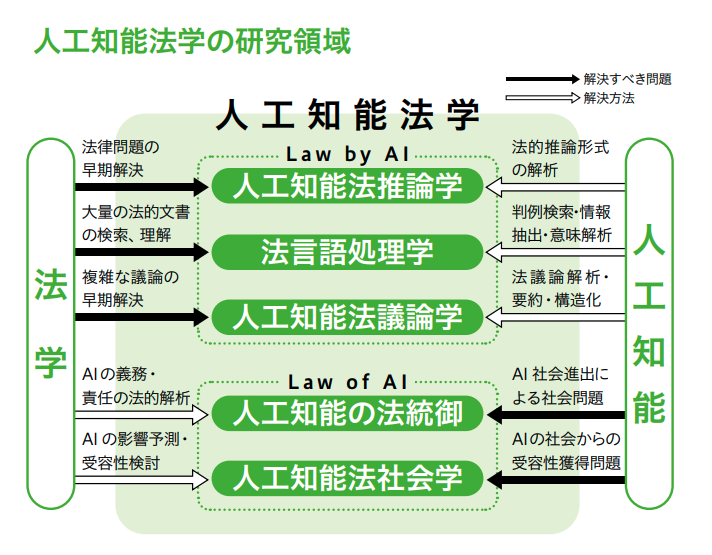
――大きな枠組みとしては、Law by AIとLaw of AIがありますね。
Law by AIは Law supported by AIのことで、AIによる法律の支援、サポートです。Law of AIは、Law control of AI つまり「AIの法」で、人工知能をどうやって法統御するかというテーマです。こうした学問体系をきちんと作り、高度情報技術と法律の双方を理解できる法曹を育成することが究極の目的です。
――両分野を理解するため、佐藤先生はご自身が大学院で法律を勉強されたとか。
2006年に東京大学(東大)法科大学院に入学しました。東大では人工知能法学の先駆けのような太田勝造先生との出会いもあり、大きな意義がありました。しかし、最近でこそ「自動運転車の事故に関する責任はどこにあるのか」などAIの法統御に関する研究が始まっていますが、当時は、こうした新分野に興味を持つ人はあまりいませんでした。
――自動運転で事故が起きた場合、自動車メーカー、自動運転プログラム、座席の人間、いずれの責任なのか難しそうです。
技術的な面から言うと、事故があったとき、その記録が残っていて、どこに問題があったのかをある程度、追跡できるような透明性が必要でしょう。全然記録がなければ誰の責任か分かりません。だから法的にはまず透明性のようなものを要求しないといけないのかなと考えます。個人情報が悪用されたときにも、個人情報の流れが透明でなければ誰が責任を持つのか分かりません。
AIが人権を侵害するのか
――AIの法社会学とは、法統御よりは裾野が広いイメージでしょうか。
法社会学は、法が社会にどういう影響を及ぼすかを研究する学問なので、AIが社会に入ってきたときにどのようなインパクトを持つか、逆にどういう形でAIが入っていけば社会に受容されるのかを研究する分野です。「AIが人間の雇用を奪う」というよく聞く議論もこの範疇に入ります。
――Law of AI は伝統的には文科系の分野ですが、工学者はどう関わるのですか。
エンジニア側は、解決すべき問題点を提起する役割です。それを受けて、法学者側が解決策を考える形です。両者が協力してAIの本質を押さえないと、すぐに新しい技術が出てきて、せっかく作った法律は役に立たなくなるという事態もありえます。
――プライバシーの侵害なども大きな問題です。
私が一番心配してるのは、AIが人権を侵害する可能性です。例えばイギリスの選挙コンサルタント会社「ケンブリッジ・アナリティカ」は、Facebookのユーザプロファイルなどを使ってユーザの嗜好を把握し、それに合わせて選挙運動のキャンペーンのメッセージを送っていたとされています。選挙対策の心理操作というか、人権侵害というべきか、大きな批判が巻き起こりました。
行政や企業が何らかの決定にAIプログラムを使うとします。ところが、深層学習では、学習データの中にバイアスが入ってしまうと、バイアス付きの決定が出てきます。例えば、人種と犯罪率の関係がデータに入っていて、犯罪率の高い人種は雇用されなくなるとすると、それでまた経済格差が広がり、さらに犯罪率が増えるという悪循環がおきます。これでは人種差別を助長することになりかねません。
――次に Law by AI についてお尋ねします。まず人工知能法推論学とはどのようなものですか。
基本的には論理学をもとにしたもので、私が作ったPROLEGは判決推論を行うプログラムです。今のところ、既に事実は確定している状態で、その事実と、対応する条文を使って結論をくだすという仕事ができます。今後は、証拠からどうやって事実認定するかという部分まで拡張して、裁判官の仕事をトータルにサポートできればと考えています。
――法言語処理学は、法的文書の検索や、人間が使う普通の「自然言語」を扱うものですか。
そういうことですね。2014年から私はCOLIEE(Competition for Legal Information Extraction and Entailment)という国際コンペをしています。日本の司法試験の短答式問題に答えるタスクや、ほぼすべてが公開されているカナダの判例データベースを基に、ある新しい事件に関して、それに関連する過去の事例を見つけてくるというタスクがあります。
ただ、私がこの分野で一番やりたいことは説明生成です。すなわち、自然言語で書かれた事件の記述をコンピュータの推論システムの入力形式に変換し、判決を推論するとともに、その判決に至る道筋を出力するものです。
常識がないと判断は下せない
――法律関係の文章は古風で分かりにくく、用語にも独特の難しさがあります。
法律の文章を処理するには、単純な機械翻訳という形はなかなかできません。例えば条文の意味を正確に理解するには、そこには書かれていない条件や知識が必要になります。単純に条文を見るだけでは駄目で、教科書や解説書まで広く見ていかないとちゃんと動くシステムはできません。
――機械が世界の意味を理解するためには、実はフレームの枠外にまで際限なく広がっている膨大な背景知識が必要だという「フレーム問題」を思い起こさせます。
道ばたである女性が車にひかれそうになり、その女性を助けるため突き飛ばしたところ、どぶに落っこちて晴れ着が汚れてしまったとします。この場合、助けた人は晴れ着を弁償しなければならないのか。突き飛ばすという行為は、法律上は「事務管理」という言葉になります。
通常の事務管理では相手方に損害を与えれば弁償責任が生じる可能性がありますが、「急迫の危害を免れさせるため」の「事務管理」(民法第698条)であれば、弁償しなくていいわけです。でも、急迫の危害とは一体何かとか、問題はすごく幅広い範囲に及び、どうしてもある程度の「常識」がないと判断が下せないことになります。
そもそも法律の条文というのは、法的推論を理解するヒントみたいなもので、実際の解釈は、法学者なり専門家なりの頭の中に存在し、その解釈は時代に応じて変わっていきます。
――人工知能法議論学はどのようなものですか。
裁判官3人による合議制、複数の市民が参加する裁判員制度、あるいは様々な利害関係者が協議して契約を作る場合など、複数人が関与するような議論をどうサポートしていくべきかを考えるのが人工知能法議論学です。
例えば、参加者の発言を音声認識し、誰がどのような意見を述べたかなどを図にして、「ここの部分は全員が同意していますね」とか、「ここは反対意見があるので、もう少し議論しましょう」などと、争点を探ったり、合意点を確認したりできます。
日本は法律関連の電子データが少ない
――様々なテーマを持つ人工知能法学の全体像がようやく見えてきました。これらを進めるうえで何か課題はありますか。
日本の場合、まだ法律に関する電子データが少ないのが大きな問題です。AIに機械学習をさせようにも、そのためのデータがないのです。カナダでは判決はほとんど電子化され公開されています。ところが日本は判決文など基本的に紙です。地方裁判所に行けば、紙に書かれた判決を読めるので、一応、公開はされていることになっているわけですが。
――なぜ電子化されないのでしょうか。
司法の世界では「原本主義」というものがあり、触れられる形のあるものでなければならない。それで紙になるわけです。また、一番の問題だと指摘されているのはプライバシーで、判決文には実名などが書かれており、それを匿名化しなければならないのではないかといった議論もあります。
私が最も懸念しているのは、中国などが自由に使える判例を基礎にして優れたディープラーニングを開発すれば、どんどん技術が進んでいくことです。日本は取り残され、非常にまずい状況になるのではないでしょうか。ヨーロッパでも、個人情報保護の仕組みがあるため、むやみやたらにデータを使うわけにはいきません。そうすると、プライバシーを尊重しない専制的な国家だけで、技術がどんどん進むことになります。
――企業法務ではすでにAIの活用が始まっています。ところが、ある企業が「AIで契約書を点検するサービスは合法か」と国に照会したところ、「弁護士法に違反する可能性がある」との回答があったそうです。
こうした見解は、AIを利用したビジネスの育成を阻害する効果を持つでしょう。昔「Winny」というファイル共有ソフトが問題になったことがあります。P2Pと呼ばれるコンピュータ同士の通信技術としては秀逸でしたが、開発者が逮捕され、この技術は日本では死滅した形になりました。結局、最高裁で無罪となりましたが、本来だったら自由にやるべきところを、国が待ったをかけてこの技術をつぶしてしまいました。日本のように、社会的な問題を起こさないよう、新しい技術をあらかじめ抑制するのか。それともアメリカのように、ある程度、リスクをとって新しいものを動かしてみて、何か問題が起きたら事後救済するのか。どちらをとるか、政府の覚悟が問われることになります。
――最後に、今後、日本の研究拠点を作る構想はあるのでしょうか。
人工知能法学という新たな学問体系をきちんと確立するため、外部機関からも研究者を招き、情報学や法学の研究者を結集した研究センターを国立情報学研究所内に設置しようと検討しているところです。来年度には設立できればと考えています。
聞き手からのひとこと
グーグルなどGAFAと呼ばれる米デジタル巨大企業群は、世界の公用語となっている英語や、これまでに蓄積してきた豊富なデータを武器に、自動翻訳、音声認識、画像認識、自動運転など次なるステージでも世界を席巻しようとしている。一方、日本はデジタル化が遅れている。司法の世界でも、機械学習に必要な電子データがそもそもそろわなければ、人工知能法学もすぐに限界に突き当たるのではないか。法務省はようやく年間20万件に及ぶ民事裁判の判決を社会に開放する検討を始めたという。データは公共財との認識のもと、研究やビジネスに利用できる体制を早急に作ってもらいたい。(読売新聞 山田哲朗)