Dec. 2017No.78
Interview
機械学習でウェブデータに隠れた 規則性を明らかに
ユーザーの検索や投稿からニーズや流行を推定する
当プロジェクトでは、巨大グラフの代表的なものの一つであるウェブに関して、計算の高速化や新たな知見を抽出するためのアルゴリズムについて目覚ましい成果を上げている。例えば、ウェブ検索で使用される検索クエリ(問い合わせ)からユーザーの意図を推測するためのパターンを抽出する新たな手法の開発や、ウェブ上で流行する情報の目利きに関する研究なども手がけた。これにより、ウェブ検索の性能を改善したり、流行の検知やターゲット広告、マーケティングの高精度化に役立てたりできるという。機械学習の技術を応用した新たなアルゴリズムについて、当プロジェクトの小西卓哉特任研究員に話を聞いた。

小西卓哉Takuya Konishi
国立情報学研究所 ビッグデータ数理国際研究センター JST ERATO「河原林巨大グラフプロジェクト」グラフマイニング&WEB&AI グループ特任研究員
検索クエリからユーザーの意図を探る
「河原林巨大グラフプロジェクト」では企業との共同研究が多い。小西卓哉特任研究員による検索クエリからウェブ検索ユーザーの意図を探る研究もそのうちの一つ。ヤフー株式会社との共同研究だ。
検索クエリとは、ユーザーが入力する検索エンジンへの問い合わせ、平たくいえば検索キーワードのことだ。単語を組み合わせて検索することが多く、これはユーザーの検索意図を理解するための手がかりとなる。小西特任研究員は「検索クエリという情報を膨らませて、ユーザーが背後に考えていることを探りたいと思っています」と語る。
似た用途で使われるクエリには共通パターンがある。例えば「神保町・ホテル・格安」と「箱根・旅館・高級」というクエリがあったとする。二つのクエリに含まれる単語はそれぞれ「地名」、「旅行」、「条件」という共通する「トピック」を持つと考えられる。これらトピックを組み合わせることで、二つのクエリは「地名・旅行・条件」という同じパターンで表現できる。このようなトピックの組み合わせからなるパターンを見つけるのが、この研究の目的だ。
パターンがわかれば、ユーザーが考えていることを知るための手がかりになる。前述の例であれば「旅行したいんだな」と推測できる。クエリの提案や広告の推薦も可能だ。以前に入力した検索キーワードに似た広告が提示されることがあるが、そのためには特定のキーワードが入力されたらこの広告を出すようにと事前に指定する必要がある。クエリの背後にあるパターンがわかればもっと簡単にユーザーに適切な広告をマッチングさせることに応用可能だ。
教師なし学習でトピックを自動推定
パターンを見つけるには、キーワードとパターンに対応するトピック同士の対応付けと、トピックと単語の対応関係を見つける必要がある。例えば「神保町」は地名だ。だが検索エンジンにとっては自明ではない。同様に「東京」や「福岡」といった単語も、同じ地名のトピックに属する。なお、ここでいうトピックとは単なる単語の分布のことだ。では、こういったことを学習させるためにはどうすればいいか。
このような場合、「確率的潜在変数モデル」がよく使われる。各トピックを潜在変数とし、そこからクエリが確率的に生成されるモデルを想定する。実際にわかっているのはクエリなので、単語の離散確率分布=トピックをクエリログ(検索キーワードの履歴)から「教師なし学習」を行い、データの背後にある規則性を見つけて、トピックの推定を行う。
学習の高速化と新たな知見の発見
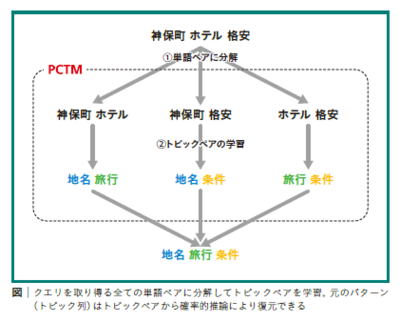
小西特任研究員たちは提案手法を「Pairwise Coupled Topic Model(PCTM)」と呼んでいる。特徴はクエリを取り得る全ての単語ペアに分解してトピックペアを学習すること。これにより、トピック同士の共起をモデリングできる、つまりトピック同士の関係を見ることができる。トピックペアごとに学習することで元のトピック列情報を保持でき、かつ低コストで学習できる(図)。
学習をさらに高速化する方法も併せて提案している。この方法では、トピック同士の関係の強さに着目する。例えば、旅行トピックは地名トピックとは結びつきやすいが、電化製品トピックとは結びつきにくい。そこで、後者のような関係の弱いトピック同士の学習にかかる計算時間を短縮する。こうすることで、トピック同士のつながりを表現することと実用的な計算時間を両立できた。性能を落とさずに10倍以上高速になったという。
既存手法ではトピック同士のつながりを見ていなかったため、例えば観光トピックと地名トピックが混ざって表現されていたが、PCTMではそれぞれを別々に表現することもできた。
また、教師なし学習でカテゴリ分けさせることで、人が気づかなかったつながりを見いだすこともできた。例えば同じ地名トピックでも、地域ごとの特性によって観光と結びつきやすいもの、賃貸や不動産、病院などより生活感の強い単語と結びつきやすいもの、より遠隔地の旅行関連単語と結びつきやすい地名がある。つまりペアとして強いつながりを持つ地名が異なることがはっきりわかるのだ。このようにデータから新しい規則を発見するデータマイニング的知見が得られる点も、優れているところだと小西特任研究員は語る。
なお、実際に使ったのはおよそ100万クエリデータだ。これはヤフーで1日に入力されるクエリの一部に過ぎないが、有意なトピックの表現を得ることができるのだ。
流行の素早い検知やユーザーの好みの推測なども
小西特任研究員は、他にウェブ上で流行する情報を早期に察知するユーザー(観測者)の発見という研究も行っていた。SNS上ではしばしば特定の流行が発生する。中には他の人に先駆けて流行の端緒となる目の付け所がいい人もいる。そのような人を「観測者」と呼び、自動的に観測者を見いだすことをめざした。観測者をフォローすれば、流行し始めのときにいち早く情報に気づくことができる。小西特任研究員たちは機械学習を使ってこのような人を推測できる方法を構築し、精度よく見いだすことができるようになった。興味深い点は、観測者は単にフォロワーが多い人とは限らないということだ。
他にも音楽レコメンドのためのアルゴリズムの開発も行った。これは、利用者が楽曲を聴いたり、評価したりする行動から、利用者の好みを推測し、推薦曲を選ぶというもの。利用者の好みをより正確に反映した推薦曲を速やかに選定できるほか、単に好みの曲を推薦するだけでなく、利用者自身が自覚していない好みまで抽出することで、レコメンドの精度を高めるとともに、アルゴリズムの高速化も実現。実際にスマートフォン向け音楽配信サービスに採用された。小西特任研究員は、「研究用に整えられたものではない、実際の生データを扱う体験ができた点が面白かった」と言う。
今後はデータとデータの連携が重要に
小西特任研究員は、今後は単なる予測やパターンの発見だけではなく「もう少し深いことを知りたい」と語る。すなわち、ユーザーの行動の背景や因果関係だ。例えば流行の背景にはユーザー同士の因果関係もある。観測者の目の付け所がいいのはたまたまなのか、それとも本当にエキスパートなのか。そこを探るためには、データをさらに深掘りするだけではなく、他のデータとの連携を考えないといけないのではないかと言う。「より難しい問題に取り組みたい。単純な指標で良かった悪かったではなく、背後にあることを理解したいと思っています」
(取材・文=森山和道 写真=佐藤祐介)