Mar. 2018No.79
Interview
AIによる画像認識を 内視鏡診断に生かす
医療ビッグデータの社会還元をめざして
日本消化器内視鏡学会では、2016 年度からNIIとともに、日本医療研究開発機構(AMED)の採択課題「全国消化器内視鏡診療データベースと内視鏡画像融合による新た な統合型データベース構築に関する研究」に取り組んできた。学会がこのようなプロジェクト研究を行う意義、これまでの成果、今後の展望を同学会の田中聖人氏に聞いた。

田中聖人Kiyohito Tanaka
1990年京都府立医科大学卒業、同年、京都第二赤十字病院消化器科に。以来、別の病院に勤務した年間を除き、同病院に在籍。消化器内視鏡のうちでも特に膵胆道が専門。その一方で、手術室のデータ分析、物流管理、新たな電子技術の病院での実質運用への取り組みなど医療ICTにも取り組む。
画像情報をテキストで集める
─ 日本消化器内視鏡学会では、今回のAMEDのプロジェクトに先駆けて、2015年から多施設内視鏡データベース構築プロジェクト"Japan Endoscopy Database Project(JED)"を開始されました。このプロジェクトについて、まずお聞かせください。
田中 JEDを始めた大きな理由は、患者さんが受けた内視鏡検査の情報を、患者さんに還元するためです。日本では、1年間に1600万件もの内視鏡検査が行われています。そのデータを俯瞰して解析すれば次の診断・治療に役立ちますが、それを一病院で行うことは難しい。そこで、学会がやろうということになったのです。
─ JEDでは、どのようなデータを収集していますか。
田中 日本では、画像診断や病理検査の結果報告書は、文章で書かれることが多いのですが、それだと、例えば、胃がん、胃癌、gastric cancerなど、用語・表記がばらばらになります。また、ある病気の疑いがあるかどうかが文末までわからない場合もあり、データベース化はとても難しくなります。
そこで、JEDでは、所見を標準化したテキストで集めることにし、「胃がん」といった病名や、ピロリ菌による萎縮の程度を表す表示などをコンピュータのマウスで選んで入力するソフトを内視鏡メーカーとともに開発しました。すでに9施設から68万件のテキストデータを収集していますが、集めたデータは、表現のゆれがないので解析が容易です。
NIIとの出合いで研究が一気に進展
─今回のプロジェクトでは、そのJEDのテキストデータをもとに画像を収集されたのですね。
田中 一般の内視鏡検査では、1回に40枚程度の撮影をします。JEDでは、そのうちで胃がんなら胃がんがよく現れているものを数枚選び、標準化されたテキストと合わせて結果報告書としています。つまり、タグ付けされた画像データがすでにあるのです。ですから、いずれはJEDで画像も収集したいと考えていました。
しかし、画像データはサイズが大きいので、輸送、格納に大きなコストがかかりますし、我々には画像データの解析手段もありませんから、実現には時間がかかると覚悟していました。そんな中で、AMEDからNIIと共同研究してはどうかという示唆をいただき、2016年度に課題が採択されて、プロジェクトが始まったのです。
─どのような画像を集め、その画像をどのように利用したのですか。
田中 テキストのタグを利用して胃がんの画像を集め、その画像をAIが学習して、胃がんを見つけられるようになることを目標としました。胃がんを診断するには、正常な胃の画像も必要ですから、それもタグを利用して集めました。AI学習の部分をNIIにお願いしていますが、患者さんの画像を使わせていただくわけですから、すべて匿名化してからNIIにお渡ししています。
─苦労したのはどのような点ですか。
田中 結果報告書のために選んだ画像だけを内視鏡のシステムから取り出すところがたいへんでした。簡単そうに思えるのですが、「選んだ」というアクションの痕跡を見つける必要があるために難しいのです。さらに、内視鏡はビッグデータを集めることを想定していないので、データを1症例ずつしか取り出せないという問題もありました。このため、メーカーの方たちにがんばっていただき、タグで選んだ画像をまとめて自動的に取り出せるソフトがようやくできあがりました。
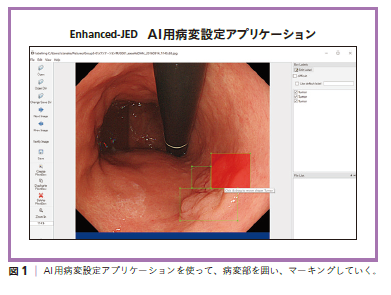
データ収集ソフトの完成を待っていたのでは、NIIがAI学習の研究に取りかかれないので、先に四つの施設から1万4000枚の胃がんの画像を人力で集め、そのうちの7000枚は病変部をモニター上でマークして(図1)、AIに病変部を教える「教師画像」としました。NIIとのディスカッションで決めた基準からずれないように、7000枚のマーキングをしました。
出口戦略を重視し、確実な社会還元を
─どのような成果があがっていますか。
田中 NIIでは、東京大学、名古屋大学、九州大学のグループがそれぞれの手法で深層学習によりAI に画像を学習させ、いずれもよい成績で胃がんを見分けられるようになってきました。収集した画像をどんどん学習させることで、AI がさらに賢くなると期待しています。
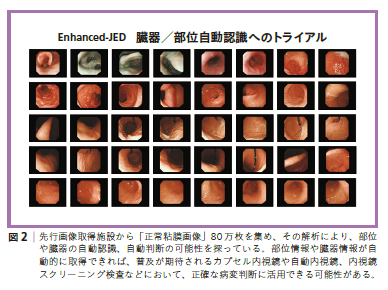
一方、正常な胃の画像を80万枚与えたところ、AIが60のグループに分けてくれました(図2)。私が画像をすべて見て確認したところ、このグループは、食道から胃までのさまざまな部位にほぼ対応していました。これは予想もしていなかったことで、感心しました。AIのこの能力は、画像から部位を推定するのに活躍すると思います。
─今後の展望をお聞かせください。
田中 NIIとやりとりする中で、マーキングの問題点や内視鏡機器に必要な機能もわかってきました。また、胃がんは大きく5種類程度に分けられ、内視鏡医はその5種類のうちのどれかまでを診断していますが、今回は、そこまで行っていません。プロジェクトは2018年3月末で終了するので、次年度以降も課題を採択していただけるよう努力し、胃がんのより詳細な分類、つまり病理学的な診断ができるレベルまでAIを賢くできたらと思っています。もちろん、診断をするのは内視鏡医ですし、生検試料の病理検査も必要な場合がありますが、診断の大きな助けになるはずです。
ただし、すばらしいAIができても、それが内視鏡機器に搭載され、患者さんの役に立たなければ意味がありません。メーカーと学会、NIIが協力して研究を発展させ、確実に出口につなげることが重要です。
─医療ビッグデータ研究センターへの要望があればお願いします。
田中 医療画像のAIに携わる人材は不足していると感じます。この分野を発展させるには、ビッグデータのもとに多くの研究者が集う仕組みが必要ですので、ぜひそのためのセンターとして機能していただきたいと思います。そして、センターの成果を国民に還元し、その業績を広報することにも力を入れていただきたい。そうすれば、画像を提供する患者さんにも、自分のデータが医療の発展に役立つことを実感してもらえることでしょう。
(取材・文=青山聖子 写真=佐藤祐介)