Jun. 2019No.84
Article
人はなぜ見える、なぜ認識できる数理モデルを設計、追究していく
いよいよ画像、文章、音声をまとめて扱える
描きたい光景を説明する文章を入力すれば機械(コンピュータ)が絵を出力する。画像に隠されている人間が判別しにくいカモフラージュ物体を機械が見つけ出す。NII の杉本晃宏教授が取り組む研究はどれも楽しい。研究の動機は一貫している。「ものを見るということはどういうことか。なぜ人は見たものが何かを判別できるのか?」。この疑問を解くために、人が認識する仕組みを推測し、数理モデルを設計、機械で動かし、検証を繰り返している。

杉本晃宏SUGIMOTO Akihiro
国立情報学研究所 コンテンツ科学研究系 教授/総合研究大学院大学 複合科学研究科情報学専攻 教授
谷島宣之Nobuyuki Yajima
ヒル社(現・日経BP社)に入社、『日経コンピュータ』誌の記者になる。2009 年から『日経コンピュータ』編集長。2016 年から現職。
できなかったことができるように
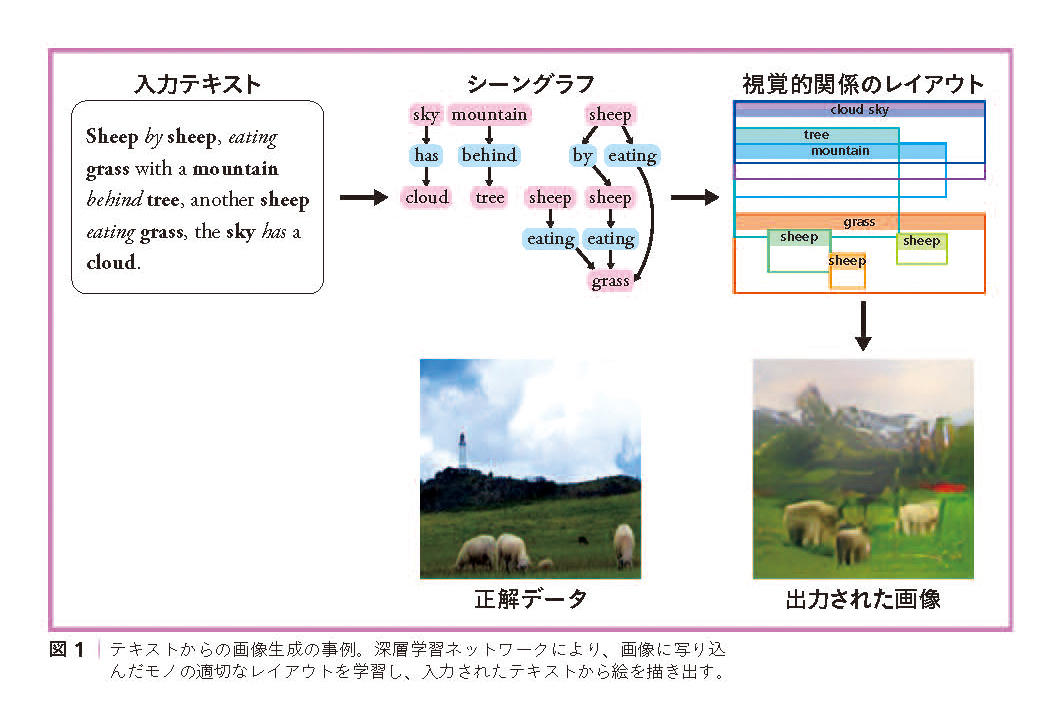
"Sheep by sheep, eating grass with a mountain behind tree, another sheep eating grass, the sky has a cloud." この文章を入力すると、羊が草原にいる絵を機械が描いてくれます。意味に基づいて画像をつくる「テキストからの画像生成」と呼ばれる研究テーマの実践例です。
音声認識の技術と組み合わせれば、人がしゃべっている内容をそのまま絵にすることもできます。逆に既存の絵や写真を機械に認識させて、どういう画像なのか説明をする文章を出力することも可能になるでしょう。すなわち画像、文章、音声を組み合わせて扱えるというわけです。このことはかつて「マルチメディア処理」と呼ばれましたが、ようやく現実の技術になってきたと言えます。画像認識は画像認識、音声認識は音声認識とそれぞれ個別に発展してきた技術をまさに融合できる段階になったのです。
羊たちの絵をきちんと描くために、文章に出てくるいろいろな物体同士の関係からそれぞれの物体の適切な配置、つまりレイアウトを導き出す手法を開発しました。この手法を使うと、羊たちが空に浮かんだりせず、草原にいるように描けます。レイアウトの推定には深層学習ネットワークを使っています。
まず、入力する文章とその通りに描かれた絵、すなわち正解データを用意します。絵に描かれているいろいろな物体を認識して切り出す技術を使うと、物体と物体の配置に関する正解データを得ることができ、それをネットワークに学習させます。このネットワークと、文章から言葉を抽出して「シーングラフ」と呼ばれる言葉同士の関係を導く既存手法を組み合わせると、シーングラフからレイアウトをつくり出すことができるというわけです(図1)。
深層学習を使った画像生成では他のテーマにも取り組んでいます。花が写り込んだ画像と「白い花だけを黄色にする」という指示を文章で与え、複数ある花のうち該当するものだけを機械に描き替えさせるのです。この場合、画像の前景と背景を別々に把握する必要があり、識別のための深層学習ネットワークを二通り用意しています。こうしておけば前景となる白い花だけを描き直し、背景をそのまま残しておけるわけです。逆に背景だけを描き替えることもできます。
「画風変換」にも取り組みました。もしゴッホや北斎が生きていたとしたら、今ある風景をどう描いたでしょうか。そこで、風景の写真や絵、動画と画風を機械に読み込ませて、ゴッホ風あるいは北斎風に変換できるようにしてみました。
画風変換にはこれまでいろいろな取組みがありましたが、私が工夫したのは風景などのコンテンツの特徴を認識する深層学習ネットワークと、ゴッホの絵から画風、つまりスタイルの特徴を学ぶネットワークを別々に用意したことです。風景の認識と画風の習得では役割が違うからです。
二つのネットワークを組み合わせることでバランスの良い画風変換ができるだけでなく、画風を強調したり元の絵を強調したりといった調整もできます。一つのネットワークだけにゴッホや北斎の絵を大量に読み込ませても画風変換はできますが、そのやり方ではでき上がった絵を調整する機能がありません。
現象の本質をとらえる、それが醍醐味
画像生成や画風変換の例からおわかりのように、機械に何かをさせる場合、どんな機能が必要でそれらをどう組み合わせればよいかを考え、設計する必要があります。それを数式で記述したものを数理モデルと呼びます。
いろいろな現象の本質をとらえ、数理モデルで表現する。このモデル化こそが数理工学の醍醐味です。知恵を絞ってモデルをつくる。それさえできれば、後はモデルをどう動かすかという話になりますが、そこは誰がやってもいいのです。
画像を見て、それを認識するモデルを設計する時には、人間ならばどうしているかと考えます。例えば、人間でもすぐには認識できないカモフラージュ画像を機械に認識させるにはどうすればいいか。人間の場合、説明なしにカモフラージュ画像を見ても隠されている物体になかなか気付けませんが、あらかじめ「ここに何かいます」と言われると、比較的短時間でそれを発見できます。
そこで画像から重要な物体を切り出す学習ネットワークに、「物体がある、ないを判断する機能」を付け加えると、カモフラージュ画像の中に隠されている物体を機械が読み取れるようになりました。
私たちは、静止画あるいは動画から、人の視線を引きつける物体を切り出す学習ネットワークも開発しています。これなら物体が重なっていても重なりを認識して切り出すことができます。各々の物体の目立ち方には差があるので、それを利用して、目立つものから順に切り出していくのです。

見る、わかるは奥深い研究テーマ
以上の一連の研究に取り組んだ動機は、「見るとはどういうことなのだろうか。そして見たものが何であるか、どうして人はわかるのだろうか」という好奇心からでした。このような思いを抱いたのはまだ幼い時で、それ以来、同じ好奇心を持ち続けています。
人間はものをこういうふうに見て、こんなふうに認識しているのではないか、と推測し、それをモデルにして機械で動かす。成果が出れば、少しずつですが、人が見る、人がものを認識するための仕組みに迫ることができるはずです。
モデル化することで、実験結果を積み重ねてモデルを改善していくことができます。それが科学というものでしょう。大量の画像とそれらに対する人間の認識結果を正解データとして用意し、深層学習ネットワークに読み込ませると、人間の認識率を上回るような結果を出せるようになってきましたから、これを使わない手はない。とはいえ、設計思想を持たずやみくもにモデルを改善するだけでは、たとえ性能が向上しても何の知見も得られず、お金をかけてコンピュータパワーを大きくし、大量のデータを用意するという単純な競争になりかねません。
いろいろな研究を続けてきましたが、「なぜ見たものを人は認識できるのか」という疑問は実に奥が深く、わからないことのほうが多いのです。幼い頃の好奇心を忘れず、興味の赴くまま、研究を続けています。
(取材・文=谷島宣之 写真=佐藤祐介)
インタビュアーからのひとこと
子どものような好奇心と冷静な科学者あるいは技術者の態度、その二つが研究者には求められる。子どもの頃の好奇心は大人になるとなくなりがちだが、杉本教授はそれを持ち続けている。その一方、必ず設計思想をもって数理モデルを構築し、結果を検証してモデルを改善する、科学者の姿勢を保っている。コンピュータパワーに物を言わせ、正解率さえ上がればそれでよいとする単なる子どもっぽさとは無縁である。