Sep. 2020No.89
Interview
世界中のCOVID-19情報が俯瞰できるサイトを構築
自然言語処理研究者たちによるコラボレーション
新型コロナウイルス感染症の拡大を受け、自然言語処理の研究者たちが各自の専門性を活かしてCOVID-19に関する世界中のさまざまな情報を集約し、日本語で提示するサイトを短期間で構築した。このコラボレーションはどのように進められたのか。プロジェクトから得られたものは何か。プロジェクトの開始時から参加しているNIIの相澤彰子教授に聞いた。

相澤彰子Akiko Aizawa
国立情報学研究所 コンテンツ科学研究系 教授/副所長
東京大学大学院 情報理工学系研究科コンピュータ科学専攻 教授/総合研究大学院大学 複合科学研究科 教授

聞き手濱門麻美子Mamiko Hamakado
岩波書店 自然科学書編集部 編集長
東北大学理学部卒業、東京大学大学院理学系研究科博士前期課程修了、理学修士。1993年、岩波書店入社。自然科学書編集部に配属され、認知科学・言語学・数学などの書籍を担当。2015年より現職。
研究者コミュニティとして取り組んだプロジェクト
─「COVID-19世界情報集約サイト」とはどんな内容ですか。
相澤 サイトの構造は、「表」と捉えていただくとイメージしやすいでしょう。縦・横に2つの直交する軸(項目)があり、1つの軸は日本/中国/アメリカ/ヨーロッパ/アフリカといった「国・地域」です。もう1つの軸が感染状況/予防・防疫・緩和/医療情報といったトピックの「カテゴリー」です(図1)。サイトに行くと、「国・地域」×「カテゴリー」からなる表の情報を見せる窓が並んでいます。じつは、この表にはさらにもう1つ、時間軸があります。ほぼリアルタイムで情報を収集していて、それぞれの窓のなかで新着順に記事が並んでいます。
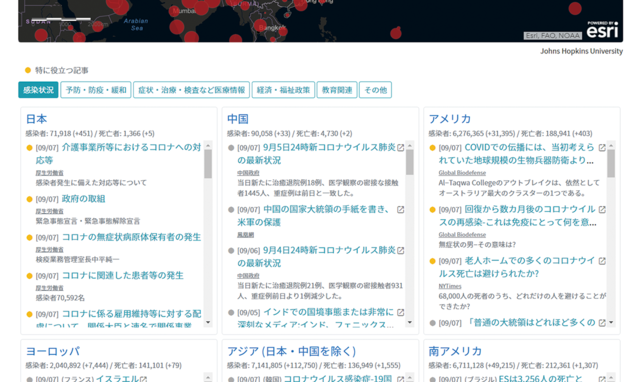
─どのようにしてこのプロジェクトが始まったのですか。
相澤 せっかく自然言語処理の研究者がいるのだから、この状況で何か役に立つことをしたらどうかという、NIIの喜連川優所長からの提案がきっかけです。その提案に賛同した研究者たちが議論を始めて、プロジェクトのメンバーが集まりました。東日本大震災のときも、若い研究者がボランタリーに震災関連の情報収集に取り組む活動はありましたが、世界中の研究グループがこれほど大規模に迅速に動いたのは、自然言語処理分野でも今回が初めてだと思います。分野の中核となる国際会議でも、立て続けに COVID-19のワークショップが緊急開催され、主催者の予想を超える60本以上の論文が集まりました。
各研究室で役割を分担してサイトを構築
─サイトの設計はどんなふうに行ったのですか。
相澤 京都大学の黒橋禎夫教授や早稲田大学の河原大輔教授がラフなスケッチをつくって、みんなで議論しました(図2)。先ほどお話しした2つの軸として何を設定するか、つまり、どの国から情報を集めて、どういうカテゴリーにまとめ上げるかという点は、試行錯誤しながら決めていった部分です。
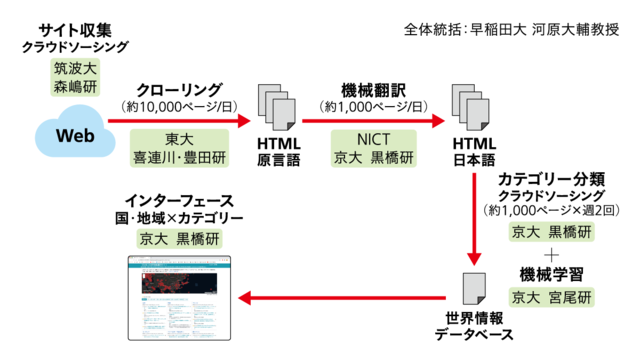
─サイト構築の流れはどうなっていますか。
相澤 まず、情報ソースを決めます。信頼できる情報を集めるために、政府系などを中心に、定期的に最新の情報を収集する先のサイトのリストをつくります。このサイトの選定にはクラウドソーシングも使っています。その国・地域のクラウドワーカーが信頼できると確認したサイトを収集先にするのです。 収集先に決まったサイトをクローリング(巡回・収集)しますが、クローリングにもかなり技術が必要です。サイトの内容は頻繁に更新されるので、毎日その内容をチェックしに行きます。ページ内に埋め込まれた参照コンテンツへの対応も必要です。そうした作業を経て、クローリングしてきたページはいろいろな国の言語で書かれているので、機械翻訳にかけてすべて日本語にします。ご存じの通り、昨今の機械翻訳はたいへん性能がよく、文書の内容をつかむには十分です。 もとの言語と日本語がそろったページができたら、「国・地域」ごとの「カテゴリー」に記事を振り分けます。記事数が多いので、現在は機械学習を使って、ほぼ自動的に振り分けています。こうしてできたデータベースを、いま見えているサイトのインターフェースで表示します。 それぞれの要素技術は、このプロジェクトのために考案されたものではありませんが、それらを組み合わせて動かす意義は、単なる1+1=2の足し算ではありません。IBMが開発した人工知能(AI)であるWatsonが、2011年にクイズ番組で人間のチャンピオンを破ったときも、ポイントは個々の要素技術ではなく、それらを組み合わせて動かしたところにありました。
サイト拡張の可能性も視野に
─今後はどんな展開が考えられますか。
相澤 いろいろなモジュールを考えて、このサイトに組み込んでいく可能性があります。自由にお試しの機能をテストできるところがサイトを手づくりする魅力で、可能性はいくつか話題にのぼっています。たとえば、時系列の解析があったらいいな、とか。このサイトは新しい記事が追加されてどんどん流れていくのですが、何月何日頃にどういう話題がどこで盛り上がっていたかといったことが可視化できると、俯瞰性が高まります。 また、Twitter のようなソーシャルメディアと結びつける、論文などの専門的知識とつなげていく、というのも拡張の方向性として考えられます。
プロジェクトの意義と見えた課題
─このプロジェクトの意義をどうとらえていますか。
相澤 「誰かの役に立つことができれば」という気持ちで始まったプロジェクトですが、プロジェクトの参加者にとっても、サイトの構築を通して、世の中ではこういうことが求められているんだとか、いまの自分たちの技術ではこういったところが足りないんだとか、そういう知見が得られることは研究面での価値だと思います。 COVID-19に関しては、米国のアレン人工知能研究所がいろいろな研究所や機関と協力して関連の論文を集めたデータセットを構築しています。そのデータセットを使ったテキストマイニングの研究で浮かび上がった課題の 1つが、COVID-19に関する専門用語の辞書がないことです。専門用語を論文から抽出するには、人手をかけてタグ付けをしたアノテーションデータが必要なのですが、それが十分にないのです。アノテーションデータのような足場がないと、詳細な分析ができません。生命科学は専門用語辞書やオントロジーが非常によく整備された分野ですが、それでも今回のようなことが起きると、やはり足りないことがわかります。信頼できるアノテーションが効率的にできるような仕組みを、いかに少ないデータでつくっていくかが技術的な課題です。 「COVID-19世界情報集約サイト」の話に戻ると、ここでもアノテーションに関する新鮮な驚きがありました。クラウドソーシングに出せば何でもできると思っていたけれども、言語、地域、カテゴリーが変わると、十分なクラウドワーカーが確保できないことが当たり前に起きることです。あるドメインにおけるAIシステムの成否が、そのドメインのデータをアノテーションできるクラウドワーカーが確保できるかどうかにかかっていると考えると、この問題は非常に大きなバイアスや格差をもたらし得るものだと実感しました。世界中で同時に起きているリアルな社会の膨大なデータを扱って初めて知ったことです。
インタビュアーからのひとこと
世界中の情報が日本語で俯瞰できるこのようなサイトは、政治・行政やマスコミにまず利用してもらい、目配りの利いた政策や報道に活かしてもらいたいと感じた。 本文中に機械翻訳の精度向上への言及がある。今回の原稿を作成するにあたり、音声を自動でテキスト化するサービスを利用してみて、実用性のある域に入っていることを知った。機械翻訳に限らず、自然言語処理技術の恩恵をダイレクトに感じることの多い昨今である。