Mar. 2016No.71
Interview
実環境データを情報学研究に活かす
「データセット共同利用研究開発センター(DSC)」の役割
ディープラーニングなどの人工知能技術やビッグデータ処理技術は近年、産業応用が加速している。その一方で学術研究にも早期実用化や産業への応用が社会的に強く求められるようになり、実社会で生まれるデータを用いることがより重要になっている。そこで実環境で蓄積された大規模データを情報学研究に活かす使命を担って設立されたのが、NII の「データセット共同利用研究開発センター(DSC)」だ。センター長の大山敬三教授が、研究者と産業界をつなぎ、知的財産やプライバシーの保護という課題にも取り組みながら、研究資源であるデータの受け入れと提供を行うセンターの意義について語った。

大山敬三OYAMA Keizo
国立情報学研究所 データセット共同利用研究開発センター長・コンテンツ科学研究系 教授 / 総合研究大学院大学 複合科学研究科 教授・情報学専攻長
研究者と提供企業双方にメリット

近年、大規模データ処理技術は、新しいビジネス創出やサービスの高度化に欠かせないものとして、その研究成果の早期実用化が強く求められています。とくに統計的機械学習やビッグデータ解析などの研究分野には、大きな期待が寄せられています。この社会的要請に対応するためには、従来のような研究者による研究用の手作りデータでは不十分であり、実社会から得られた大規模な実データの入手が不可欠です。
一方、産業界ではネットビジネス企業が本格的な研究組織をスタートさせたり、先端技術を持つベンチャー企業が市場に足場を確保したりしているように、最新・最適な技術を採り入れることが競争力の源泉になっています。しかし、自組織内の研究だけでは不十分であり、自社のデータを提供してでも大学などの公的研究機関と共同研究したいという企業が増えてきました。専門的な研究を行う大学院生らにデータを提供することで、自社への関心を高めてもらい、優秀な人材の確保につなげたいという狙いもあります。
このように研究者と企業の利害が一致する面はあるのですが、実際に研究者が企業と個別に交渉するのは難しい。また、企業のデータには機密情報、著作権、プライバシー保護など多くの制約があり、個別に複雑な利用条件を調整してデータを準備しなければなりません。そこでDSCが双方の間に立ち、企業などからデータを受け入れて、一定のルールに基づいて研究者に提供する役割を果たしているのです。
続々と出てきた研究成果
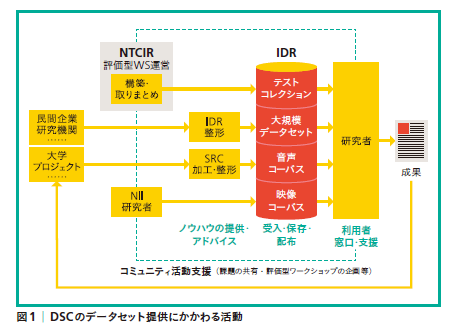
DSC 設立のそもそものきっかけは、NIIが1997年末にスタートさせた評価型ワークショップである「NTCIR(NIITestbeds and Community for Information access Research、エンティサイル)」のために提供されたヤフー株式会社の「Yahoo!知恵袋データセット」です。このデータはワークショップ以外の研究目的でも多くの大学や企業の研究機関に提供され、さまざまな研究が行われました。この成果が注目され、NIIを通じて研究者にデータを提供したいと手を挙げる企業が徐々に増えてきました。そこでNIIは2010年にデータの受け入れと提供を行う窓口として「情報学研究データリポジトリ(IDR)」を設け、さらにデータの共有と活用を進めるために、2015年4月にDSCを設置しました。DSCはNTCIRの運営、IDRの窓口、およびNIIの「音声資源コンソーシアム(SRC)」の活動を統合し、研究資源としてのデータを核としたオープンサイエンスの推進を目指しています。
DSCでは現在までに民間企業6社から14種、国文学研究資料館から1種のデータセットの提供を受け、NTCIRのテストコレクションやSRCの音声コーパスなど数十種を加えて、情報学や関連諸分野の研究者に無償で提供しています(表1、図1)。データはテキストのほか画像、音声、映像も含んでおり、一部を除きインターネットからダウンロードして利用できます。
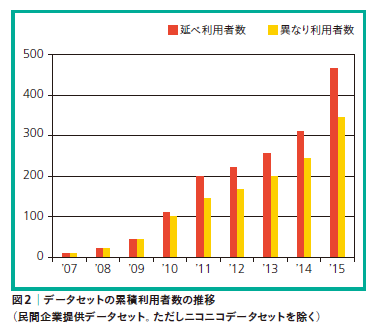
データセットの利用状況を見ると、個別にデータを提供していた2007年から利用者数は順調に伸びています(図2)。また、データセットを利用した研究成果の論文は2014年末時点で350本、利用研究室は2015年11月末時点で468と、どちらも増加傾向が加速しています。
研究成果は実に多様で、たとえば、料理レシピデータを自動的に解釈し、複数の作業を並行して行うフロー図を作成する研究、Q&Aデータから問題に対する最適解決策を求める研究、動画へのコメントデータから楽曲のサビを推測する研究などが出てきています。
情報の保護をクラウド化で解決
これからますます実用性の高い研究が出てくることを期待していますが、そのためには一層多様なデータが必要になります。そこでの一番大きな課題は、データに含まれている可能性がある潜在的なプライバシーや機密情報をどう保護するかという点です。たとえば、提供データセット自体には個人情報が含まれていなくても、他のデータと突き合わせると探り当てられてしまうことがあります。実際に、米国のAOLが検索クエリデータを公開したところ、利用者が特定されてプライバシーが暴露されるという事件が起こりました。これが今でも企業にデータ提供をためらわせる一因となっています。
IDRでは現在のところ、「覚書」を交わすなどによって決められた利用上の条件を守ってもらうようにしていますが、いずれはクラウド上で安全にデータを利用できる仕組みを導入したいと考えています。提供方法としては、ダウンロード禁止などの利用制限つきで提供する、APIを通して統計処理した結果だけを返す、利用者がプログラムを作成・登録してクラウド上で実行することによりプログラムからのみデータアクセスできるようにするなど、さまざまなバリエーションを検討しています。
データを守りつつ活用を促進するためには、クラウド利用を前提とすることによって可能となる技術を使い、企業が求める安全性と研究者が望む利用方法との現実的な折り合いをつけることが不可欠でしょう。それに向けて現在は企業との共同研究を進めている最中で、来年度中には具体的な結果を出していきたいと考えています。
(構成・文=土肥正弘 写真=佐藤祐介)