Dec. 2014No.66
Article
「数理」と「アルゴリズム」と「熱血」が新しい扉を開く
膨大なデータの中から頻出するパターンとその相関関係を発見し、分類し、傾向を明らかにして未来予測にまでつなげる「発見的」なデータ分析技術、「データマイニング」。その研究の第一線で活躍するのが有村博紀教授と宇野毅明教授だ。2004年、両氏が開発した「世界最速」のデータ分析プログラムは国際的なデータマイニング実装コンテストで優勝。以来、二人三脚で数々のデータ分析アルゴリズムを開発し、ビッグデータ分析に多大な貢献を続けている。両氏に、その研究の歩みについて語っていただいた。「数理」「アルゴリズム」「応用」の密接な関係が見えてくる。

有村博紀ARIMURA Hiroki
国立情報学研究所 客員教授 / 北海道大学 大学院 情報科学研究科 コンピュータサイエンス専攻 教授

宇野毅明UNO Takeaki
国立情報学研究所 情報学プリンシプル研究系 教授 / 総合大学院大学 複合科学研究科 情報学専攻 教授
「知識創出学」の推進者と数理科学研究者との出会い
─お2人が共同研究を進めるに至った経緯を教えてください。
有村 私はもともと科学好きの少年でしたが、実はあまり数学が得意ではありませんでした。ところがある時、連続した量の変化を扱う基本の数学とは違った数学があることを知りました。それが「離散数学」、いわば量よりも質、モノとモノとの関係を調べるための数学です。そこで、九州大学の計算機科学の権威で、後に九大総長も務められた有川節夫先生の元を訪ねたのが、今の研究に携わるきっかけとなりました。先生のお話から、コンピュータでできることとできないことが数学的に証明できることや、微分・積分などの計算をしなくても、離散的に物事を捉えることで十分に社会の役に立つことを知り、「モノの数学」である離散数学の魅力にとりつかれてしまったのです。そのときすでに就職していましたが、有川先生の研究室に入り直し、研究者の道を選びました。以来、勉強をしているという意識もなく、離散数学とその応用を楽しんで過ごしてきた感じです。
その後、データマイニングと出会ったのは1996年頃のこと。アメリカでは大量に蓄積されたデータの「全体を見る」ことと、「個々の詳細を見る」ことの両方の研究が進んでいました。そこに魅力を感じ、人工知能や機械学習の研究とともに取り組んできました。北海道大学に移ってからは、異分野の科学研究者との交流を深め、膨大な量におよぶ生物の遺伝子の収集と解析や、深海調査艇から得られる深海生物の形態情報・遺伝子情報の統合、あるいはロボットや通信に関連するデータ解析など、領域をまたがる研究プロジェクトにおいて、データマイニング技術を応用して共同研究を進めています。異分野の知見を集めて新しい知識を創り出す研究を「知識創出学」と名付けて、取り組んでいるところです。
宇野 私のほうは小学生の頃からパズル好きで、コンピュータのプログラムづくりにも没頭していました。プログラムの背後にある数学、すなわち「数理最適化」にも面白さを感じていましたね。数理最適化とは、ある決まったルールとデータの枠の中で、最適な解を見つけること。究極の解ではないかもしれないが、問題解決に十分使える答えを見出すのです。
ちなみに同じ数理研究者でも、「数学理論」研究者と、「応用」研究者の2タイプがあるように思います。その違いは「モノ」に対する考え方。前者は「モノ」を前提にせず、究極の答を求める方法を考えます。後者はデータがあることを前提に、有限時間の中で処理する順番を考え、応用して役に立つ答えを求める。答は必ずしも1つとは限りませんが、限られた時間と少ない労力で最適な答えを導き出すための仕組みを考えるのです。
それが「アルゴリズム」のベースです。アルゴリズムは数理の一部ですが、時間と手続きの概念があるかどうかが、数学理論の研究とは異なる。プログラムは、いわばアルゴリズムの塊であり、私はその研究にずっと携わってきました。
私と有村先生を引きあわせてくださったのは、NIIの佐藤健教授です。佐藤先生は、幅広い分野の問題意識を持つ有村先生と、問題を解決するための数理研究が得意な私、つまり「問題を見つける人」と「解答を出す人」を合わせれば凄いことができる、と。以来、有村先生が問題を提起し、私が解決法を提案するというスタイルで研究を行っています。また佐藤先生はもう1つの素敵な提案をしてくださいました。当時、イギリスで開催されていた国際的なデータマイニング実装コンテストへの参加を促されたのです。

「数理」と「応用」のはざまで見出した最速アルゴリズム
─その国際コンテストで優勝されたのでしたね。
有村 コンテストはあらかじめ用意された問題をデータマイニングプログラムでどれだけ高速に解けるかを競うものでした。データマイニングは、アルゴリズムの洗練度により1,000倍は速度に差が出る世界です。佐藤先生は、宇野先生が開発されていた「極大クリーク列挙」という高速アルゴリズムをデータマイニングに応用すれば、必ず勝てると言う。宇野先生は「できます!」と即答でしたね。
宇野 そのアルゴリズムを応用すれば、データベースから頻出するパターンを高速に導き出すことができますから。つまり、膨大なデータの中から意味のある情報が簡単に引き出せるのです。
有村 2003年の最初の挑戦の時は、宇野先生がアルゴリズムを考え、私がモデルを考える形で研究を進めました。ところが、1位には届きませんでした。
宇野 アルゴリズムの観点からは自信を持っていたのですが、正直にすべてのデータを対象に処理をしていたのが敗因です。他の参加者の多くはデータベース技術者であり、データの扱いに長けていて、大量のデータのうち使わないものはデータを読み込む段階で捨てていたのです。
有村 その反省から2004年はデータをチューニングし、宇野先生がコーディングを、私ともう1人の共同研究者が実験を行う形で開発を進めました。最後には3交代制で昼夜を問わず実験とコーディングを繰り返しました。宇野先生は海外出張中でも、実験結果を伝えると8時間後には修正結果を戻してくれました。そんなハードワークを続けた結果、見事に優勝できました。
この「LCM (Linear time Closed itemset Miner) 」というプログラムは、一般に公開されています。これに用いられたアルゴリズムは、アソシエーションデータマイニング領域で今でも世界最速と言われています。この時の経験は、新しい扉を開くには「数理」と「アルゴリズム」にプラスして、「熱血」も必要だということを教えてくれましたね(笑)。

ビッグデータから役に立つ情報を取り出す最新技術
─ご研究の最近のトピックスをお聞かせください。
有村 現在、ビッグデータ分析が注目されています。SNSの書き込みやリンクデータ、移動端末の位置情報、建築物などに取り付けられた各種センサデータなど、多様で大量のデータが発生し、蓄積されていますが、そこから人間が理解できる「知識」を取り出すのは困難です。そこでデータマイニング技術では頻出パターンの発見や類似度を判定するクラスタリング、場合分けによってデータを分類する「決定木」などの手法を使って、人間にわかりやすい大きさ(粒度)の情報を取り出すことを目指しています。
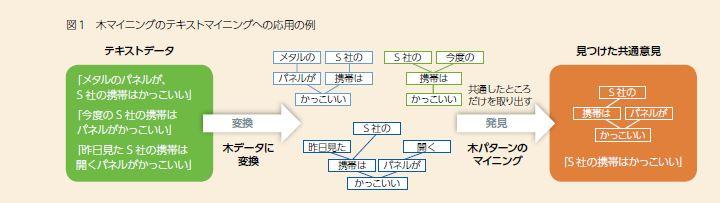
例えばWebページのデータ、化合物のグラフ構造、自然言語のかかり受け木構造データなどから、特徴的な部分構造を、小さな木のパターンとして発見するアルゴリズムを開発しています。図1はオンラインデータベースの木構造から、くり返し出現するテンプレート構造を見つけた例です。
宇野 ビッグデータから意味ある情報を得るには、データを研磨して、おおまかなクラスターに分類して把握しやすくする必要があります。その手法の1つにデータとデータのつながりに着目する方法があります。図2は企業間取引の大規模データを利用して、企業間の関係をグラフにしたものです。点は企業、線は取引を表します。左はデータをそのままプロットしたもの、右は最近発表したアルゴリズムによってデータを研磨した結果です。取引関係がわかりやすくなったと思います。これはSNSの「共通の友達」を探すのにも応用できます。仮に100万個のデータをすべて解析するなら約1兆回のデータ比較をしなければなりませんが、このアルゴリズムなら多くて1,000回程度で済む。スーパーコンピュータを使わなくても、普通のパソコンでできてしまうのがアルゴリズム研究の面白さです。
有村 現在の一般的なデータ分析は、仮説を立ててそれを検証する手法が主流です。しかしビッグデータを相手にするには限界がある。データの中にひそむ数理を、人間がわかる形でデータそのものに語らせたい。アルゴリズム研究や機械学習の精度向上などを推し進めることで、その夢がかなうものと考えています。
(取材・文=土肥正弘)