Mar. 2024No.102

Interview
歴史ビッグデータで日本を読み解く
日本列島に残された、数億点とも言われる古文書群。それらの記録は貴重な文化遺産であり、過去を知るための情報源で もある。しかし、現代の私たちにはなじみが薄い存在だ。そこで情報学とデジタル技術を組み合わせることで、これらを身近なものに変えようとする取り組みが、北本朝展 教授によって進められている。近世のくずし字解読に生かされた AI 認識、歴史ビッグデータの構築、さらにそれらの先に見えてくる人文学研究の DX(デジタル変革)とは、どのようなものなのか。北本教授に聞いた。

北本 朝展KITAMOTO, Asanobu
国立情報学研究所 コンテンツ科学研究系 教授
ROIS-DS 人文学オープンデータ共同利用センター長

聞き手宮代 栄一氏MIYASHIRO, Eiichi
朝日新聞 編集委員
明治大学大学院博士課程修了(博士・史学)。1989年、朝日新聞社に入社。以後、専門記者として、歴史・考古学・古美術・文化財の収蔵・活用などに関する記事を主に執筆している。共著に『空白の日本古代史』(宝島社新書)ほか。
人文学の研究を変えるデジタル技術の活用
──北本先生が研究している人文学におけるデジタル技術の活用とはどういうものでしょう。
私自身は入力・処理・出力という3つの局面に分けて考えています。まず、入力ですが、これまで紙の本だけが研究対象だったものが、撮影したりスキャンしたりすることで、資料をデジタルデータとして使うことができるようになります。処理に関しては、そうしたデジタル化された画像のくずし字などをAIで読むだけではなく、巨大な量のデータを一望して分析することで、大きなメリットが生じると思います。一方、これらの研究成果などを、電子ジャーナルや、データの集合体であるデータセットなどの形で公開するのが、出力です。データを改めてデジタル入力することなく、そのまま利用できるという利点は大きいと思います。
このように、人文学に関わる3局面全てでデジタル化が進めば、研究もバージョンアップし、将来的には歴史研究のやり方自体も変わってくると思っています。
──研究が変わるとは?
例えば、以前は、古典籍 (こてんせき)や歴史資料は図書館や専門の収蔵施設に行って閲覧するのがスタンダードでした。しかし、コロナ禍で図書館に行けない時期が長く続いた結果、ウェブで見ることが普通になってきたように思います。
また、人文学のDX化に関するものとして、AIを利用した「くずし字認識サービス」があります。2018年に研究を開始した当初はその利用に懐疑的だった人も、現在は「これはこれで便利だし、受け入れられる」と思うようになってきています。AIと人間は優劣を競うものでも、対立するものでもなく、使い方次第で人の作業を補うものだということが理解されてきたように思います。
人文学研究を後押しする「AIくずし字認識サービス」
── 「くずし字データセット」と「くずし字認識サービス」とはどのようなものですか。
日本に残されている古典籍や古文書の総点数は数億点とも言われていますが、一方で、近世のくずし字を読める人は数千人と、全人口の0.01%に過ぎません。
そこで国文学研究資料館(国文研)と、私がセンター長を務める人文学オープンデータ共同利用センター(CODH)が 協力して、2016年から提供を始めたのが、「日本古典籍くずし字データセット」です。4千を超す文字種と100万を超えるくずし字の字形を集めて、データセットとして提供しています。そしてこのデータセットを学習したAIを用いたのが、「AIくずし字認識サービス」で、無料で公開しています。このサービスでは、顔検出や自動運転ですでに使われている物体検出技術を応用して文字を認識しています。古典籍の画像を読み込むと、1ページあたり約1秒、条件が良ければ95%以上の精度で、くずし字を現代の活字に変換してくれます。

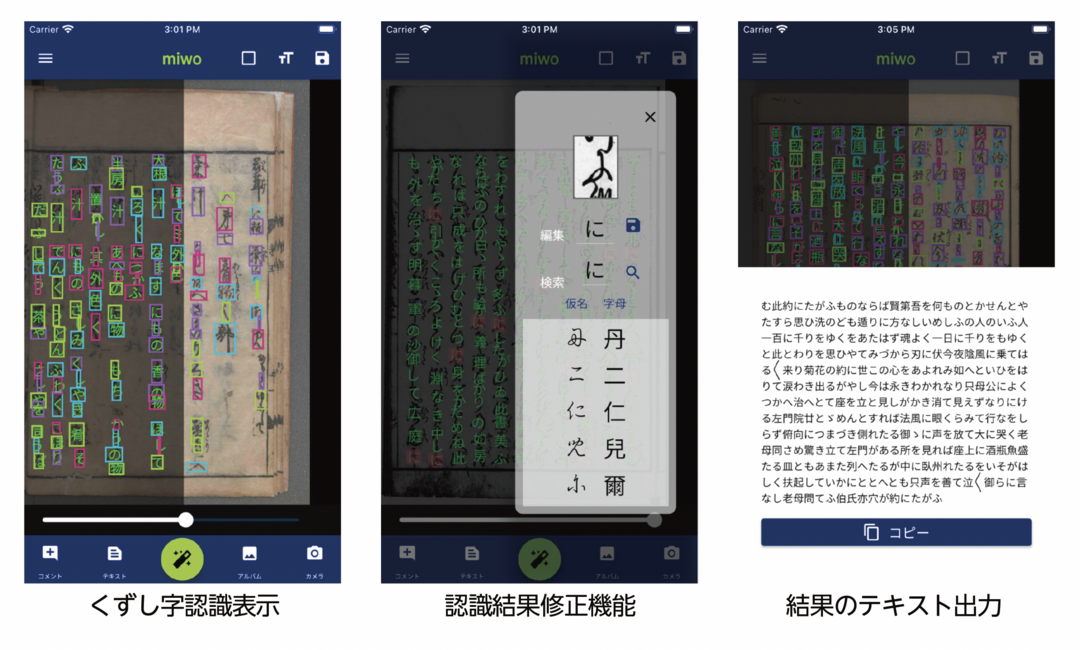
──スマートフォンのアプリも開発されたそうですね。
2021年8月に、AIくずし字認識アプリ「みを(miwo)」をiOS版とAndroid版で無料公開しました。名前の「みを」は「源氏物語」14帖の巻名である「みをつくし」(船の水路を示す杭のこと)から、くずし字を読む人々の道標になることを願って付けました。これまでに15万回以上ダウンロードされ、200万件以上の画像に対してくずし字認識が行われています。
AIくずし字認識サービスを作った当時は、スマートフォン・アプリまでは考えていなかったのですが、外出先で古文書を目の前にしたら、その場ですぐに使いたい、といった要望が多かったため、開発に至りました。ユーザーは研究者にとどまらず、古書店の方や、学生さんにも広がっています。現在も1日2千から4千件ほど、コンスタントに使われています。
「みを(miwo)」の最大のメリットは、誰でも、簡単にくずし字が読めることです。それによって、利用者と古典籍の距離が縮まります。
──逆に、現代文をくずし字に変換するサービスも提供されているのですね。
はい。「そあん(soan)」と名付け、2023年8月から公開しています。アイデア自体は昔からあり、実際に国文研が「くずし字、いろいろ」というサービスを作り、今も公開していますが、一般的なくずし字画像をコラージュしているので、文字の大きさの単位がそろわないという課題がありました。一方、私が分析に関わっている古活字版(こかつじばん)の活字画像を使えば、文字の大きさを揃えることができることに気づきました。そこで、日本の出版史上最も美しい書物の1つと言われる「嵯峨本」の古活字を素材に開発しました。
──現代文をくずし字に変換するメリットはなんですか。
文字には、自分で使うことによって覚えていくという側面があると思います。そうは言っても、今の私たちがくずし字を使おうと思っても、筆を使って一文字ずつ書きでもしない限り、使って覚えるのは難しいのではないでしょうか。しかし、このサービスを使えば、誰でも簡単にくずし字で文章を書けます。今まで、くずし字の学習が難しいとされてきた理由は、現代人にとって、それが内容も背景となる文化も分からない文字の羅列だったからです。でも「そあん(soan)」を使えば、内容も背景も分かるくずし字文を作成することができます。
また、「そあん(soan)」をLINEで使えるようにできないかという話もあります。くずし字を使ったコミュニケーションによって、人文学がより身近な存在になるかもしれません。
──くずし字認識での今後の課題はなんですか。
くずし字の現代文字への変換からさらに踏み込んで、現代の日本語へ自動翻訳することです。Chat GPTなどを使って、古文を入力すると、それが現代文になるかどうかを試行しているのですが、できる場合とできない場合があります。
漢字中心の文章よりもひらがな中心の文章の方が、ChatGPTによる翻訳は難しいようです。句読点もなく、現代の文章と大きく 違うため、ChatGPTが文章の流れを読み取ることができないのです。漢字混じりの文に書き換えて入力すると、結構読めるようになるのですが、それには人手が足りないというのが現状です。
歴史ビッグデータで隠れた史実を発掘する
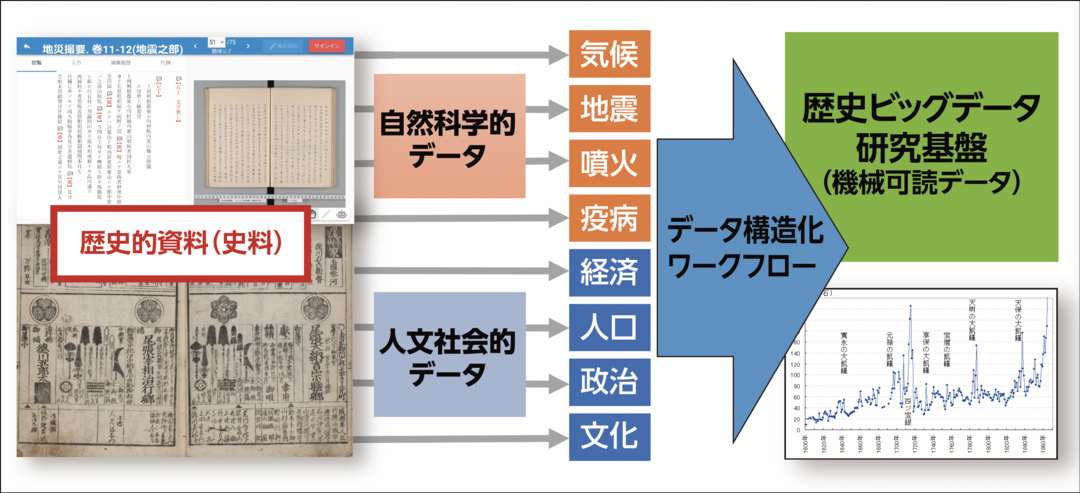
──現在進めている、歴史ビッグデータの構築作業とはどんなものなのでしょうか。
文部科学省の科学研究費を使ったプロジェクトとして、近世の歴史地震や武鑑に関する記録を中心に進めています。具体的には、近 世の日記や瓦版、大きな地震について記された本などを対象に、読み解きと入力を行っています。江戸後期の安政の大地震などだと、関連の記録がかなり残っているので、記録の内容と江戸の古地図などを対応させることで、地震後、どこから火災が発生し、人々がどう避難したのかを把握できるのです。
江戸時代の大名や幕府役人の名前や石高(こくだか)などを記した年鑑にあたる「武鑑」の読み解きもしています。国文研には、全頁がデジタルデータ化された武鑑が380点あるのですが、中には発行年が書かれておらず、年代がはっきりしないものも少なくありません。そこで、内容や版木の改変などを見比べながら、時系列に年代を推定する作業をしています。
このほか、武鑑に記された人名ごとにその記録の変化を集積することで、ある人がいつ頃、どんな役職を経て出世していったのかを追いかけることなども可能です。
──人文学のDX化が目指すものはなんですか。
デジタル技術を使わないと分からなかったような、新たな歴史的事実を明らかにすることです。今は基礎となるデータを構築している段階ですが、資料の総体が大規模化することで、初めて見えてくるものがあると思うのです。
巨大なデータ群であるビッグデータには Volume(量)に加え、Velocity(速度)、Variety(多様性・組み合わせ)、Veracity(正確性)の4Vが求められます。このうち、歴史ビッグデータで重要なのは、Variety(バラエティ)だと私は考えます。
社会現象というのは、さまざまな局面でつながっているものです。例えば、冷夏になると米が不足し、米の値段が上がった結果、飢饉や暴動が起きて、政情が不安定になるなどとも言われます。しかし、これらが本当にこの順で起きていたのかは実際分かりません。ビッグデータを構築し、1点1点資料を積み上げ、突き合わせていくことで、詳細で正確な状況が見えてくると思うのです。
科学の理論的な枠組みは、実験→理論→計算と変化してきたと言われており、これらは第1の科学、第2の科学、第3の科学と呼ばれています。そして、これらに続く、機械学習などを用いて大量のデータを駆使する科学が「第4の科学」です。
私たちの祖先が残した古典籍や歴史資料は元々、人間が読むために生まれたものですが、今後は人間と共にコンピュータもそれらを読み、人間には難しい部分を機械が支援して、助け合う時代がやってくるでしょう。
日本には、世界的にも稀有とされる、数億点もの古典籍や歴史資料が残されています。先人たちがせっかく残してくれた貴重な財産を、ただ埋もれさせるのではなく、しっかり活用していくためにも、歴史ビッグデータの構築と分析は必要なことだと考えます。
聞き手からのひとこと
記者は7年前、国文研の研究者らが読み解いた、江戸の料理本のレシピに基づく卵料理や豆腐料理が都内の百貨店で市販される、という記事を書いたことがある。今回、その際に使われたのが、北本教授が立ち上げに関わった、江戸の料理文化を現代に生かすための「江戸料理レシピデータセット」であることを知り、驚いた。今後、歴史学の本格的な DX化が進めば、近世のみならず、あらゆる時代の歴史像は大きく変容していく可能性がある。歴史研究者による活用を期待したい。(宮代栄一)
Photo 杉崎 恭一