Sep. 2019No.85
Interview
世界の研究者とチームを組んで 増え続けるフェイク情報と闘う
攻撃に備え、先回りして研究開発
フェイク(虚偽)と総称される、悪意を持って加工された画像や音声、投稿がインターネット上で増え続けている。誤った判断や情報セキュリティの無効化、プライバシー侵害につながることもあり、社会の脅威である。
国立情報学研究所の越前 功教授、山岸順一教授、ワン シン特任助教、房 福明特任研究員らは、攻撃者に先んじて攻撃方法を推測し、機械学習などを駆使しながら防御策を見いだしている。
世界の研究者と連携し、必要なデータを持ち寄るなどして難問に挑む。

越前 功Isao Echizen
国立情報学研究所 所長代行/副所長/情報社会相関研究系 教授/総合研究大学院大学 複合科学研究科 教授

山岸順一Junichi Yamagishi
国立情報学研究所 コンテンツ科学研究系 教授/総合研究大学院大学 複合科学研究科 教授

ワン シンWang Xin
国立情報学研究所 コンテンツ科学研究系 特任助教

房 福明Fang Fuming
国立情報学研究所 情報社会相関研究系 特任研究員
聞き手谷島宣之Nobuyuki Yajima
日経BP社 日経BP総研 上席研究員
大学で数学を学び、コンピュータのエンジニアをめざしたが、1985年日経マグロウヒル社(現・日経BP社)に入社、『日経コンピュータ』誌の記者になる。2009年から『日経コンピュータ』編集長。2016年から現職。
分野の垣根を越え、チームで研究
─ なぜ、越前研と山岸研が共同でフェイク情報の問題に取り組んでいるのでしょうか。
越前 フェイク情報の対象は画像や音声、投稿されたテキストなど多岐にわたります。しかもこれらを複合させたフェイク情報も登場し始めています。ますます問題が難しくなってきていることもあって、画像系の私、音声系の山岸先生と組んで対策を考えているのです。もともと私は映画の盗撮防止技術など、ディスプレイやスクリーンに表示されるコンテンツの保護について研究してきましたが、近年は人間そのものを守るための研究にシフトしており、その中でフェイク情報の問題にぶつかったというわけです。
山岸 私は主に状況に合う音声をつくる「賢い音声合成」を研究してきましたが、音声合成の技術が進化するにつれ、やはりフェイクの問題を避けられなくなってきました。
特に力を入れているのが、人間の音声かコンピュータが合成した音声かを見分ける国際大会(コンペティション)で、世界の研究者に呼びかけて企画、実行しています。越前研から参加者を出してもらうなど、分野の垣根を越えて研究に臨んでいます。その理由は、対象がなんであれ、機械学習の発展により問題解決の手法がすべて、似通ってきているからです。音声だけ、画像だけを研究します、というのではなく、より広い視野を持って問題をとらえ、トータルで考えていかなければ新しい研究はできません。
ワン 私は山岸研で音声の研究に取り組み、フランスやアイルランド、フィンランドといった国の研究者と一緒にコンペティションを運営しています。大会以外にも欧州諸国の研究者といろいろな共同研究を進めています。
房 私は越前研に所属していますが、画像系にとどまらず、人物が話をしている動画に出てくる顔と音声を同時変換する技術とその悪用対策、個人の音声を匿名化してプライバシーを守る技術などを研究しています。音声の研究では高品質の音声合成が求められますが、そこにワンさんが考案した手法を使っています。
増え続ける脅威ごとに対策を講じる
─ 二つの研究室の連携にとどまらず、世界の研究者とともにチームワークで取り組むのはフェイク問題がそれだけ重大だからでしょうか?
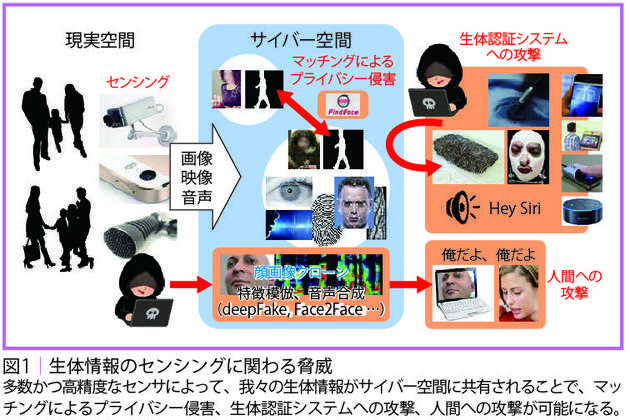
越前 「百聞は一見にしかず」という言葉があります。伝聞だけでなく、実際に目で見て確かめればわかる、ということですが、今や、目に見える情報がフェイクかもしれない。つまり、「一見」が怪しくなってしまった。誰かにそっくりの偽画像や偽音声が出回っており、それを見聞きしたことで間違った判断をしかねません。偽造された顔や指紋、音声によって生体認証を突破され、システム内に侵入される危険もあります(図1)。
スマートフォンは年間十数億台出荷されており、高精細カメ ラを多くの人が持ち歩き、撮影し、高品質な画像をすぐインターネットで公開できる。こうした状況がフェイク情報問題の背景にあります。さらに、顔識別機能を搭載したスマートフォンのアプリを使うことで、見知らぬ人を撮って身元を特定することも可能となっており、プライバシー侵害の問題も指摘されています。
山岸 音声合成については2017年、アルファ碁を開発したグーグルの子会社(ディープマインド)がつくった音声がチューリングテストに合格しました。「これはコンピュータがつくった音声だ」と人間が見破れない水準に技術が到達したことを意味します。マイクロソフトがつくったソフトも同じテストにパスしました。自分そっくりの声を悪意ある誰かが勝手に合成できるとしたら、どのような危険が生じるか、想像してみてください。
越前 研究者の任務として、先回りをして攻撃手法を考え、その脅威を示すことも必要だと考えます。もちろん防御の具体策も同時に用意します。
山岸 技術が進めば、画像生成によるエンターテインメントの充実や、病気で声を失った方が音声合成によって今まで通りの声を取り戻す、といったことができるようになります。だからこそ私たちは、危険があるからといって技術を開発しないのではなく、進化させつつ、悪用への防御策も備えましょう、という姿勢をとっているのです。
具体策①:動画の真贋を世界で初めて自動検出
─ 防御の具体策にはどのようなものがあるのでしょうか。
越前 機械学習を使って、動画の真贋を自動判別できるニューラルネットワークを、私たちは世界で初めて開発しました。[1] 動画をこのネットワークに読ませると本物(リアル)か偽物(フェイク)か、判定してくれます。
本物の動画と偽物の動画を集めて、これは本物、これは偽物と示してネットワークに学習させました。ネットワークは読み込んだ動画をいくつかのフレームに分け、フレームごとに特徴を抽出し、その結果をまとめて、加工の有無を示します。
圧縮されていない動画データの場合であれば、判定を間違う率を0.67 ~ 0.77%程度まで抑えられるようになりました。さらに研究を進め、複数ある動画加工の方式のうち、どの方式を採用し、動画のどの部分を変更したのか、例えば顔であるとか、口元であるとかといった情報を検出できるようにしました(図2)。
山岸 動画共有サービスを手掛ける企業がこの技術を使って公開動画の下に「この動画は加工されている」といった表示を出すようにすれば、誤った情報を信じてしまうリスクを減らせるのではないでしょうか。

具体策②:音声の真贋を見分ける国際大会を開催
─ 音声の真贋を見分ける国際大会とはどのようなものなのでしょうか。
山岸 音声の合成や解析の研究を続けるなかで、音声の真贋の自動識別については2010年から取り組んでいます。現在は、話者が人間、つまり生体かどうかを検知する仕組みを開発しています。研究分野として世界的に盛り上がってきたこともあり、ASVspoof Challenge[2]と呼ぶコンペティションを2015年から隔年で開催しています。2019年は154の企業や研究機関がチャレンジに参加し、49の組織が判別結果を提出しました。グーグル、NTT、HOYAといった企業、フィンランド、アイルランド、フランスなどの研究機関が参加してくれました。
チャレンジの特徴の一つはオープンデータアプローチをとっていること。私が過去に公開した音声データをもとに協力企業が加工したり合成したりして、さまざまな合成音声のデータを提供してくれました。自然音声と合成音声、計19種類のデータをチャレンジの参加者に渡し、参加者は自分の技術でデータを解析して真贋判定の結果を提出します。音声データの提供者は解析のチャレンジには参加しません。
機械学習に常につきまとう課題は高品質のデータを集めることです。フェイク対策のためには正しいデータに加えてフェイクデータも必要になります。企業の協力によって価値あるデータを参加者に渡すことができました。
チャレンジの結果は私の予想を超えるものでした。1位になったのは米国の情報セキュリティ企業で、誤り率はわずか0.2%。人間の耳では真贋がわからなくてもコンピュータにはわかるわけです。特徴的だったのは、彼らが複数の検出モデルを用意し、それらを組み合わせて真贋を見分けていた点です。フェイクが巧妙になってきているからこそ、さまざまな方式に備えて複数のモデルで対処する必要があるということでしょう。
具体策③:匿名化で「なりすまし攻撃」を防ぐ
─ 顔の動画や音声など生体情報の悪用防止策は?
越前 これまで、画像についてはいろいろな研究をしてきました。例えば、我々が開発したPrivacyVisor と呼ばれる特殊なメガネをかけると、顔写真を撮られても顔識別がうまく機能しないため、被撮影者のプライバシーを守ることができます。さらに、Vサインを掲げた写真からでも指紋データを読み取ることができるので、その防止策も考案しました。指をシートに押し付けるだけで盗撮を防止する特殊な画像パターンを指に転写する手法ですが、我々が常に使用する指紋認証には悪影響がない、というものです。
房 話者匿名化の手法も開発しました。音声データを公開する際、個人を特定できないように加工するというものです。ただし、加工しても人間には自然な音声に聴こえます。別人の声に変えたり「ピー」というノイズをかぶせたりするのは不自然ですので......。
具体的には、匿名化したい音声データを解析して特徴を見つけ出し、同様の特徴を持つ他者の音声データを探して平均をとるように音声を合成し直すのです。こうしてつくった音声データは聞き手に違和感を与えず、特徴を平均化しているので個人を特定できません。
具体策④:要の音声合成で革新「計算量を激減させる」
山岸 匿名化にしても、解析のチャレンジ用のデータをつくるにしても、高品質な音声合成ができるかどうかがカギを握ります。フェイク情報対策に限らず、あらゆる音声研究の基本になる合成技術で、ワンさんは「ニューラル・ソースフィルター・モデル(NSF)[3] [4]」と呼ぶ手法を開発しました(図3)。
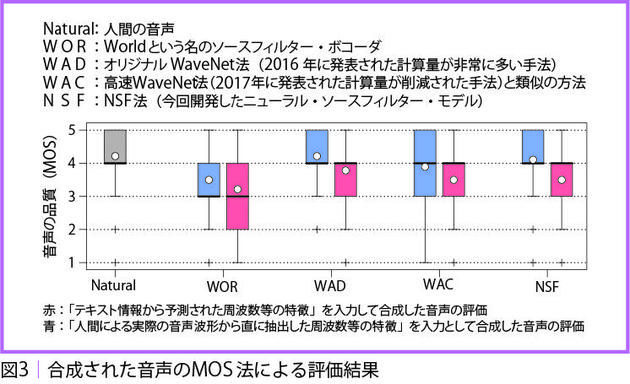
ワン 機械学習を使って、人の音声波形を合成する新しいネットワークを開発しました。テキストから音声を合成するには、まずテキストを読み取り、必要な音の特徴を抽出し、そこから音声波形に変換するのですが、品質の高い音声をつくり出せる波形モデルの構築がこれまで難しかったのです。
私たちのモデルは声道の振る舞いを複数のニューラルネットワークで近似したものです。最初は声帯から出る風のような音をしているのですが、声道ネットワークを何回か通していくと高品質な音声になっていきます。
繰り返し計算するので計算量は増えますが、計算時間は既存の手法よりも大幅に短縮できました。1秒間の音声を合成するには、波形を構成する1万6000 点のデータを計算しなければなりません。その際、私たちの手法であれば並列処理が可能で、プロセッサーが100個あれば1個で160点ずつ計算することができます。
山岸 これまでグーグル子会社の音声合成手法が高品質とされてきたのですが、1万6000点を時系列にそって計算していくので時間が相当かかります。彼らの手法で1秒間に100点計算している間にワンさんのやり方なら200万点の計算が可能です。
─ グーグル子会社と真っ向勝負して新しいモデルとアルゴリズムを考案したわけですね。
山岸 そうです。ワンさんは機械学習の難しいアルゴリズムをとことん考えるのが好きなんですね。当初、考案したモデルはかなり複雑だったので、「ここをなくせば」と助言したのですが、彼は私の提案とは別の選択をしました。結局、それが正解でした。

次に狙われる情報を事前に守る
─ 今後はどのように研究を進めていくのでしょうか。
越前 未来に起こり得る脅威を先回りして見つけ、それを伝えることにも時間を使いつつ、防御策を引き続き研究していきます。画像、音声、文章、おそらく触覚も対象になるでしょう。これらを組み合わせ、ターゲットとなる相手の好みや思考に合わせて変換されたフェイク情報が登場したとき、その情報に悪意があることをどのように検知するか。新しい脅威のモデルを考える必要があります。
房 文章についてはフェイクレビューの研究を始めています。ショッピングサイトなどに利用者がレビューを書きますが、これを見て商品を選ぶ人も多いでしょう。ところが、悪意を持った組織が特定商品の評価を落とすレビューをコンピュータで大量発生させて投稿したとしたら、それは大きな問題になります。
そうした判定が可能かどうか、二つの機械学習ネットワークを組み合わせて検証しました。まず、本物の投稿を読み取らせ、ネガティブな内容であった場合、「その続きはどうなるか」 と予測させる。この予測結果を別のネットワークに入れ、ネガティブになっているかどうかを判定させる。こうすると、言い回しを変えたネガティブな文章を次々につくることができます。
本物のレビュー1件と偽物3件を読んでもらい、リアルな投稿がどれかと尋ねたところ、人間の正解率は20~30%にとどまりました。当てずっぽうでも25%の確率ですから、人間にはレビューの真贋を見分けることは困難です。防御策は研究中ですが、例えば投稿の中身を見ずにコンピュータ生成されたものかどうかを見抜く手法を検討していく方法もあります。一方で、自然言語解析をして、投稿の中身をチェックする手法もある。いずれにせよ、文章の場合、映像などで見られる作為的な手掛かりが少なく、簡単ではありません。
ワン 前述したように、偽物の音声の問題はますます重要になっています。研究において対処すべきポイントは二つあると思います。一つ目は、偽の音声を検出する一般的なシステムの構築です。今年のASVspoof Challengeでは高品質の合成音声が高精度で検出できることを実証しましたが、合成音声を検出するためには、異なる構成を持つ複数のサブシステムをマージした検出システムが必要になります。単一のサブシステムを使用すると、検出精度が大幅に低下するためです。二つ目は、ASVspoof Challengeの主催者の一人として、新しい音声合成技術を含むデータベースを改善する必要があると思っています。
山岸 画像、音声、文章を含んだコンテンツの真贋を判定しようとすると、システムの公平性や説明可能性の議論とも重なってきます。普段使っているシステムがさまざまなことを推奨してくれますが、その裏で誰かがバイアスをかけていないのか、その点をどう説明するか、という話になりますから......。多くの人たちが議論すべきテーマだと思います。
(写真=佐藤祐介)
インタビュアーからのひとこと
画像や音声をコンピュータに生成させる研究には夢があり、本来、楽しいはずだ。だが残念ながらフェイク情報による攻撃方法と防御策を同時に考えなければならない。この難問に、越前・山岸チームは研究室も組織も国も越え、世界の研究者とともに取り組んでいる。
インタビューが一段落したとき、ワンさんと房さんに「NIIの研究環境はどうか」と聞いてみた。すると、越前さんと山岸さんは、教官がいては答えにくいだろうと気を利かせたのか、「所用が」と言って部屋から出て行った。このぐらい柔軟でないと垣根を越える研究はできないのかもしれない。
お二人の回答は次の通り。「世界の研究室とつながりがあるところがよい。2018年には留学もさせてもらった」(ワンさん)。「何よりやりたいことは研究。ここには研究に集中できる環境がある」(房さん)。
注釈
- [1] 機械学習により生成された巧妙なフェイク動画を自動検知する技術 - NII SEEDs
- [2] Automatic Speaker Verification Spoofing and Countermeasures Challenge
- [3] 自然な音声を高速に合成する新手法 ニューラル・ソースフィルター・モデル - NII SEEDs
- [4] NIIニュースリリース:自然な音声を高速に合成可能な新手法を開発~古典的手法にニューラルネットワークを導入したニューラル・ソースフィルター・モデル~