Sep. 2014No.65
Article
実用化へ走り出した音声認識
母国語のようなスムーズな会話の実現へ
現在、コンピュータ技術の進展や膨大な音声データの集積などに伴い、音声認識の実用化に向けた研究が加速している。一方で、本格的な実利用が始まり、期待が高まる中で、いくつかの課題も見えてきた。音声認識技術の進化の歴史と実用化に向けた取り組み、そして現状の課題について、音声認識研究の専門家である京都大学の河原達也教授と独立行政法人 情報通信研究機構(以下NICT) ユニバーサルコミュニケーション研究所 音声コミュニケーション研究室の堀智織室長に、NIIで音の信号処理等の研究を手掛ける小野順貴准教授が話を伺った。

聞き手小野順貴Nobutaka Ono
国立情報学研究所 情報学プリンシプル研究系 准教授総合研究大学院大学 複合科学研究科情報学専攻 准教授

河原達也Tatsuya Kawahara
京都大学 学術情報メディアセンター/情報学研究科教授

堀 智織Chiori Hori
独立行政法人 情報通信研究機構 (NICT)ユニバーサルコミュニケーション研究所音声コミュニケーション研究室 室長
クラウド化により進化する音声認識技術
小野 まずは音声認識技術の歴史からお聞かせください。
河原 研究が開始されたのは、今から50年以上前に遡ります。海外ではベル研究所などいくつかの機関で研究が行われていましたが、日本でも先駆的に取り組まれており、1962年に京都大学が「音声タイプライター」を開発しました。これは、「あ・お・い」といった単音節を認識するものでした。その後、現代の音声認識システムの元となる技術ができたのが1990年頃です。それは、スペクトル包絡※を表現する特徴量と統計的分布の状態遷移モデル(HMM:Hidden Markov Model、隠れマルコフモデル)に基づくもので、以降約20年が経過しましたが、音声認識の基本的な枠組みはほとんど変わっていません。
スペクトル包絡:音声の特徴量の中でもっとも重要な、スペクトルのなだらかな変動。
小野 音声認識の具体的なしくみについてご説明いただけますでしょうか。
河原 音声認識に必要な主な要素は、音響モデルと単語辞書・言語モデルです(図1)。音響モデルは日本語の各音素の周波数パターンを記憶したもの、言語モデルは日本語の単語の典型的な並びを記憶したものです。
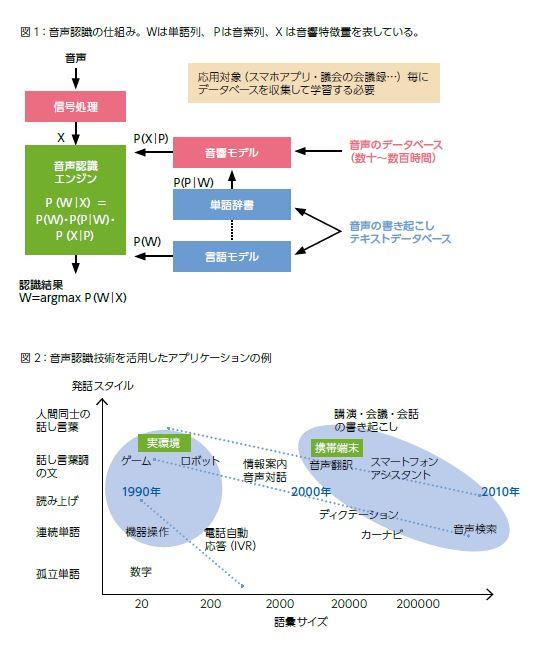
堀 このように音声認識は複数の技術を組み合わせ、音声を文字データとして抽出します。例えば、音の並びを単語に置き換える際に単語の辞書だけでは十分な推定ができないため、音の並びから単語の候補を出し、さらに言語モデルに基づき単語列のもっともらしさも考慮して、確率的にもっとも正しいと推定される候補を選択するといった具合です。
小野 そうした中で、近年、技術的なブレイクスルーがあったわけですね。
河原 ええ、音響モデルなどの統計モデルの洗練や学習データの大規模化、そして計算機の処理能力の大幅な向上です。コンピュータの小型化、高性能化に続いて、現在ではスマートフォンなど携帯端末も高性能化しています。その一方で、ネットワークが高速化したことで、クラウドサーバ型のシステムが実現されました。こうした超大規模なサーバ、およびデータの活用により、現在の音声認識は端末側ではなく、バックグラウンドのサーバ側で行われ、これまでになかったような高精度な処理が実現されつつあります。
堀 ビッグデータは1つのキーワードとなっています。実世界で利用できる音声認識の実現にあたって、大規模な語彙を格納したデータベースが不可欠ですが、現在ではWeb上にテキストや音声の膨大なデータが存在しています。そうした新たな大規模な情報を利用しつつ、世界中の動画や音声に対して字幕化や検索のためのインデックス化、さらに翻訳する技術が各研究機関や組織で研究開発されています。
さまざまな場面での応用が進む
小野 進化を続ける音声認識技術ですが、現在、どこまで応用が進んでいるのでしょうか。
河原 主要なアプリケーションとして、機械に発話することで何らかの作業を行わせる「音声インタフェース」と、人間同士の自然な会話を認識し、自動的に記録や字幕を作るといった「音声をコンテンツとして扱うもの」の2つに大別されます。前者では、10年ほど前から音声タイプ/音声入力ワープロなど、パソコンのディクテーションソフトや、カーナビなど音声によるコマンド入力で実用化されてきました。また、電話や携帯電話による予約、問い合わせといった音声による情報アクセスでも活用されています。近年では、クラウドサーバによる音声認識の性能向上、およびスマートフォンの高性能化と普及に伴い、携帯端末における音声入力のニーズがより高まりつつあります(図2)。一方、後者の「音声コンテンツ」では、テレビ放送の字幕付与や議会の会議録作成などにおいて有効活用されています。
堀 私が所属するNICT 音声コミュニケーション研究室では、主に2つの研究を進めています。1つが、人間と人間、人間と機械の簡便なコミュニケーションを実現するための音声インタフェースの研究、もう1つがWEB上の音声データに対して字幕付与、検索のための自動インデキシング技術の研究があります。前者の研究では、音声翻訳技術を用いて母語の異なるユーザー間のコミュニケーションを実現する音声翻訳システムの開発や、音声認識や合成技術を用いて聴覚障碍者の方と健常者の方のコミュニケーションを支援するシステムの開発を進めています。後者の研究では、多言語のニュース音声を認識して日本語に翻訳する、自動インデキシングを行うことで検索語に基づき音声を検索する、音声以外の音響イベントを抽出する、などの研究開発を進めております。
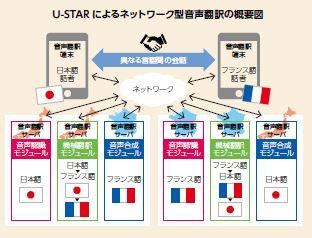
NICTで行っている多言語音声言語処理の研究を日本だけで実現するのは難しいことから、世界23カ国28研究機関が参加する研究共同体「U-STAR(Uni- versal Speech Translation Advanced Research:ユニバーサル音声翻訳先端研究)コンソーシアム」により、世界規模の音声翻訳研究ネットワークの実現、そして音声認識を活用した多言語でのコミュニケーションの実用化を目指しています。
話し言葉を認識することの難しさ
小野 さらなる実用化に向けた課題には、どのようなものがあるのでしょうか。
河原 現在の多くの音声認識システムは、機械を意識して事前に内容を考え、簡単な文章を丁寧・明瞭に発声することを想定したものがほとんどです。そうしたケースであれば認識率も90%には達していますが、人間同士の会話に目を向けた場合はどうでしょうか。講演や議会のように公共の場で話す状況、それもスタジオやヘッドセットマイクなどで収録したものについては、かなり高い精度で音声を認識できるようになっているものの、家の中や街中での雑音が多い環境での会話や、日常会話のように発話のバリエーションが多様なものは、まだまだ精度を高めることが困難です。
堀 母国語の人間同士が行っているコミュニケーションのように、考えながら話したり、発声が明瞭でなくとも認識できるようにすることが課題となっています。
河原 実際に今の音声認識技術は、人間の言語処理とは異なり、意味を理解しているわけではありません。また、音声認識は先述したように、モデルを構築していくためのデータの収集が鍵となります。しかし、会話のデータはバリエーションが数多く存在しており、単にそれらを数多く収集して蓄積すれば、解決するかというとそれほど単純ではありません。多様なデータを的確に扱える技術を実現してくことが当面の課題の1つでしょう。
堀 一方で、いかに少ない学習データで大量の学習データと同等の性能を実現していくかが問題となるので、少資源で高精度化できる技術を創出してくことも重要です。また、これまではコンピュータの性能の制約から表層的な部分だけを扱わざるを得ませんでしたが、現在では大規模コンピュータによる膨大な計算が可能になってきているので、膨大な情報を取り込んでより高精度なモデルを学習することも不可欠です。
河原 音声認識を母国語での会話レベルにまで高めていくためには、今よりもう1段も2段も進化させていかなければなりません。そのためにも、統計的な学習理論をさらに追究していくことが必要です。ルにまで高めていくためには、今よりもう1段も2段も進化させていかなければなりません。そのためにも、統計的な学習理論をさらに追究していくことが必要です。
(取材・文=伊藤秀樹)
国会会議録で活躍する音声認識技術
河原達也先生の研究
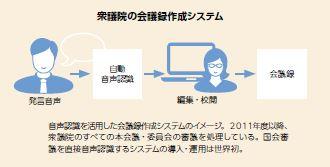
議会では長らく手書きの速記によって会議録が作成されてきた。しかし、速記者の新規養成の廃止に伴い、2011年に衆議院では、河原達也教授らの音声認識技術を用いたシステムを導入。同システムにより、すべての本会議・委員会の審議で、発言者のマイクから収録される音声に対して音声認識が行われ、会議録の草稿が生成されている。国会の審議音声を直接認識するシステムは、世界でも初めての事例だ。そのしくみについて、河原教授は以下のように語る。
「まず衆議院の審議音声と忠実な書き起こし(実際の発言内容)からなるデータベース(=コーパス)を構築しました。会議録の文章との違いを統計的に分析、モデル化した結果、「えー」や「ですね」といった冗長語の削除を中心として、約13%の単語で違いが見られました。この統計モデルに基づいて、過去10年以上分、約2億単語にもおよぶ大量の会議録テキストから、実際の発言内容を予測する言語モデルを構築しました」
さらに、この言語モデルと音声を照合することで、約500時間分の審議音声から音響モデルを構築。これらのモデルは半自動的に追加学習や更新を可能とするもので、今後の総選挙や内閣改造に際しても話者集合の変化を反映し、持続的に性能を改善できるという。本格導入に先駆け2010年の試験導入で性能評価を行ったところ、会議録と照合した音声認識結果の文字正解率は89%に到達。この音声認識結果を速記者が専用エディタで修正・編集することで会議録原稿を作成するシステムの有用性が検証され、本格的なシステム運用が開始された。
「2011年に行われた118会議で評価したところ、平均文字正解率は89.8%となり85%を下回る会議はほとんどありませんでした。本会議に限れば、ほぼ95%にも達しています。しかし満足はしていません。もう一段性能を上げることで、その他の応用にもつなげてきたいと考えています」(河原教授)
言葉の壁を打ち破る音声翻訳アプリの開発
堀 智織先生の研究
小野 現在、NICTでは、世界23か国、28の研究機関と連携した究開発を進められています。そして2012年に、U-STARでは、世界人口の約95%をカバーする「多言語音声翻訳システム」が開発されましたね。堀室長はその開発を手掛けていらっしゃいますが、取り組みについてお聞かせください。
堀 U-STARでは、各国の研究機関との連携により、現在、音声入力17言語、テキスト入力27言語、音声出力14言語に対応した多言語音声翻訳システムを開発しており、本システムは2010年にNICTが国際標準化(ITU-T勧告書F.745およびH.625に準拠)した技術を採用しています。NICTが運用するコントロールサーバと、加盟する各研究機関がそれぞれ運用する音声認識、機械翻訳、音声合成のサーバをネットワーク型音声翻訳通信プロトコルで相互接続するとともに、利用者にはクライアントアプリケーションを介して、多言語の音声翻訳サービスを提供するというものです。
小野 一般の人も利用できるのですか?
堀 ええ、実証実験を行うためにiPhone向けの音声翻訳アプリケーション「VoiceTra4U」が一般公開されています。VoiceTra4Uは、発話された音声を認識し、簡単な操作で会話内容を翻訳するというものです。対応言語は、アジア、ヨーロッパの30種類以上をカバーしています。また、1台で音声翻訳し、翻訳結果を確認できるだけでなく、最大5台の端末を接続し、リアルタイムで会話ができる「チャットモード」も搭載しています。話した内容が、話し相手のそれぞれの言語に翻訳される、というわけです。
小野 これは使えますね。今後の展開をお聞かせください。
堀 VoiceTra4Uは言語だけではなく、視覚障碍を持った方との音声による会話や、聴覚障碍を持った方とのテキストによる会話も可能です。言語の壁だけでなく、コミュニケーションモダリティの壁も越えることも目指しています。