Sep. 2014No.65
Article
応用領域が急拡大する「統計的音声合成」技術
統計的手法「HMM」による自然な音声合成術とは?
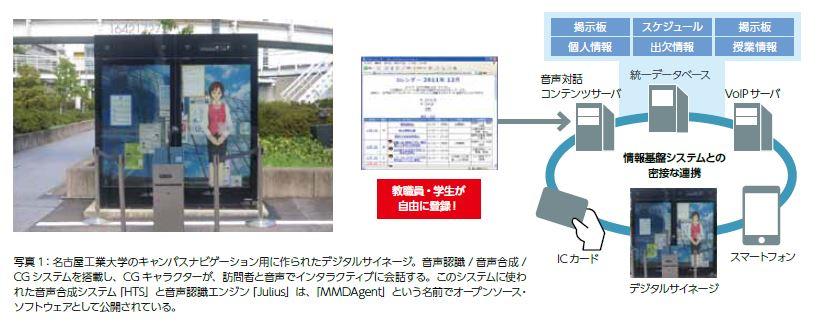
いま、音声合成技術は、かつての「宇宙人の声」のような不自然なものから、普通の人間の発話と見分けがつかない高品質なものへと進化している。その背後には、統計的な手法を使った音声合成技術の進歩がある。従来よりも学習データ量、計算データ量ともに劇的に軽減したこともあり、デジタルサイネージやロボット、障碍者支援、携帯デバイスナビゲーションなど、応用領域を急速に広げつつあるのだ。発語機能を失った人の元の声の再現、オリジナル話者の声を使った翻訳の読み上げなど、音声合成研究の最前線について、世界のトップを走る3人の研究者に聞いた。

山岸順一Junichi Yamagishi
国立情報学研究所 コンテンツ科学研究系 准教授 / 総合研究大学院大学 複合科学研究科 情報学専攻 准教授

徳田恵一Keiichi Tokuda
国立情報学研究所 客員教授名古屋工業大学 大学院工学研究科 教授

戸田智基Tomoki Toda
国立情報学研究所 客員准教授 / 奈良先端科学技術大学院大学情報科学研究科 准教授
音声合成技術を劇的に変えた「統計的方法」とは?
徳田 音声合成は1950年代から取り組まれてきましたが、現在につながる音声合成は1970年代から発展しました。この頃は、ある音のあとに次の音がつながるときにどのようなルールがあるのかを調べ、そのルールを音声合成に利用する方法でした。
山岸 人間は肺からの空気で声帯をふるわせて出る音を、口腔や鼻腔で共振させて発声します。舌や口の形で共振周波数を調整し、音色を加えて声にしています。昔の音声合成は、声帯から出てくる音がどう変化するか、共振周波数の変化ルールを導きだし、テキストに応じてルールをベースに音源に変調をかけるやり方で音声を合成していました。その音声は、古いSF映画に出てくる「コンピュータの声」や「宇宙人の声」のような、独特の響きを持っていました。
徳田 中には非常によい結果を出した研究もありましたが、ルール作りには研究者の個性が出てしまいます。また1人の声のルールは作れても、例えば男・女・若年・壮年などといったさまざまな属性の人のルールを作ろうとすると何十年もかかってしまうので、柔軟性に乏しいという欠点がありました。
そんな状況を変えたのが、この頃から急速に発展したコンピュータ技術です。従来よりも大量のデータを高速に処理できるようになったことから、大量の音声を録音し、「コーパス」と呼ばれるデータベースにして、そこから音声を拾って、いわば切り貼りするようにして自然な音声を合成できるようになりました(波形接続型音声合成)。こうすると、単音節以外にも単語や文節など、ある程度連続した音声のつながりを利用できるので、ずっと自然な合成音声になります(単位選択合成)。
このコーパスベースの音声合成は、1980年代にはコールセンターなどの電話自動応答システムやパソコンのテキスト読み上げソフトに応用され始め、90年代には利用が広がって一大ブームとなりました。この頃の技術は現在も広く利用されています。いまネットで人気のボーカロイドの音声合成技術も80年代の音声合成技術をベースにしたものです。
山岸 しかしこの方式は、例えば数十~数百時間におよぶ音声データの収録を必要とし、大規模なデータベースを使わなければなりません。徳田先生と戸田先生、そして私は同じ研究機関で協働して100時間の音声収録を行いましたが、1年もの期間がかかりました。人間の声は体調によりさまざまに変化するので、利用できる音声を収録するのに10倍くらいの時間が必要になるからです。
徳田 より自然な音声にしようとすると、膨大な音声データが必要になり、インデックスづけなどの後処理も大変です。例えば「ドラえもん」や、人工知能と人間が恋をする映画「her/世界でひとつの彼女」のように、自然に会話ができるような機械を想定すると、無限の多様性を持つ音声合成が必要になり、データ収録も無限に必要になってしまいます。また、データベースサイズが大きくなると、携帯端末のような記憶容量も性能も低い端末での利用は難しくなります。
そこで、もっと柔軟で効率のよい音声合成の方法はないかと研究した結果、私たちが見出したのが「HMM(hidden markov model:隠れマルコフモデル)」という統計学の確率モデルでした。
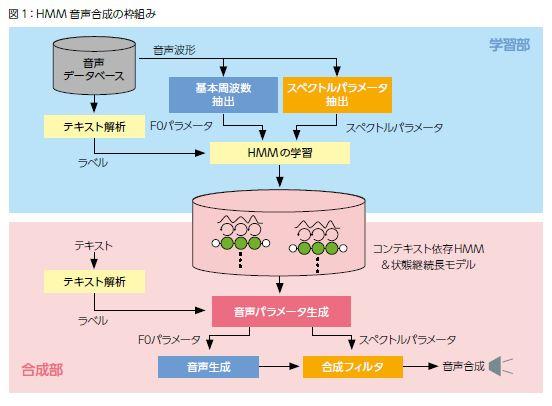
HMMによる音声合成の仕組みと3つの利点
戸田 HMMによる音声合成は、コーパスに蓄積されたテキストと音声波形の対応関係を、関数としてコンピュータに学習させるところから始まります。これは音声認識で成果を挙げた手法で、抽象化された関数を利用することで、音声波形に揺らぎがあっても、その背後に潜んでいる特性を見出すことができます。例えば同じ「おはよう」という言葉でも、発声するたびに違った波形になるものですが、統計的な手法によれば共通のパターンが計算によって割り出され、テキストとの対応はどれも同じ「おはよう」になるのです。徳田先生が、世界で初めてHMMから直接音声を合成する技術を開発されました。
徳田 HMMには95年から取り組んでいます。仕組みを簡単に言えば、まず学習データから音声信号の基本周波数(声の強さや抑揚にあたるもの)とスペクトル※1(声道での共振にあたるもの)を抽出し、テキストとの対応をHMMによりモデル化(関数化)してモデルとします。読み上げるテキストを解析した結果をこのデータベースに照合して、統計的に最も正解に近い基本周波数パラメータで音源を生成し、同様に生成したスペクトルパラメータによって音色を合成するという方法です(図1参照)。
これには次の3つの利点があります。
※1 スペクトル
音に含まれる周波数成分を波長の順に並べた強度分布のこと。
●省メモリでモバイルデバイスにも音声合成システムが搭載可能に
●言語依存性がなく、多言語適用が容易。歌声合成にも利用可能
言語依存性がほとんどないので、ある言語で開発した音声合成ソフトはほとんどそのまま他の言語でも利用できます。現在40カ国語以上の言語に適用されています。
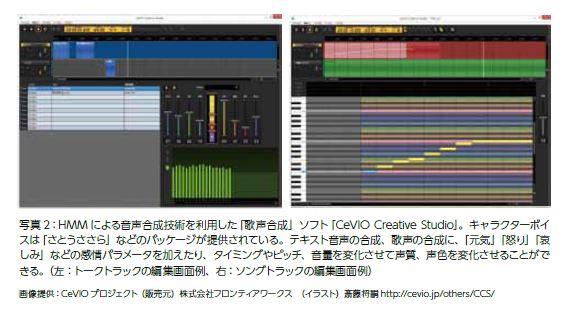
この柔軟性は、「音声」を「歌声」に、「テキスト」を「歌詞付き楽譜」に置き換えれば、同じ仕組みで歌声合成も可能にします。Aさんがいくつかの曲を歌って機械に学習させると、それらとは別の曲の歌詞付き楽譜を機械に入力するだけで、機械がAさんの歌声で歌ってくれます。また、自分の声によるボーカルアシストも可能です。この技術は「CeVIO Creative Studio」というフリー/有償ソフトとして一般向けに提供されています(写真2)。
●パラメータ調整で音声を「真似る」「混ぜる」「作り出す」ことが可能
パラメータの調整だけでいろいろな声が作り出せることも特長です。感情表現をつけたり、別の人の声を真似たり、複数の人の声を混ぜ合わせたり、実際にはない音声を作り出したりすることができます。
障碍者支援に貢献する音声合成
戸田 いろいろな声をパラメータ変更だけで作り出せる技術には、エンターティンメント以外に医療・福祉分野で大きな期待が寄せられています。ここまでのお話はテキストを機械で読みあげることが前提ですが、類似した技術によれば、例えばAさんの話をマイクで拾い、リアルタイムでBさんの声に変換してスピーカーから流すことができます。これを応用すれば、外国の方が発声した外国語を日本語の話者の音声に変換して、その話者自身の声色で出力することもできるわけです。また、同様にして、そのままでは聴き取りにくい音声を自然で明瞭な音声に変換することができるようにもなります。
例えば、喉頭がんなどで声帯を切除した人は、食道の入口をうまく振動させて発声する「食道発声」や電気式人工喉頭とよばれる補助器具を用いた発声を練習することが多いのですが、これは通常の音声と比べるとはかなり不自然で聴き取りにくいものとなってしまいます。その際、健康なときのその人の声のサンプルがあれば、音声変換装置を通して元のその人自身の声に近い自然な話し方に変換できるというわけです。
山岸 サンプル音声が少なくても、統計的な音声合成技術を使えば、かなり自然にその人の声に似せられるところがポイントですね。10分程度の録音データがあれば、その人の声による音声合成が可能です。また複数の人の声から「平均声」を作成することも簡単です。
これは構音障碍者の支援に大きな役割を果たします。筋萎縮性側索硬化症(ALS)など構音障碍が急速に進行する病気の人は、自分の声で意思伝達できなくなっていくことに苦しみ、周囲の人も話が聴き取れないことに悩むことが多いのです。そこで元気な頃の音声録音データを用いて音声合成を行う会話支援器を利用すると、聞き取りにくくなっていく一方の音声を明瞭な音声に補正して出力することができます。録音データは数分程度で大丈夫です。
あるスコットランドのALS患者の場合は、近隣の20名の方々が協力して音声を録音し、その平均パラメータにより本人の発音に近い違和感のない音声を合成することに成功しました。方言が強い地方だけに、一般的な平均声では満足できなかったのですが、この方法だとこれまで自分が話してきた方言混じりの話し方が再現でき、アイデンティティが取り戻せたと喜んでいました。
誰もが、できるだけ自分の声で話したいのです。音声合成技術を用いた会話支援器は低コストで入手できるようになりますが、それを障碍者1人ひとりが生かして使うには、できるだけ広い範囲で、たくさんの人の音声データの集積をしておくことが肝心です。世界で音声データを収集して利用可能にする「ボイスバンク」プロジェクトが行われており、日本ではNIIで「日本語ボイスバンクプロジェクト」を推進しています。※2
明瞭性は「人間以上」音声合成が拓く未来
徳田 戸田先生は音声入力ができる人向けの支援技術を、山岸先生は発音が難しい人のための支援技術を研究・開発しておられるわけですね。そんな研究が音声合成の応用領域をどんどん広げてくれています。人工知能と人間が自然に対話する時代はすぐそこまで来ています。耳障りな声でなく、生身の人間同様に気軽に機械とおしゃべりできるような技術開発を加速していくつもりです。
山岸 HMMを使った音声合成は、世界の音声合成研究者が合成音声の自然さを評価するリスニングコンテストで「人間と同等の明瞭性」を持つと世界で初めて認められました。また、「騒音下では人間の声よりも明瞭に聴き取れる」という評価も得られました。ある意味では人間の声よりも高品質の声を手に入れたことになります。
(取材・文=土肥正弘)
※2 ボイスバンクプロジェクト
音声の障碍患者の生活の質を向上させることを目的に、本人以外の参加者の声を収集する取り組み。声のデータを混ぜ合わせてテンプレートとして利用することで、本人の声による音声合成システムを容易に、素早く構築できる。