
研究背景・目的
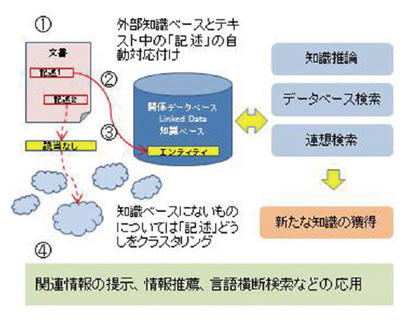
情報社会において日々生産・蓄積される膨大な量のコンテンツを活用するために、AIによる知識処理が切実に求められています。文章から知識を自動獲得する言語処理技術はその中核となるもので、その中で文章中の概念や事物の名前を外部知識に結びつける「エンティティ・リンキング」は、知識獲得に必須の技術として近年注目を集めています。
文章中の名前や語はそれ自体は単なる文字列の並びですが、対応するデータベースのレコードや知識ベース、Wikipediaなどの大規模知識源と結びつけることで、関連情報を的確にユーザに提示したり、データベース演算や知識ベース推論を活用して新たな情報を見つけたりすることが可能になります。また、得られた外部知識を活用して、文章からさらに隠れた知識を発見することも期待できます。
テキストのリンキング技術は、情報検索や情報推薦システムですぐに役に立つ実践的な技術であると同時に、言語や分野を横断する知識発見や、知識ベースどうしの統合を実現するためのグランドチャレンジな研究対象でもあります。
研究内容
- エンティティ記述の抽出
エンティティは、実世界にある事物や共通の固有概念などの対象物です。与えられたテキストを解析して、エンティティを指す文字列を自動抽出します。照応関係や共参照関係の解析などの高度な手法も必要になります。 - 正規化とクリーニング
異体字、区切り文字、長音、文字種の違い等、様々な要因による表記の揺れを吸収するために、正規化ルールの獲得や近似文字列検索などの手法を用いて、自動抽出した用語や辞書をクリーニングします。 - エンティティ同定と用語翻訳
ひとつの記述に対して異なるエンティティの候補が存在する場合に、文脈を考慮した意味処理を適用して、適切な見出し語を見つけたり対訳語を生成したりします。 - TermLink:専門用語リンキングサーバ
リンキングによる知識処理の実現に向けて、知識の体系化に役立つ分野固有概念に焦点をあてて、要素技術の研究に取り組んでいます。実践例として、科学技術文書を対象とするリンキングサーバの開発と、それを利用した論文推薦システムの実装を進めています。
産業応用の可能性
- 日本語の文書から英語の関連文書を捜すなど、言語を横断して情報を検索する
- 文書中の任意の記述からワンクリックで的確な関連情報を入手する
- 多様な情報を統合して信頼性高くマイニングする(新たな知識価値の探索)
- 社内文書とデータベースをリンクすることで、情報共有を容易にする
連絡先
相澤 彰子[コンテンツ科学研究系 教授]
http://researchmap.jp/AkikoAizawa/
aizawa[at]nii.ac.jp ※[at]を@に変換してください
関連リンク
Recommend
さらにみる