
研究背景・目的
異なる場所に存在している同じ意味を表すデータを統一的に扱う問題は「データ相互運用問題」と呼ばれ、データベースの研究分野では古くから継続して取り組まれてきた課題であり、新しい技術や応用とともに発展し続けています。特に近年、生成されるデータはかつてないスピードで増加しており、このような現状から本課題に対する新しい要求とその解決手法が数多く提案されています。データ相互運用では、スキーマの違いを記述しているスキーママッピングを通じて問合せが実行されるため、効率の良い問合せ処理が課題となっています。本研究では、データ相互運用時の問合せの最適化に取り組んでいます。
研究内容
近年、データ相互運用におけるスキーマの統合手法は、データ全体をカバーするスキーマによる統合から、各データピア間のスキーママッピングを利用するP2P(Peer to Peer)に基づく手法(図)へと移行しています。また、Web上での情報交換フォーマットとして、W3C(World Wide Web Consortium)で制定されたXML(Extensible Markup Language)は、例えば、ワードファイルの中身を異なるOS上で共有する時に利用されるなど、日常生活のさまざまな場所で使われています。同様にW3Cで制定されたXMLデータに対する問合せ言語であるXQueryも、さまざまなところで使われています。XML/XQueryの問合せ処理の難しさとして、「順序に関する厳しい制限(heavily ordered)」が指摘されています。このような厳しい制限のもとでも、全てのXQueryエンジンで効率的に問合せが実行できる基盤技術を開発しました。
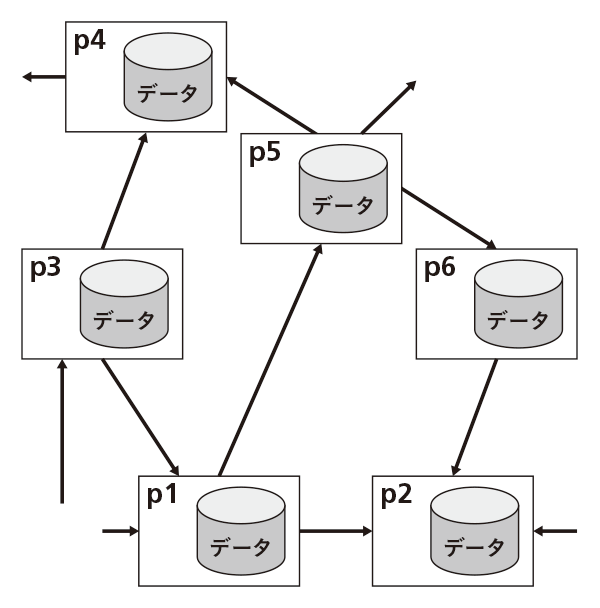
図)P2Pに基づくデータ相互運用の概念図
産業応用の可能性
XQueryを使ったデータ相互運用アプリケーションの高速化や既存のXQueryエンジンの高速化に適用できます。実際、海外のXML/XQueryデータベース企業が本研究の成果に興味を示しており、上記の「順序に関する厳しい制限」についてのパフォーマンスを解析するための分析ツールの提供を、当該企業から受けています。
連絡先
加藤 弘之[コンテンツ科学研究系 助教]
kato[at]nii.ac.jp ※[at]を@に変換してください