 |
Open Archives Initiative Object Reuse and Exchange |
|
Open Archives Initiative Object Reuse and Exchange |
オープン・アーカイブズ・イニシアティブ - オブジェクトの再利用と交換(OAI-ORE)は、Webリソースの集合を記述し、交換するための標準を定義する。本書は、World Wide Webのプロトコルとして現在最も広く使用されているHTTP [RFC2616] を使ったOAI-OREの実装を記述する。様々なシリアライゼーションによる複数のリソースマップ、スプラッシュページ、プロキシURIをサポートするメカニズムが詳述される。
本書は、OAI-ORE仕様書およびユーザガイドを構成する文書の1つである。本書はOREの概念を理解している実装者を想定読者としている。OREを使用する動機およびOREが提供するソルーションについての基本的な理解を得たい読者は [ORE入門] を読まれたい。
1. はじめに
2. 303リダイレクションとコンテントネゴシエーションを使った実装
2.1 複数のリソースマップ
2.2 リソースマップとスプラッシュページ
2.3 推奨するコンテントネゴシエーション動作のまとめ
3. コンテントネゴシエーションがない303リダイレクションを使った実装
4. ハッシュURIを使った簡単な実装
4.1 ハッシュURIから複数リソースマップのサポートへの移行
5. RDFaによる実装
5.1 303リダイレクションを使ったRDFa
5.2 ハッシュURIを使ったRDFa
6. プロキシURI
6.1 HTTPプロキシURIの要件
6.2 http://oreproxy.org/r にあるOREプロキシURIリゾルバ
7. 信用と信頼性
7.1 信頼できる記述
8. 参考文献
A. 謝辞
B. リソースマップとスプラッシュページのための一般的なMIMEタイプ
C. HTTPリクエストとレスポンスの例
C.1 コンテントネゴシエーションがある303リダイレクション
C.2 コンテントネゴシエーションがない303リダイレクション
C.3 ハッシュURIの使用
D. 変更履歴
ORE 集合体とリソースマップの識別にHTTP URIを使用すると、既存のWorld Wide Web [Web Architecture] の豊富なインフラやツールが活用できる。HTTPは、Webブラウザやクローラ、サーチエンジン、フィードアグリゲータなどで最も良くサポートされているプロトコルである。そのため、HTTPは、ORE 集合体とリソースマップのための推奨されるプロトコルであり、関連URIスキームである。
ORE 集合体は、URIで識別される集合リソースの集合 [Data Model] である。集合体は抽象的な構造物であり、その本質的特性はWeb文書として伝達することができない。従って、集合体を識別するURIからその表示形を得ることはできない。しかし、集合体URIは集合体を記述するWeb文書(すわわち、別のURIで入手できるリソースマップ)を得る方法を提供する。本書は、クールなURIとLinked Dataチュートリアルに従うことにより、HTTPを使って集合体とリソースマップをリンク付ける方法を記述する。
ある特定の集合体を記述するリソースマップは1つ以上存在することができる。複数のリソースマップは、そのシリアライゼーションフォーマットやシリアライゼーション固有のメタデータ(作成日時など)が異なると思われるので、異なるURI(ReM-1, ReM-2など)で識別される独立したWeb文書である。
多くのアプリケーションドメインでは、リソースの集合物が既に数多くWeb上に存在する。これらは、通常「スプラッシュページ」と呼ばれる人間が読むことのできるHTMLページで記述されている。スプラッシュページは、http://arxiv.org/abs/astro-ph/0601007 のように、集合物の記述とその構成要素へのアクセスを提供する。一般に、この方法は集合物という概念に対するURIを提供しない。何故なら、スプラッシュページのURIは集合物のURIではなく、HTMLページのURIだからである。また、これは、集合物の機械可読な記述も提供しない。OREは、集合物のURIとリソースマップを用いて集合物の境界を記述する標準的な方法を導入することにより、この問題を解決する。既存のスプラッシュページはOREの集合体URIを通じてアクセスすることができる。RDFaを使うことにより、リソースマップをスプラッシュページの中に埋め込むことも可能であり、これについては本書で取り上げる。
本書は、様々なHTTP実装シナリオを記述するいくつかの節に分かれている。これらのシナリオは、それをサポートするのに必要なサーバ要件とURI構造が異なる。そのため、各節は次のような構成になっている。
http://oreproxy.org/r にあるOREプロキシURIリゾルバの詳細を提供する。本書は、様々なリソースマップに対するコンテントネゴシエーションをサポートする汎用リソース(汎用リソースマップを代理する)の使用に関する手引きは含んでいない。この技法はクールなURI に記述されており、一定の条件下ではOREに利用できる可能性がある。本書の改訂版にはその考察が追加される予定である。
この実装方法は最も柔軟であり、次のような環境で推奨される。
1つの集合体を記述する2つのリソースマップ(AtomシリアライゼーションとRDF/XMLシリアライゼーション)が利用できる場合を考える。各リソースマップは各々異なるURI(ReM-1 と ReM-2)から利用できなければならないが、どちらも集合体URI(A-1)を介してアクセスできるべきである。サーバは A-1 へのリクエストに対して、リクエストで指定されているMIMEタイプの優先度に基づいて、ReM-1 か ReM-2 のいずれかへの 303 See Other リダイレクトで応答する。HTTPのやり取りの例は、付録 C.2に示されている。下の図は、このシナリオにおいて、クライアントの優先度(優先度が指定されていない場合はサーバのデフォルトの処理)に基づいてAtomリソースマップが「勝つ」場合を示している。
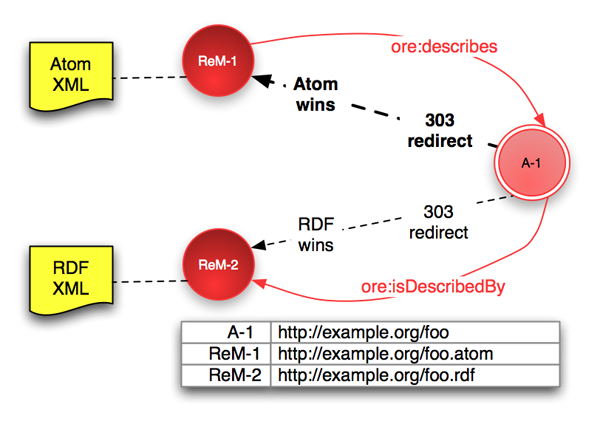
# ReM-1 における表明文(赤の矢印で示されている) ReM-1 ore:describes A-1. A-1 ore:isDescribedBy ReM-2. # ReM-1からReM-2の発見 # ReM-2 における表明文(図には示されていない) ReM-2 ore:describes A-1. A-1 ore:isDescribedBy ReM-1. # ReM-2からReM-1の発見
集合体と各リソースマップは良いURIを持っている。これらのURIは上に示された方法で関連付けられる必要はないが、この関連付けは論理的かつ拡張性のある処置の1つである。与えられたシステムにおける適切な選択は他の要因の影響を受けると思われるが、「良いURIは変わらない」 [URI Style] こと、および、通常システムが進化するにつれ拡張が必要になることを忘れるべきではない。
リソースマップの発見に役立つように、1つの集合体に複数のリソースマップが利用できる場合は、述語 ore:isDescribedBy を使って他のリソースマップが利用できることを示すべきである(上で示されている表明文)。
この仕組みは新規リソースマップの追加(URI ReM-3など)やHTMLスプラッシュページをサポートするために容易に拡張することができる(2.2節)。クライアントから優先度情報が送信されなかった場合や優先するフォーマットが利用できない場合に、どのリソースマップをデフォルトとして考えるかは実装上の判断の問題である。最も広く使用されているシリアライゼーションが最良の選択だと思われるが、現時点ではそれはAtomである。
集合体に関連するHTMLスプラッシュページ(S-1)が存在する場合、303リダイレクションはリソースマップだけでなくスプラッシュページも集合体を介してアクセスできるようにする。従って、クールなURI と Linked Dataチュートリアルの勧告に従うことにより、集合体に関する人間または機械が読むことのできる情報がクライアントの選択に基づいて提供される。
下の図は、HTMLスプラッシュページ(S-1)と2つのリソースマップ(ReM-1 と ReM-2)を持つ集合体を示している。
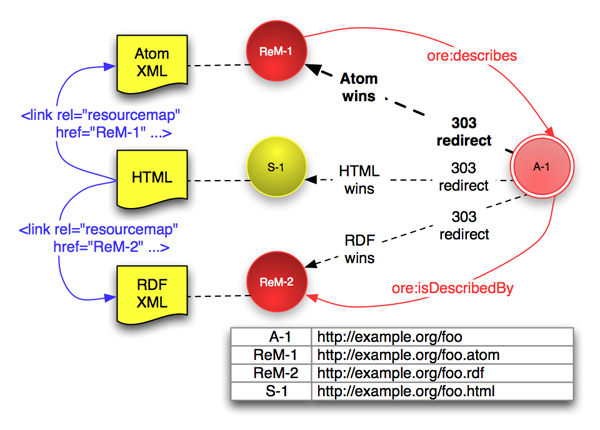
# ReM-1 における表明文(赤の矢印で示されている) ReM-1 ore:describes A-1. A-1 ore:isDescribedBy ReM-2. # ReM-1からReM-2の発見 # ReM-2 における表明文(図には示されていない) ReM-2 ore:describes A-1. A-1 ore:isDescribedBy ReM-1. # ReM-2からReM-1の発見 # S-1内(青い矢印で示されている) <link rel="resourcemap" href="http://example.org/foo.atom" type="application/atom+xml" /> <link rel="resourcemap" href="http://example.org/foo.rdf" type="application/rdf+xml" />
HTMLスプラッシュページは、図に示されているようにリソースマップを発見できるように HTML <link> 要素を含むべきである。また、HTTP Linkヘッダ [Resource Map Discovery] を含むこともできる。さらに、各リソースマップは他のリソースマップを発見できるように述語 ore:isDescribedBy を含むべきである(上で示されている表明文)。スプラッシュページ自体を集合体の集合リソースとするか否かは実装上の判断の問題である。
クライアントがMIMEタイプの優先度を指定していない場合は、デフォルトのリダイレクションはリソースマップにするべきであり、スプラッシュページにするべきではない。どのリソースマップがデフォルトで提供されるかは実装上の判断の問題である。利用可能でもっとも広く利用されているシリアライゼーションが最良の選択だと思われる。
コンテントネゴシエーションの仕様 [RFC2295] は、サーバが「最良の選択肢」を選択できるよう大きな自由度を提供している。OREのクライアントとサーバ間の相互運用性を高めるために、以下の動作が推奨される。HTTPリクエストとレスポンスの例は付録 C.1 に示されている。
以下の規則により、コンテントネゴシエーションによる303リダイレクションは高度なOREクライアントに柔軟性を提供することができる。また、優先度を示す(Accept)ヘッダを提供しないクライアントもリソースマップが使用できるようになる。集合体URIへのリクエストに対するレスポンスにおいて、
Accept ヘッダを含んでいる場合は、その優先度に従うよう努める(HTMLがリクエストされた場合は任意のスプラッシュページを含む)。サーバがリクエストされた(またはより優先度の低い)フォーマットにリダイレクトできない場合は、機械可読のリソースマップ(RDF/XML、Atom、RDFa)にリダイレクトする。Accept ヘッダを含んでいない場合は、機械可読のリソースマップ(RDF/XML、Atom、XHTML+RDFa)にリダイレクトする。サーバが上の規則に従う場合、優先度情報なしに集合体URIをリクエストするとクライアントは機械可読のリソースマップを受け取ることになる。
Accept ヘッダを含めることが推奨される。この実装方法は次の場合に推奨される。
集合体を記述するリソースマップが1つだけの単純な場合、または、技術的な理由でコンテントネゴシエーションが利用できない場合は、コンテントネゴシエーションがない303リダイレクションを使用できる。次のような1つのリソースマップ(ReM-1)で記述されている集合体(A-1)の例を考える。
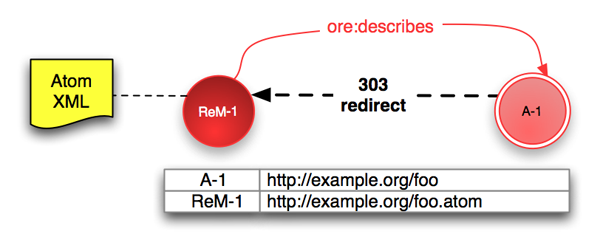
URI A-1 を持つ集合体がリソースマップ ReM-1 で記述されている。A-1 へのアクセスは利用者またはエージェントをリソースマップに導くべきであり、これはHTTPリダイレクションにより実行される。サーバは A-1 へのリクエストに対して ReM-1 へリダイレクトする 303 See Other で応答する。HTTPのやり取りの例は付録 C.2に示されている。
URI A-1 と ReM-1は上に示された方法で関連付けられる必要はないが、この関連付けは論理的かつ拡張性のある処置の1つである。与えられたシステムにおける適切な選択は他の要因の影響を受けると思われるが、「良いURIは変わらない」 [URI Style] こと、および、通常システムが進化するにつれ拡張が必要になることを忘れるべきではない。
この単純な1つだけのリソースマップの303リダイレクション処理は、リソースマップの追加やスプラッシュページに対応のために、コンテントネゴシエーションがある303リダイレクションを使うことにより簡単に拡張することができる(2節)。リソースマップの追加に対応するためにURIのパターンを拡張することができる。RDF/XML ReM-2 とスプラッシュページ S-1 の追加には、次のURIが使用できるだろう。
集合体: A-1 = http://example.org/foo
リソースマップ: ReM-1 = http://example.org/foo.atom
ReM-2 = http://example.org/foo.rdf
スプラッシュページ: S-1 = http://example.org/foo.html
たとえコンテントネゴシエーションのサポートがなくても、他のリソースマップへリンクするために各リソースマップに述語 ore:isDescribedBy を含めたり、スプラッシュページに HTML <link> 要素を含めたりすることにより、クライアントに他のリソースマップを知らせることができる。完全なコンテントネゴシエーションによるソルーションに比べて制限は多いが、この処理は集合体へのアクセスにより集合体を記述するリソースマップへクライアントを導くという最低限度の要求を満たすものである。
この実装方法は次の場合に推奨される。
Webサーバのサポートなしには、303リダイレクションを使って集合体へのアクセスをリソースマップに導くことはできない。この制約を回避する方法が、ハッシュURIの使用である。ハッシュURIでは、集合体のURIはリソースマップのURIにフラグメント識別子を追加することにより作成される [RFC3986]。Atomリソースマップの場合、そのURIは次のようになるだろう。
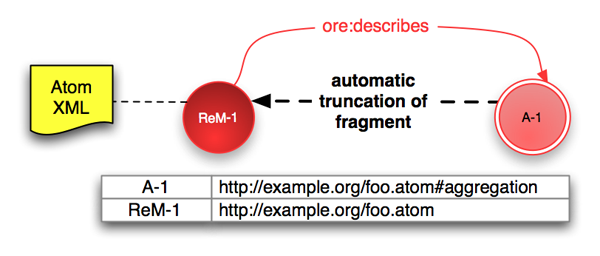
# ReM-1 における表明文(赤の矢印で示されている) ReM-1 ore:describes A-1.
フラグメント識別子の解決はクライアント側の処理である。そのため、フラグメント識別子を持つHTTP URI(例えば、uri#fragment)を見たクライアントはすべて #fragment をはずして uri にアクセスする。そして、レスポンスが得られた場合のみ、クライアントは正しいフラグメントの識別を試みることになる。これは、実際上、上の A-1 と ReM-1 はどちらも http://example.org/foo.atom にあるリソースマップを与えることを意味する。集合体など、実在のリソースを識別するためにフラグメント識別子を持つURIを使用することは クールなURIとLinked Dataチュートリアルでさらに詳しく検討されている。
ハッシュURIを使用すればリソースマップと集合体を明確に区別することができるので、しかるべきリソースについて表明文を作成することができる。また、集合体のURI A-1 経由でも、直接 ReM-1 からでもリソースマップを得ることができるという要件も満たしている。この例についての非常に簡単なHTTPのやり取りが付録 C.3に示されている。
集合体に関連するHTMLスプラッシュページ(S-1)がある場合は、リソースマップを発見できるようにするために、スプラッシュページは以下のように HTML <link> 要素を含むべきである。また、HTTP Link ヘッダを含むこともできる [Resource Map Discovery]。
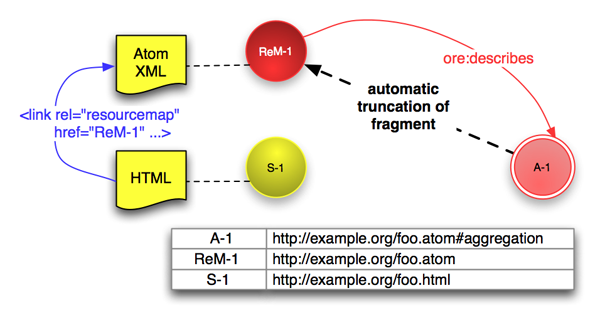
# ReM-1 における表明文(赤の矢印で示されている) ReM-1 ore:describes A-1. # S-1内(青い矢印で示されている) <link rel="alternate" href="http://example.org/foo.atom" type="application/atom+xml" />
集合体URIとしてハッシュURIを使用すると、そのままでは1つの集合体に対して複数のリソースマップを利用することができない。この簡単な方法から複数のシリアライゼーションを持つより複雑なソルーションへの移行は、以下に述べる2つの方法で実現することができる。両者とも不完全な妥協策であるので、実装者にはハッシュURIの方法を選択する前に将来の拡張可能性を検討するよう警告する。
303リダイレクションによる方法を採用するためにURIを変更する。元々存在するリソースマップのURI http://example.org/foo.atom は変更する必要がない。追加のリソースマップは新規URI(例えば、RDF/XMLリソースマップが http://example.org/foo.rdf )に追加され、次のようなURIの集合となる。
集合体: A-1 = http://example.org/foo
リソースマップ: ReM-1 = http://example.org/foo.atom
ReM-2 = http://example.org/foo.rdf
この新たなURIの割振りにおいても、集合体の旧URI http://example.org/foo.atom#aggregation へのアクセスを試みるクライアントは依然としてリソースマップを見つけることになる。十分に賢いクライアントは、リソース http://example.org/foo.atom#aggregation に関する記述が存在しないという矛盾を発見できるかもしれない。しかし、リソースマップを更新して http://example.org/foo と http://example.org/foo.atom#aggregation が同一のリソースを特定しているという表明文を含めることにより、処理は明確になるだろう。
<http://example.org/foo> owl:sameAs <http://example.org/foo.atom#aggregation>.
既存のURIには手を付けずに、他のフォーマットを追加する。新たにRDF/XMLリソースマップが http://example.org/foo.rdf に追加されると、URIの集合は次のようになる。
集合体: A-1 = http://example.org/foo.atom#aggregation
リソースマップ: ReM-1 = http://example.org/foo.atom
ReM-2 = http://example.org/foo.rdf
この拡張では、 A-1に対するコンテントネゴシエーションにより複数のリソースマップへのアクセスを提供したり、A-1を介して得られるデフォルトの表示形を変更したりすることはできない。各リソースマップが述語 ore:isDescribedBy を使って他のリソースマップが利用できることを示すことになる。スプラッシュページはリソースマップを発見できるようにHTML <link> 要素を含むことになる。また、HTTP Link ヘッダを含むこともできる。
RDFa は、リソースマップなどの構造化されたデータをXHTMLページに埋め込む方法を提供する。リソースマップのシリアル化にRDFaを使用するためのプロファイルは、RDFaによるリソースマップの実装に示されている。RDFaを埋め込むことにより、(X)HTML「スプラッシュページ」はリソースマップシリアライゼーションの2つの役割を担うことができる。同じ方法をマイクロフォーマットを使って行うこともできるだろう。
OREモデルでは、すべてのリソースマップのURI(ReM-1, ReM-2など)は集合体のURI(A-1)とは異なっていなければならない。同様に、スプラッシュページのURI(S-1)は集合体のURIとは異なっていなければならない。303リダイレクションを使ったRDFaの使用法を 5.1節で、ハッシュURIを使ったRDFaの使用法を 5.2節で説明する。
303リダイレクションを使った実装の場合、RDFaを含む(X)HTMLページは他のすべてのファーマットのリソースマップと同じ方法で扱うことができる。XHTMLページが集合体のただ1つのリソースマップシリアライゼーションを含んでいる場合は、次のURIを持つだろう。
集合体: A-1 = http://example.org/foo リソースマップ: ReM-1 = http://example.org/foo.html (RDFaリソースマップを含んでいる)
ここで、 A-1 へのリクエストに対して、サーバは3節で述べたように ReM-1 への303リダイレクションで応答する。
複数のシリアライゼーションが存在する場合は、デフォルトの303リダイレクトはXHTMLページに向けられるべきである。これはデフォルトのリダイレクトは機械可読のリソースマップへという要件を満たすだけでなく、Webブラウザがリソースマップの最も役に立つバージョン、すなわち、人間が読むことのできるXHTMLページに埋め込まれたバージョンを受け取ることを保証することにもなる。HTTPリクエストで優先度情報が提供された場合は、サーバはコンテントネゴシエーションを行って最も適したリソースマップを提供することができる。XHTML+RDFaとAtomのリソースマップが利用できる場合、URIは次のようになるだろう。
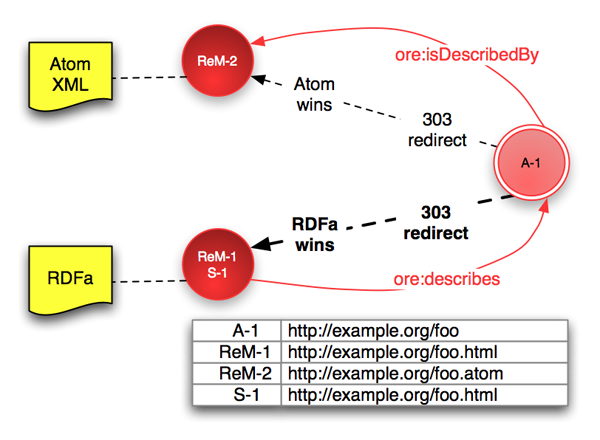
# ReM-1 == S-1 における表明文(赤の矢印で示されている) ReM-1 ore:describes A-1. A-1 ore:isDescribedBy ReM-2. # ReM-1からReM-2の発見
この仕組みは、新規リソースマップにURI ReM-3 (例えば、RDF/XMLに http://example.org/foo.rdf )を追加するだけで、リソースマップの追加に容易に拡張できる。
ハッシュURIを使った簡単な実装の場合、RDFaによるリソースマップのシリアライゼーションを含むXHTMLページは次の集合体URI A-1 を持たなければならない。
集合体: A-1 = http://example.org/foo.html#aggregation リソースマップ: ReM-1 = http://example.org/foo.html
このURIが表明文で使用できるようにRDFaデータが書かれなければならない。集合体URIは http://example.org/foo.html#aggregation であり、ページURI http://example.org/foo.htmlではない。これは RDFaユーザガイド [RDFa Resource Maps] に詳しく記述されている。
OREモデル [Data Model] は、集合リソースのための集合体特有の識別子を定めるプロキシURIを導入している。モデル化の観点からは、プロキシURIは特定の集合体と特定の集合リソースに対して一意でありさえすればよく、適当な述語(ore:proxyIn、または ore:proxyFor)で示されるこれらとの結合関係を持つ。同一の集合体を記述するすべての正規リソースマップは集合リソースに対して同一のプロキシURIを表現しなければならない([Data Model] の3.3節)。HTTPを使って実装された場合、プロキシURIを逆参照するクライアントが集合リソースにリダイレクトされると同時に集合体コンテキストを知らされるよう、プロキシURIは下で示す追加の要件を満たすべきである。この情報をレスポンスで伝達するにはサーバのサポートが必要である。
OREプロキシURIリゾルバは、ローカルサーバのサポートや登録手続きを必要とせずにプロキシURIを実装する方法を提供する。プロキシURIは、対象となる集合リソースURIとコンテキストとなる集合体URIの両者を含むリゾルバへのクエリとして構成される。
プロキシURIは特定の集合体(A-1)と特定の集合リソース(AR-1)に対して一意でなければならない。これにより、プロキシURIは特定の集合体のコンテキストにおける集合リソースを「代理する」ことができる。ある集合体のコンテキストにある集合リソースの参照としてHTTPプロキシURIが使用される場合、標準的なWebブラウザが逆参照した際に集合リソース自身(JPEG画像やPDF文書など)が返されることが望ましい。さらに、ORE対応のクライアントやエージェントがプロキシURIを逆参照した場合は、集合体のコンテキストが明らかになるべきである。これら2つの要件を満たすために、逆参照された際に、HTTPプロキシURIは以下を実行しなければならない。
HTTPステータスコード "303 See Other" (他の 3xx コードは正しいセマンティクスを持たない)と次のLocation ヘッダを付けて、集合リソースへクライアントをリダイレクする。
Location: AR-1
aggregation 関係に型付けされた次の HTTP Linkヘッダを付けて、HTTPレスポンスにおいて集合体のコンテキストを示す。
Link: <A-1>; rel="aggregation"
OREプロキシURIリゾルバは、これらの要件を満たす実装の1つである。以下に記述されるこのリゾルバ特有の構文は別の基底URIを持つ他のプロキシURIリゾルバにも再利用することができるだろう。どんな構文を使うにせよ、実装者は以下で示されるURIエンコーディングの問題に注意を払うべきである。
http://oreproxy.org/r にあるOREプロキシURIリゾルバhttp://oreproxy.org/r にあるOREプロキシURIリゾルバは、このコミュニティに対するサービスとして提供されている。http://oreproxy.org/r リゾルバの使用には、プロキシURIがここで述べる構文規則に従って構成されていることだけが要求される。新たなプロキシURIやリソースマップ、集合体を登録する必要はない。何故なら、上で示されたプロキシURIの要件を実装するために必要な情報、すなわち、集合リソースのURI AR-1 とコンテキストである集合体のURI A-1 は、すべてプロキシURI自体に含まれているからである。プロキシURIの構文は次のとおりである。
http://oreproxy.org/r?what=AR-1&where=A-1
実例は次のようになるだろう。
http://oreproxy.org/r?what=http://example.org/aggregated_resource_456&where=http://example.org/aggregation_123
プロキシURIは次の規則に従って構成される。
what と where は示された順に与えられなければならない。集合リソースのURI AR-1 と集合体のURI A-1 は、プロキシURIのクエリ要素の一部として適切にURIエンコードされなければならない。プロキシURIで使用される場合、A-1 と AR-1 に含まれる以下を除いたすべての文字はパーセントエンコーディングされるべきである(URI構文仕様書 [RFC3986] を参照)。
query-non-escaped = ALPHA / DIGIT / "-" / "." / "_" / "~" / ":" / "@" / "/" / "?"
これは、A-1 または AR-1 でパーセントエンコードされた文字を示すために既に使用されているすべての % 文字を二重にエスケープしなければならないことを意味することに注意されたい。例えば、AR-1=http://example.org/aggregated%26resource、A-1=http://example.org/aggregation_123 の場合、%26 の % は %25 としてエンコードされなければならない。その結果、次のようになる。
http://oreproxy.org/r?what=http://example.org/aggregated%2526resource&where=http://example.org/aggregation_123
また、A-1 と AR-1 のいずれかがフラグメント識別子を含んでいる場合は、# 文字を正しくエスケープ(%23)することが重要であることにも注意されたい。そうしないと、ブラウザは # 文字をクエリ文字列の終端だと解釈してプロキシURIの残りの部分をリゾルバに送信しないことになるだろう。
プロキシURIを作成するアプリケーションとリゾルバを除いたすべてのアプリケーションはプロキシURIをopaqueとして扱うべきである。パラメタ順、統一的エスケープ処理、正規化の3つの規則は、同一の AR-1 と A-1 に対しては、アプリケーションが異なっても同一のプロキシURIが作成されること、従って、プロキシURIはURIの比較により同一リソースの識別ができると理解されることを意味する。
クライアントが http://oreproxy.org/r プロキシURIを逆参照すると、上のプロキシURI要件で述べたように、集合リソース AR-1 にリダイレクトされ、集合体のコンテキストがHTTP Link ヘッダで示される。普通のWebブラウザのようにLink ヘッダを解釈できない、または、解釈しないクライアントは黙って集合リソースにリダイレクトされることになる。そして、ORE対応のクライアントは集合体のコンテキストを推測することができることになる。
信用という概念は周知のように複雑であり築くことは難しいが、多くのアプリケーションにとって重要なものである。OREの仕様は、アプリケーションが信用を築くための足がかりとなる権威ある規則を提供するWebとセマンティックWebの標準に基づいている。具体的に言えば、OREモデルは誰もが何についても何でも言うことができるRDFを使用している。誰が、あるいは何をしているのか、言っているのかを理解することは人が信用を築けるかどうかに関係するからである。本節は、集合体とリソースマップのURIに基づく信頼性判断の要素を概説する。
集合体のURIが与えられたと仮定する。その集合体を記述している正規リソースマップをいかに見つけることができるか。Webアーキテクチャは、URIで識別されるリソースの信頼できる記述を提供することはURI所有者に依存している([Web Architecture] と [Linked Data Tutorial] の URIの割当を参照)。OREの仕様はこの考えに従っている。集合体のURIを逆参照すると(上に述べた方法の1つを通じて)正規リソースマップに導かれることが期待される。従って、集合体URIを通じて得られるリソースマップは、集合体の信頼できる記述であると考えられる [ORE Data Model]。
正規リソースマップであっても別の意味では信頼できない表明文を含む場合があることに注意されたい。例えば、ある集合リソースがJPEG画像であると記述されていても、その集合リソースを逆参照するとPDF文書の信頼できる表示形やHTTPメタデータに導かれる場合がある。
本書は、オープン・アーカイブズ・イニシアティブの成果である。OAIオブジェクトの再利用と交換プロジェクトは、アンドリュー・W・メロン財団、Microsoft社、全米科学財団から助成していただいた。さらに、ネットワーク情報連合からもご支援をいただいた。
本書は、OAI-ORE技術委員会(ORE-TC)の会議に基づいている。会議にはOAI-OREリエゾングループ(ORE-LG)も参加している。ORE-TCの委員は、次のとおりである。Chris Bizer(ベルリン自由大学)、Les Carr(サウサンプトン大学)、Tim DiLauro(ジョンホプキンス大学)、Leigh Dodds(Ingenta)、David Fulker(UCAR)、Tony Hammond(Nature出版グループ)、Pete Johnston(Eduserv財団)、Richard Jones(インペリアル・カレッジ)、Peter Murray(OhioLINK)、Michael Nelson(オールドドミニオン大学)、Ray Plante(NCSAおよび国立仮想天文台)、Rob Sanderson(リバプール大学)、Simeon Warner(コーネル大学)、Jeff Young(OCLC)。ORE-LGの委員は次のとおりである。Leonardo Candela(DRIVER)、Tim Cole(DLF AquiferおよびUIUC図書館)、Julie Allinson(JISC)、Jane Hunter(DEST)、Savas Parastatidis(Microsoft)、Sandy Payette(Fedora Commons)、Thomas Place(DAREおよびティルブルグ大学)、Andy Powell(DCMI)、Robert Tansley(Google, Inc.およびDSpace)。
また、OAI-ORE諮問委員会(ORE-AC)の意見にも感謝する。
下の表は、リソースマップのシリアライゼーションに使用できる標準的なMIMEタイプ [IANA MIME] の一覧である。サーバ設定に関する特別な知識を必要とすることなく、クライアントがHTTPのAccept: ヘッダを使って適切なフォーマットをリクエストできるように、OREリソースマップを提供するサーバはこれらの標準に従うべきである。
| リソースマップの種類 | MIMEタイプ |
|---|---|
| Atom | application/atom+xml |
| RDF/XML | application/rdf+xml |
| RDFa in XHTML | application/xhtml+xml |
これにより、RDF/XMLが望ましいがAtomも解析できるクライアントはリクエストに次のようなHTTPヘッダを使用することになるだろう。
Accept: application/rdf+xml, application/atom+xml;q=0.5
下の表は、W3C XHTMLメディアタイプ勧告に従ったHTMLまたはXHTMLのスプラッシュページに使用できる2つの一般的なMIMEタイプの一覧である。
| リソースマップの種類 | MIMEタイプ |
|---|---|
| XHTML | application/xhtml+xml |
| HTML(レガシー) | text/html |
これにより、集合体URIからスプラッシュページを受け取りたいが、HTMLよりXHTMLが望ましいクライアントは、リクエストに次のようなHTTP ヘッダを使用することになるだろう。
Accept: application/xhtml+xml, text/html;q=0.5
残念ながらMIMEタイプに基づいて普通のXHTML文書とXHTML+RDFa文書を区別する方法は存在しないことに注意されたい。従って、サーバがレスポンスにおいて(RDFaを持たない)普通のXHTMLスプラッシュページを正しく返すかもしれないというリスクを冒すことなく、クライアントがRDF/XMLやAtomのリソースマップに優先してXHTML+RDFaのリソースマップをリクエストすることはできない。
ここでは、本書で示した実装方法におけるHTTPリクエストとレスポンスの単純化したやり取りを示す。HTTPレスポンスは通常、ここでは動作を明確に示すために省略した他のヘッダを数多く含んでいる(Date, Server, Conectionなど)。
サーバが集合体URIに関するコンテントネゴシエーションをサポートしている場合は、クライアントはリクエストで示した優先度に従って異なるリソースマップへリダイレクトされる。優先度が指定されていない場合は、集合体 http://example.org/foo に対するリクエストとレスポンスのやり取りはコンテントネゴシエーションを行わない例 C.2で示されるものと同じになる。しかし、ここでは下のようにクライアントがRDFを優先することを示した(MIMEタイプ application/rdf+xml には q=1.0 と application/atom+xml の q=0.5 より大きい値を仮定した)場合を考える。
(リクエスト) GET /foo HTTP/1.1
Host: example.org
Accept: application/rdf+xml, application/atom+xml;q=0.5
(レスポンス) HTTP/1.1 303 See Other
Location: http://example.org/foo.rdf
Vary: Accept
レスポンスは、Atomによるシリアライゼーションではなく、RDFによるリソースマップ http://example.org/foo.rdf への303リダイレクトである(その他の 3xx ステータスコードは正しいセマンティクスを持たないことに注意されたい)。
レスポンスの Vary ヘッダはリクエストの Accept ヘッダに基づいてコンテントネゴシエーションが行われたことを示している。これはキャッシュが正しく動作するために必要である。
クライアントは303リダイレクトを理解し、示されたリソースをリクエストすることになる。
(リクエスト) GET /foo.rdf HTTP/1.1
Host: example.org
(レスポンス) HTTP/1.1 200 OK
Content-Type: application/rdf+xml
Length: 2345
<?xml version="1.0" encoding="UTF-8"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ore="http://www.openarchives.org/ore/terms/">
...
</rdf:RDF>
この場合、RDF/XMLによるリソースマップを 200 OK のレスポンスで与えている。
2つ目の例として、XHTML(application/xhtml+xml)とHTML(text/html)を Acceptヘッダに設定することによりクライアントがスプラッシュページを優先することを示した場合を考える。
(リクエスト) GET /foo HTTP/1.1
Host: example.org
Accept: application/xhtml+xml, text/html;q=0.5
(レスポンス) HTTP/1.1 303 See Other
Location: http://example.org/foo.html
Vary: Accept
レスポンスはHTMLのスプラッシュページへの 303リダイレクトである。集合体 http://example.org/foo のためのHTMLスプラッシュページがなかった場合は、その代りにレスポンスはデフォルトのリソースマップ、例えば、RDF/XMLへリダイレクトすることになる。
(リクエスト) GET /foo HTTP/1.1
Host: example.org
Accept: application/xhtml+xml, text/html;q=0.5
(レスポンス) HTTP/1.1 303 See Other
Location: http://example.org/foo.rdf
Vary: Accept
利用できるリソースマップが1つしかない場合、あるいは、複数のリソースマップが利用できるがサーバがコンテントネゴシエーションをサポートしていない場合、または、クライアントが優先度を指定しない場合の 303リダイレクションでは、303リダイレクションによる単純なリクエストとレスポンスのやり取りになる。集合体 http://example.org/foo へのリクエストを考える。
(リクエスト) GET /foo HTTP/1.1
Host: example.org
(レスポンス) HTTP/1.1 303 See Other
Location: http://example.org/foo.atom
クライアントは303リダイレクトを理解し、示されたリソースをリクエストすることになる。
(リクエスト) GET /foo.atom HTTP/1.1
Host: example.org
(レスポンス) HTTP/1.1 200 OK
Content-Type: application/atom+xml
Length: 1234
<?xml version="1.0" encoding="UTF-8"?>
<entry xmlns="http://www.w3.org/2005/Atom">
...
</entry>
レスポンスヘッダ 200 OK は、リクエストされたリソースがWeb文書であり、レスポンスのボディがAtomのリソースマップであることを示している。
集合体 URIが http://example.org/foo.atom#aggregation のようにフラグメント識別子を持つハッシュURIである場合は、ブラウザ(または他のクライアント)は URIを #(ハッシュ)の位置で自動的に切り詰めて、通常の方法でリソース http://example.org/foo.atom に対するリクエストを発行することになる。従って、HTTPリクエストとレスポンスのやり取りは非常に単純であり、リソースマップは 200 OK レスポンスで返される。
(リクエスト) GET /foo.atom HTTP/1.1
Host: example.org
(レスポンス) HTTP/1.1 200 OK
Content-Type: application/atom+xml
Length: 1234
<?xml version="1.0" encoding="UTF-8"?>
<entry xmlns="http://www.w3.org/2005/Atom">
...
</entry>
