
研究背景・目的
現在、本人の意思によらず音声が収集され、ウェブ上で共有されています。もし最先端の話者認識技術が悪用された場合、収集された音声から発声者が誰であるか、個人を特定することが可能であると言われています。この様なプライバシーの侵害は、深刻な社会問題になると危惧されています。本研究は、人間の自然な会話を阻害することなく、話者照合システムの精度を低下させる新しい個人用防御音を開発することによって、プライバシー守ることを目指しています。
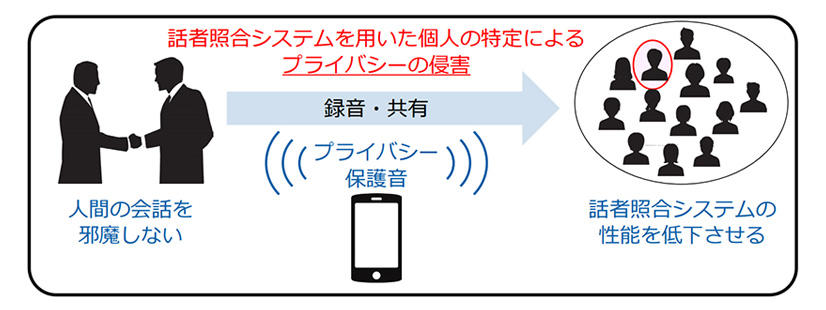
研究内容
情報通信基盤の高度化と携帯デバイスの普及により、動画や写真の撮影、音声録音が、いつでもどこでも可能となり、第三者が簡単に、そして無許可にインターネット上で共有できてしまう状況です。加えて、音声から発声者を特定する話者照合・話者認識の技術も高度化しており、無作為に収集された音声から個人が特定されてしまうという、プライバシーの侵害も表出しつつあります。
本研究では、特殊な雑音を実環境で生成させることで、話者照合・話者認識システムから識別されにくくするという新しいプライバシー保護技術を開発しています。無許可に録音や共有をされても、話者照合システムの性能を低下できるよう話者情報を強く包含している周波数を隠す「プライバシー保護音」を発生させるというアプローチです。
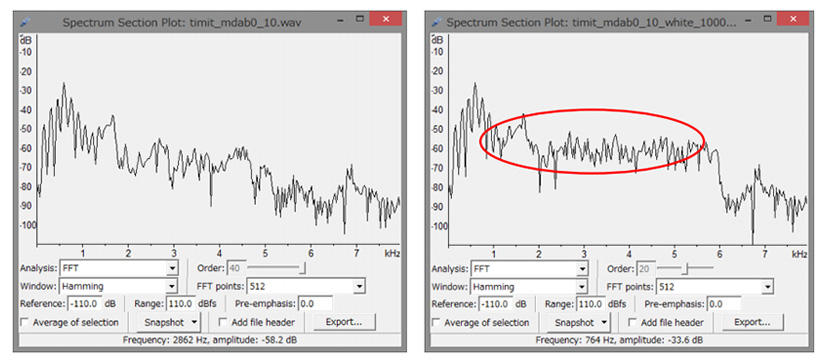
プライバシー保護音の例: 周波数軸上で部分的に隠す音
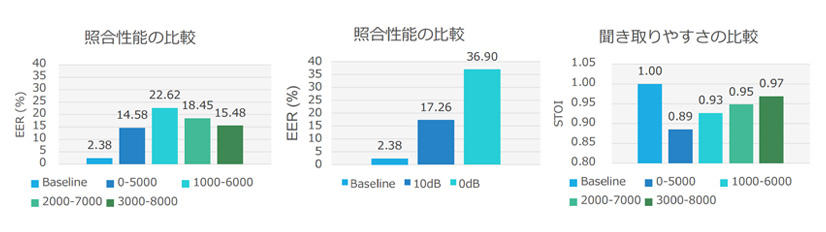
プライバシー保護音の比較実験
比較実験では、図のように、1,000~6,000Hzという中域・高域にノイズを加えると、最も話者照合の性能を低下させることができるということがわかりました。音声の言語情報は、通常、低域周波数に情報が集中しているので、このようなノイズを加えても発話内容の聞き取りやすさにはあまり影響しないということもわかりました。また、SNR(Speech-to-Noise Ratio) が小さいほど話者照合性能を低下させるということもわかりましたが、同時に、雑音は耳障りな音になっていきます。この雑音の不快感の対処が、今後の課題です。
産業応用の可能性
- 自動話者照合システムの普及は広がっており、導入コストも安価になりつつあります。
- 音声から個人が特定されては困る場所への導入などが期待されます。
連絡先
山岸 順一[コンテンツ科学研究系 准教授]
jyamagis[at]nii.ac.jp ※[at]を@に変換してください