研究 / Research
コンテンツ科学研究系
 山岸 順一
山岸 順一YAMAGISHI Junichi
コンテンツ科学研究系 教授
研究紹介
個人の音声や映像を合成する技術とセキュリティとの両立をめざして
個人の音声の合成技術を世界に先駆けて研究
コンピュータを使ってテキストから音声を合成する技術は、50年以上の歴史があります。私は2000年代の初め、機械的な音声ではなく、人間の声、それもある特定の個人の音声をつくる研究を世界に先駆けて行いました。その後はこの技術を応用し、舌にセンサーをつけて、舌の特徴的な動きからその人の音声をつくる研究や、個人の声を使った音声翻訳、雑音下でも個人の声を明瞭に聞き分けられる技術などを開発しました。医療面では、声を失ったALS(筋萎縮性側索硬化症)の方の会話のサポート技術を手がけました。
最近は、人を楽しませる技術も開発してみたいと考えて、古典落語を得意とする真打、柳家三三さんの演目を録音して機械学習させ、新しい小話の音声合成をしました。今後は本格的な落語にも挑戦してみたいです。
なりすましを防ぎ、プライバシーを守る
個人の特性や生体情報をデジタル化して複製する技術(デジタルクローン技術)は、音声に限らず、画像や映像、文章などでも可能です。最近では機械学習の進化により、人間には本物とクローンの区別ができないレベルに到達しています。
残念なことに、この精巧な技術を悪用すれば、本人になりすまして音声認証を突破したり、本人と区別のつかないオレオレ詐欺の電話をかけたりすることができます。私は、2013年にNIIに移ってからは、セキュリティやプライバシーを守るための研究も本格的に手がけてきました。デジタルクローン技術と、セキュリティを両立させるような新しい枠組みをつくりたいと考えたのです。
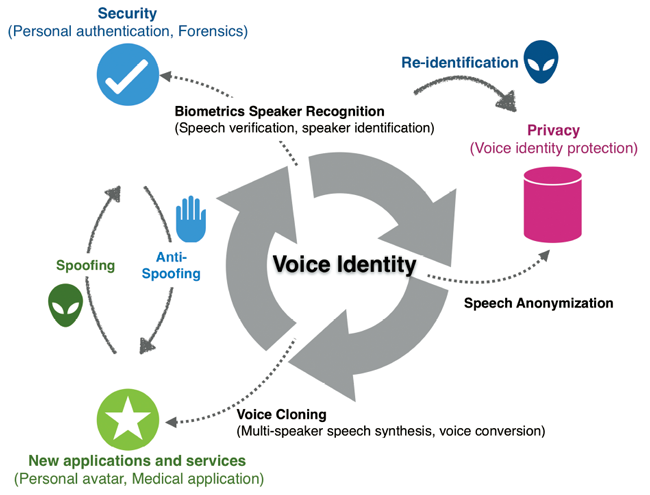
2015年から隔年で開催している人間の声と機械の合成音声とを見分ける国際コンペティション※にはGoogle、NTT、HOYAなど世界的な企業が協力しています。さらに現在はFacebookやMicrosoftがフェイク映像に関するチャレンジの開催を検討しており、世界規模でのデータの共有が実現しつつあります。
音声だけでなく、映像であるフェイクビデオの検出や、テキストであるサイトの口コミの真贋判定なども必要とされますが、これらも同様に機械学習の方法を使うことができます。
この精巧さを逆に応用すれば、プライバシーの保護にも役立ちます。あえてあまり精巧でない複製をつくる、つまり個人の特性を100%再現せずに少しぼかすことにより、個人が特定できなくなるからです。今後膨大な数の個人情報がサイバー空間でやりとりをされるようになったとき、必要とされる技術になるでしょう。
説明可能なAIの必要性
このようなシステム側だけのセキュリティ対策には限界があります。やはり情報の受発信にかかわる一人ひとりが、安全なメディア活用のための知識と意識をもつ必要があり、そのためには「メディアリテラシー」を整備して共有する必要があると思います。
今後のシステム側の課題は、真贋判定の結果を示すときに、その根拠をどのように示すかということです。「この映像はフェイクです」という情報に接したとき、その情報自体がフェイクの可能性もあるわけです。機械学習による判定では、「なぜフェイクなのか」を説明することが難しいのですが、これを説明できるAIの開発は、これからのトピックだと考えています。
※ Automatic Speaker Verification Spoofing and Countermeasures Challenge
関連情報
AIスピーカーとディープラーニング - 山岸 順一 - 第9回 国立情報学研究所 湘南会議 記念講演会
リンク
- [NII Today]フェイクメディアを自動判定 「シンセティックビジョン」 (100-4)
- [NII Today]雑踏の中でも聞きやすい音声合成を社会実装 (100-6)
- [NII SEEDS] 改ざん領域を特定し判断根拠示すフェイクメディアの自動検知技術
- [NII Today] 世界の研究者とチームを組んで 増え続けるフェイク情報と闘う - NII Interview (85-1)
- [NII SEEDS] 機械学習により生成された巧妙なフェイク動画を自動検知する技術
- [研究者クローズアップ] 「音」への関心が変える未来
- [NII SEEDS] 「賢い」音声合成による次世代音声情報処理技術の開拓
- [NII SEEDS] 個人が特定されにくいプライバシー保護音
- 「賢い」音声合成による次世代音声情報処理 - 山岸 順一 - NII研究100連発 オープンハウス2017
- 平成27年度市民講座 第1回 :「おしゃべりなコンピュータ ~音声合成技術の現在と未来~」
- [書籍] おしゃべりなコンピュータ―音声合成技術の現在と未来 - 情報研シリーズ19
注目コンテンツ / SPECIAL
 学術情報基盤オープンフォーラム 2024
学術情報基盤オープンフォーラム 2024
 NII Today No.102
NII Today No.102
 SINETStream 事例紹介:トレーラー型動物施設 [徳島大学 バイオイノベーション研究所]
SINETStream 事例紹介:トレーラー型動物施設 [徳島大学 バイオイノベーション研究所]
 ウェブサイト「軽井沢土曜懇話会アーカイブス」を公開
ウェブサイト「軽井沢土曜懇話会アーカイブス」を公開
 情報研シリーズ これからの「ソフトウェアづくり」との向き合い方
情報研シリーズ これからの「ソフトウェアづくり」との向き合い方
 学術研究プラットフォーム紹介動画
学術研究プラットフォーム紹介動画
 教育機関DXシンポ
教育機関DXシンポ
 学術情報基盤オープンフォーラム 2023
学術情報基盤オープンフォーラム 2023
 国立情報学研究所 2023年度 概要
国立情報学研究所 2023年度 概要
 高等教育機関におけるセキュリティポリシー
高等教育機関におけるセキュリティポリシー
 情報・システム研究機構におけるLGBTQを尊重する基本理念
情報・システム研究機構におけるLGBTQを尊重する基本理念
 オープンサイエンスのためのデータ管理基盤ハンドブック
オープンサイエンスのためのデータ管理基盤ハンドブック
 教育機関DXシンポ
教育機関DXシンポアーカイブス
 コンピュータサイエンスパーク
コンピュータサイエンスパーク